mysql分区类型
日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表。这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕。分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率。
分区,partition,分区是将数据分段划分在多个位置存放,可以是同一块磁盘也可以在不同的机器。分区后,表面上还是一张表,但数据散列到多个位置了。app读写的时候操作的还是大表名字,db自动去组织分区的数据。
-- 查看是否支持分区 show variables like "%PARTITION%"; --EXPLAIN PARTITIONS查看用的哪个分区的数据 EXPLAIN PARTITIONS SELECT test_partition_list.schoolId FROM test_partition_list WHERE test_partition_list.schoolId = 2
Tip:分区与存储引擎无关,是MySQL逻辑层完成的。


mysql分区类型有:
- list分区:基于枚举出的值列表分区;
- range分区:基于给定的一个连续范围,把数据分配到不同的分区;
- hash分区:基于给定的分区个数,把数据分配到不同的分区;
- key分区:类似HASH分区
无论哪种MySQL分区类型,要么分区表上没有主键/唯一键 要么分区表的主键/唯一键必须包含分区键 ,不能使用主键/唯一键字段之外的其他字段分区
list分区:
按照列表值分区(in (值列表)
--表上的每一个唯一性索引必须用于分区表的表达式上(其中包括主键索引);言外之意就是如果有多个字段要建立唯一性索引可以:PRIMARY KEY ( `id`, `schoolId` )或者UNIQUE KEY (`id`, `schoolId`)
1 CREATE TABLE `test`.`test_partition_list` ( 2 `id` INT ( 11 ) NOT NULL, 3 `name` VARCHAR ( 255 ) NOT NULL, 4 `age` INT ( 3 ) NOT NULL, 5 `schoolId` INT ( 11 ) NOT NULL, 6 PRIMARY KEY ( `id`, `schoolId` ), 7 INDEX `name` ( `name` ) USING BTREE 8 ) ENGINE = INNODB CHARACTER 9 SET = utf8 COLLATE = utf8_unicode_ci PARTITION BY LIST ( schoolId ) ( 10 PARTITION `p0`VALUES IN ( 1, 5, 9, 10, 12, 15 ), 11 PARTITION `p1`VALUES IN ( 2, 4, 6, 8, 13, 11 ), 12 PARTITION `p2`VALUES IN ( 3, 7, 14, 16, 18 ), 13 PARTITION `p3`VALUES IN ( 19, 21, 23, 25, 27 ), 14 PARTITION `p4`VALUES IN ( 20, 22, 24, 26, 28 ) 15 );
对于不同的存储引擎,分区后生成的文件也不一样的;myisam是这样的:
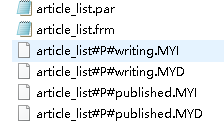
innodb是这样的:

range分区:
条件运算符(less than)
1 CREATE TABLE rc1 ( 2 a INT, 3 b INT, 4 PRIMARY KEY (a,b) 5 ) 6 PARTITION BY RANGE COLUMNS ( a,b ) ( 7 PARTITION p0 VALUES LESS THAN (10,5), 8 PARTITION p1 VALUES LESS THAN (20,15), 9 PARTITION p2 VALUES LESS THAN (30,25), 10 PARTITION p3 VALUES LESS THAN (40,30), 11 PARTITION p4 VALUES LESS THAN (50,40), 12 PARTITION p5 VALUES LESS THAN (MAXVALUE,MAXVALUE) 14 );
HASH分区:
主要用来分散热点读 确保数据在预先确定个数的分区中尽可能平均分布
对一个表执行HASH分区时候 MySQL会对分区键应用一个散列函数 确定数据应当放在N个分区中的哪个分区中
支持两种HASH分区:常规HASH分区 线性HASH分区(LINEAR HASH分区)
CREATE TABLE emp ( id INT NOT NULL, ename VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job VARCHAR(30) NOT NULL, store_id INT NOT NULL )PARTITION BY HASH (store_id) PARTITIONS 4;
