2. 分区表的改进
PostgreSQL 10 实现了声明式分区,PostgtreSQL 11完善了功能,PostgreSQL 12提升了性能。我们知道在PostgreSQL 9.X时代需要通过表继承实现分区,这时还需要手工加触发器或规则把新插入的数据重新定向到具体的分区中,从PostgreSQL 10之后不需要这样了,直接用声明式分区就可以了,语法如下:
CREATE TABLE measurement (city_id int not null,logdate date not null,peaktemp int,unitsales int) PARTITION BY RANGE (logdate);CREATE TABLE measurement_y2006m02 PARTITION OF measurementFOR VALUES FROM ('2006-02-01') TO ('2006-03-01');
分区表更具体的一些变化如下:
-
PostgreSQL11: 分区表增加哈希分区
-
PostgreSQL11:分区表支持创建主键、外键、索引、触发器
-
PostgreSQL11: 分区表支持UPDATE分区键,如果在分区表上创建了一个索引,PostgreSQL 自动为每个分区创建具有相同属性的索引。
-
PosgtreSQL 11 支持为分区表创建一个默认(DEFAULT)的分区
-
对于 PostgreSQL 10 中的分区表,无法创建引用其他表的外键约束。 PostgreSQL 11 解决了这个限制,可以创建分区表上的外键。
-
在 PostgreSQL 10 中,分区上的索引需要基于各个分区手动创建,而不能基于分区的父表创建索引。PostgreSQL 11 可以基于分区表创建索引。如果在分区表上创建了一个索引,PostgreSQL 自动为每个分区创建具有相同属性的索引。
- PostgreSQL 12后: ALTER TABLE ATTACH PARTITION不会阻塞查询
3. PostgreSQL 10版本的功能增强
3.1 PostgreSQL 10 新功能总结如下:
-
支持同步复制多个standby:Quorum Commit
-
PostgreSQL 10开始增加声明式分区
-
PostgreSQL 10 增加了并行功能
-
PostgreSQL 10之后 hash索引可以走流复制,从此可以大胆的使用hash索引了。
-
PostgreSQL 10之后提供了逻辑复制的功能:发布订阅的功能
-
PostgreSQL 10可以把多列组合在一起再建直方图,让一些关联列上的执行计划更准确
-
可以支持同步复制到多个standby,即Quorum Commit
- 以前的密码验证式md5,现在增加了安全级别更高的密码验证的方式:SCRAM-SHA-256
3.2 并行查询功能:
- 实际上从9.6开始就有并行查询功能,但功能比较弱,到PostgreSQL 10版本之后,功能大大增强,后续的每个大版本或多或少都有功能增强。
-
并行的参数
- max_parallel_workers=16;
- max_parallel_workers_per_gather =4;
- min_parallel_table_scan_size:只有表的大小大于此值时才需要并行,默认为8M,可以设置为1G或更大的值。
-
保持与9.X相同的行为,可以关闭并行
- set max_parallel_workers_per_gather = 0
- 当需要并行时,可以手工设置max_parallel_workers_per_gather的值
- max_parallel_maintenance_workers
3.3 逻辑复制功能
逻辑解码实际上是在PostgreSQL 9.4开始准备的功能,在9.X时代,支持内置了逻辑解码的功能,如果要做两个数据库之间表数据的逻辑同步,需要自己写程序或使用一些开源的软件来实现。到PostgreSQL 10版本,原生提供了逻辑复制的功能,实现了逻辑发布和订阅的功能,逻辑复制的功能变化如下:
- PostgreSQL 10版本不支持truncate的同步,导致在10版本中,作为逻辑同步的表不能做truncate。从PostgreSQL 11版本之后可以支持truncate功能。
不过PostgreSQL自带的逻辑复制功能有以下限制:
- 逻辑解码是在主库上完成的,会消耗主库的CPU
- 必须建逻辑复制槽。但是逻辑复制槽会把主库的WAL给hold住,很多新手配置了逻辑复制,后来停掉了,但是忘记把逻辑复制槽给删除掉,最后把主库空间给撑爆
- 逻辑复制槽不支持备库,如果使用流复制的高可用方案,主备库切换后,逻辑复制就废了。
- 大事务会在主库中会生成一个临时文件,如果这个事务很大,这个临时文件也很大。
- 需要把wal_level级别设置logical,这会导致更多的WAL日志生成。
实际上中启乘数科技开发的有商业版的逻辑复制软件CMiner,解决了以上问题。CMiner本身是一个独立的程序,连接到主库上通过流复制协议拉取WAL日志,然后在本地解码,不会消耗主库的CPU,也不使用逻辑复制槽,没有把主库空间撑爆的风险,也可以方便的支持基于流复制的高可用方案,同时wal_level级别不需要设置为logical就可以完成解码。目前这套解决方案已经在银行中使用,有兴趣同学可以加微信 osdba0,或邮件 services@csudata.com 。
3.4 相关列上建组合的直方图统计信息
用实例说明这个功能:
create table test_t( a int4, b int4);insert into test_t(a,b) select n%100,n%100 from generate_series(1,10000) n;
上面的两个列a和b的数据相关的,即基本是相同的,而PostgreSQL默认计算各列是按非相关来计算了,所以算出的的COST值与实际相差很大:
