内存分配:


cudaMemcpy 进行主机与设备端的数据内存交换。
CUDA程序的处理流程:
- 从CPU拷贝数据到GPU。
- 调用kernel来操作存储在GPU的数据。
- 将操作结果从GPU拷贝至CPU。
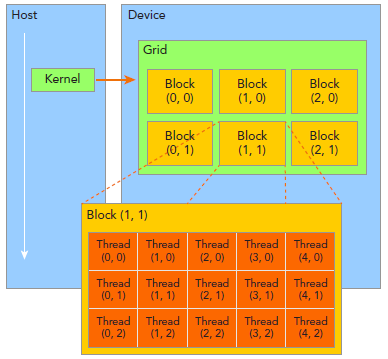
CUDA线程分成Grid和Block两个层次:
由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。一个grid由许多block组成,block由许多线程组成,grid和block都可以是一维二维或者三维,上图是一个二维grid和二维block。
__global__ 、__device__、__host__ 修饰:
__global__ 函数运行在device上,可被host和device函数调用,必须返回void;
__device__ 函数运行在device上,只可被device函数调用;
__host__ 函数运行在host上,只可被host函数调用;
线程索引:
在kernel里,线程的唯一索引非常有用,为了确定一个线程的索引,我们以2D为例:
- 线程和block索引
- 矩阵中元素坐标
- 线性global memory 的偏移
首先可以将thread和block索引映射到矩阵坐标:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y

询和管理GPU device:
查询所有关于GPU device 的信息
cudaError_t cudaGetDeviceProperties(cudaDeviceProp *prop, int device);
使用nvidia-smi来查询GPU信息
nvidia-smi是一个命令行工具,可以帮助你管理操作GPU device,并且允许你查询和更改device状态。
nvidia-smi用处很多,比如,下面的指令:
$ nvidia-smi -L
GPU 0: Tesla M2070 (UUID: GPU-68df8aec-e85c-9934-2b81-0c9e689a43a7)
GPU 1: Tesla M2070 (UUID: GPU-382f23c1-5160-01e2-3291-ff9628930b70)
然后可以使用下面的命令来查询GPU 0 的详细信息:
$nvidia-smi –q –i 0
GPU架构:
GPU中每个SM都设计成支持数以百计的线程并行执行,并且每个GPU都包含了很多的SM,所以GPU支持成百上千的线程并行执行,当一个kernel启动后,thread会被分配到这些SM中执行。大量的thread可能会被分配到不同的SM,但是同一个block中的thread必然在同一个SM中并行执行。
CUDA采用Single Instruction Multiple Thread(SIMT)的架构来管理和执行thread,这些thread以32个为单位组成一个单元,称作warps。warp中所有线程并行的执行相同的指令。每个thread拥有它自己的instruction address counter和状态寄存器,并且用该线程自己的数据执行指令。
SIMT和SIMD(Single Instruction, Multiple Data)类似,SIMT应该算是SIMD的升级版,更灵活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通过将同样的指令广播给多个执行官单元来实现并行。一个主要的不同就是,SIMD要求所有的vector element在一个统一的同步组里同步的执行,而SIMT允许线程们在一个warp中独立的执行。SIMT有三个SIMD没有的主要特征:
- 每个thread拥有自己的instruction address counter
- 每个thread拥有自己的状态寄存器
- 每个thread可以有自己独立的执行路径
一个block只会由一个SM调度,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个block。
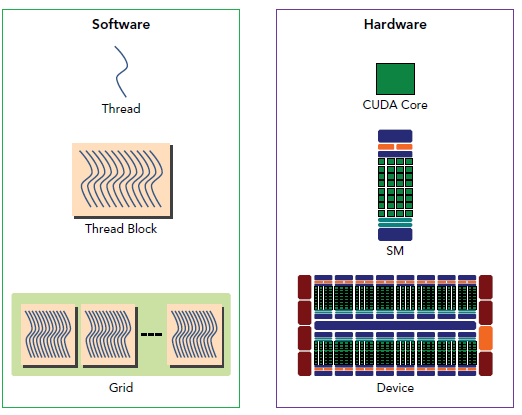
需要注意的是,大部分thread只是逻辑上并行,并不是所有的thread可以在物理上同时执行。这就导致,同一个block中的线程可能会有不同步调。
并行thread之间的共享数据回导致竞态:多个线程请求同一个数据会导致未定义行为。CUDA提供了API来同步同一个block的thread以保证在进行下一步处理之前,所有thread都到达某个时间点。不过,我们是没有什么原子操作来保证block之间的同步的。
同一个warp中的thread可以以任意顺序执行,active warps被SM资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以该新调度的warp的状态已经存储在SM中了。
SM可以看做GPU的心脏,寄存器和共享内存是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的thread。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。所以,掌握部分硬件知识,有助于CUDA性能提升。
Fermi架构与Kepler 架构
warp:
逻辑上,所有thread是并行的,但是,从硬件的角度来说,实际上并不是所有的thread能够在同一时刻执行,接下来我们将解释有关warp的一些本质。