分区按照MOD(store_id,4) 取模运算,分区名p0-3
常规HASH会出现的问题:如果增加分区或者合并分区的时候 取模算法需要改变 所有数据需要重新计算 为了降低分区管理的代价 提供线性HASH分区 分区函数是一个线性2的幂运算
Key分区
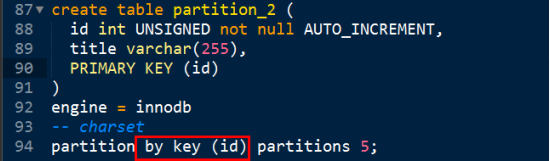
分成5个区,就是对5取余。将id对5取余。
注意:Key,hash都是取余算法,要求分区参数(括号里的),返回的数据必须为整数。
分区中的NULL值
MySQL数据库允许对NULL值做分区,但是处理的方法和Oracle数据库完全不同。MYSQL数据库的分区总是把NULL值视为小于任何一个非NULL值,这和MySQL数据库中对于NULL的ORDER BY的排序是一样的。因此对于不同的分区类型,MySQL数据库对于NULL值的处理是不一样的。
对于RANGE分区,如果对于分区列插入了NULL值,则MySQL数据库会将该值放入最左边的分区(这和Oracle数据库完全不同,Oracle数据库会将NULL值放入MAXVALUE分区中)。例如:
create table t_range( a int, b int )engine=innodb partition by range(b)( partition p0 values less than(10), partition p1 values less than(20), partition p2 values less than maxvalue );
接着往表中插入(1,1)和(1,NULL)两条数据,并观察每个分区中记录的数量:
insert into t_range select 1,1; insert into t_range select 1,NULL; select * from t_rangeG; select table_name,partition_name,table_rows from information_schema.PARTITIONS where table_schema=database() and table_name='t_range'G;
RANGE分区下,NULL值会放入最左边的分区中。另外需要注意的是,如果删除p0这个分区,你删除的是小于10的记录,并且还有NULL值的记录,这点非常重要。
LIST分区下要使用NULL值,则必须显式地指出哪个分区中放入NULL值,否则会报错,如:
create table t_list( a int, b int)engine=innodb partition by list(b)( partition p0 values in (1,3,5,7,9), partition p1 values in (0,2,4,6,8) ); insert into t_list select 1,NULL; ERROR 1526(HY000):Table has no partition for value NULL
若p0分区允许NULL值,则插入不会报错:
create table t_list( a int, b int)engine=innodb partition by list(b)( partition p0 values in (1,3,5,7,9,NULL), partition p1 values in (0,2,4,6,8) ); insert into t_list select 1,NULL; select table_name,partition_name,table_rows from information_schema.PARTITIONS where table_schema=database() and table_name='t_list';
HASH和KEY分区对于NULL的处理方式,和RANGE分区、LIST分区不一样。任何分区函数都会将含有NULL值的记录返回为0。如:
create table t_hash( a int, b int)engine=innodb partition by hash(b) partitions 4; insert into t_hash select 1,0; insert into t_hash select 1,NULL; select table_name,partition_name,table_rows from information_schema.PARTITIONS where table_schema=database() and table_name='t_hash';
***************************1.row***************************
table_name:t_hash
partition_name:p0
table_rows:2
分区管理
删除分区:
- 在key和hash领域删除分区不会造成数据丢失,而是把数据正和到剩余分区中;
- 在list和range领域删除分区后,会造成数据丢失。
求余方式(key / hash)
-- 求余方式删除分区的语法 alter table 表名 coalesce partition 数量
范围方式(list / range)
-- 范围方式 alter table 表名 drop partition 分区表名称

-
分区和性能
常听到开发人员说“对表做个分区,然后数据库的查询就会快了”。但是这是真的吗?实际中可能你根本感觉不到查询速度的提升,甚至是查询速度急剧的下降。因此,在合理使用分区之前,必须了解分区的使用环境。
数据库的应用分为两类:
- 一类是OLTP(在线事务处理),如博客、电子商务、网络游戏等;
- 一类是OLAP(在线分析处理),如数据仓库、数据集市。
在一个实际的应用环境中,可能既有OLTP的应用,也有OLAP的应用。如网络游戏中,玩家操作的游戏数据库应用就是OLTP的,但是游戏厂商可能需要对游戏产生的日志进行分析,通过分析得到的结果来更好地服务于游戏、预测玩家的行为等,而这却是OLAP的应用。
对于OLAP的应用,分区的确可以很好地提高查询的性能,因为OLAP应用的大多数查询需要频繁地扫描一张很大的表。假设有一张1亿行的表,其中有一个时间戳属性列。你的查询需要从这张表中获取一年的数据。如果按时间戳进行分区,则只需要扫描相应的分区即可。
对于OLTP的应用,分区应该非常小心。在这种应用下,不可能会获取一张大表中10%的数据,大部分都是通过索引返回几条记录即可。而根据B+树索引的原理可知,对于一张大表,一般的B+树需要2~3次的磁盘IO(到现在我都没看到过4层的B+树索引)。因此B+树可以很好地完成操作,不需要分区的帮助,并且设计不好的分区会带来严重的性能问题。
很多开发团队会认为含有1000万行的表是一张非常巨大的表,所以他们往往会选择采用分区,如对主键做10个HASH的分区,这样每个分区就只有100万行的数据了,因此查询应该变得更快了,如SELECT * FROM TABLE WHERE PK=@pk。但是有没有考虑过这样一个问题:100万行和1000万行的数据本身构成的B+树的层次都是一样的,可能都是2层?那么上述走主键分区的索引并不会带来性能的提高。是的,即使1000万行的B+树的高度是3,100万行的B+树的高度是2,那么上述走主键分区的索引可以避免1次IO,从而提高查询的效率。嗯,这没问题,但是这张表只有主键索引,而没有任何其他的列需要查询?如果还有类似如下的语句SQL:SELECT * FROM TABLE WHERE KEY=@key,这时对于KEY的查询需要扫描所有的10个分区,即使每个分区的查询开销为2次IO,则一共需要20次IO。而对于原来单表的设计,对于KEY的查询还是2~3次IO。
如下表Profile,根据主键ID进行了HASH分区,HASH分区的数量为10,表Profile有接近1000万行的数据:
CREATE TABLE 'Profile'( 'id' int(11) NOT NULL AUTO_INCREMENT, 'nickname' varchar(20) NOT NULL DEFAULT'', 'password' varchar(32) NOT NULL DEFAULT'', 'sex' char(1)NOT NULL DEFAULT'', 'rdate' date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY('id'), KEY 'nickname' ('nickname') )ENGINE=InnoDB partition by hash(id) partitions 10; select count(nickname)from Profile; count(1):9999248
因为是根据HASH分区的,因此每个区分的记录数大致是相同的,即数据分布比较均匀:
select table_name,partition_name,table_rows from information_schema.PARTITIONS where table_schema=database() and table_name='Profile';
注意:即使是根据自增长主键进行的HASH分区,也不能保证分区数据的均匀。因为插入的自增长ID并非总是连续的,如果该主键值因为某种原因被回滚了,则该值将不会再次被自动使用。
如果进行主键的查询,可以发现分区的确是有意义的:
explain partitions select * from Profile where id=1G;
可以发现只寻找了p1分区。
但是对于表Profile中nickname列索引的查询,EXPLAIN PARTITIONS则会得到如下的结果:
explain partitions select * from Profile where nickname='david'G;
可以看到,MySQL数据库会搜索所有分区,因此查询速度会慢很多,比较上述的语句:
select * from Profile where nickname='david'G;
上述简单的索引查找语句竟然需要1.05秒,这显然是因为搜索所有分区的关系,实际的IO执行了20~30次,在未分区的同样结构和大小的表上执行上述SQL语句,只需要0.26秒。
因此对于使用InnoDB存储引擎作为OLTP应用的表,在使用分区时应该十分小心,设计时要确认数据的访问模式,否则在OLTP应用下分区可能不仅不会带来查询速度的提高,反而可能会使你的应用执行得更慢。