osdba=# explain analyze select * from test_t where a=1 and b=1;QUERY PLAN----------------------------------------------------------------------------------------------------Seq Scan on test_t (cost=0.00..195.00 rows=1 width=8) (actual time=0.034..0.896 rows=100 loops=1)Filter: ((a = 1) AND (b = 1))Rows Removed by Filter: 9900Planning Time: 0.185 msExecution Time: 0.916 ms
如上面,估计出只返回1行,实际返回100行。这在一些 复杂SQL中会导致错误的执行计划。
这时我们可以在相关列上建组合的直方图统计信息:
osdba=# CREATE STATISTICS stts_test_t ON a, b FROM test_t;CREATE STATISTICSosdba=# analyze test_t;ANALYZEosdba=# explain analyze select * from test_t where a=1 and b=1;QUERY PLAN------------------------------------------------------------------------------------------------------Seq Scan on test_t (cost=0.00..195.00 rows=100 width=8) (actual time=0.012..0.830 rows=100 loops=1)Filter: ((a = 1) AND (b = 1))Rows Removed by Filter: 9900Planning Time: 0.127 msExecution Time: 0.848 ms(5 rows)
从上面可以看出当我们建了相关列上建组合的直方图统计信息后,执行计划中估计的函数与实际一致了。
3.5 一些其它功能
hash索引从PostgreSQL 10开始可以放心大胆的使用:
-
PostgreSQL 9.X 版本hash索引走不了流复制,所以基本没有人用hash索引,即如果用了hash索引,在激活备库时,需要重建hash索引。
-
到PostgreSQL 10.X,hash索引可以通过流复制同步到备库,所以没有这个问题了,这是可以大胆的使用hash索引了。
到PostgreSQL 10之后,很多函数都进行了改名,其中把函数名中的“xlog”都改成了“wal”,把“position”都改成了“lsn”:
-
pg_current_wal_lsn
-
pg_current_wal_insert_lsn
-
pg_current_wal_flush_lsn
-
pg_walfile_name_offset
-
pg_walfile_name
-
pg_wal_lsn_diff
-
pg_last_wal_receive_lsn
-
pg_last_wal_replay_lsn
-
pg_is_wal_replay_paused
-
pg_switch_wal
-
pg_wal_replay_pause
-
pg_wal_replay_resume
-
pg_ls_waldir
PostgreSQL 10对一些目录也改名:
-
Rename write-ahead log directory pg_xlog to pg_wal
-
rename transaction status directory pg_clog to pg_xact
PostgreSQL 9.X,同步复制只能支持一个同步的备库,PostgtreSQL 10 可以支持多个同步的standby,这称为“Quorum Commit”,同步复制的配置发生如下变化:
-
synchronous_standby_names
- FIRST num_sync (standby_name [, …]):保持前面几个备库必须与主库保持同步。
- ANY num_sync (standby_name [, …]):保证num_sync 个备库与主库保持同步。
-
原先的配置: synchronous_standby_names=’stb01,stb02,stb03’实际相当于: synchronous_standby_names=FIRST 1(stb01,stb02,stb03)’
索引的增强:
- BRIN索引增强:
- BRIN索引增加了存储选项autosummarize,可以自动计算摘要
- 增加了函数brin_summarize_range()和brin_desummarize_range() 可以手工为BRIN的指定块建摘要和去除摘要。以前BRIN只有函数brin_summarize_new_values()、 gin_clean_pending_list()
- Improve accuracy in determining if a BRIN index scan is beneficial (David Rowley, Emre Hasegeli)
- INET和CIDR类型上支持建SP-GiST类型的索引
- 在GiST索引的插入和更新可以更高效的重用空间
- Reduce page locking during vacuuming of GIN indexes
串行隔离级别 预加锁阈值可控
- max_pred_locks_per_relation: 当单个对象的行或者页预加锁数量达到阈值时,升级为对象预加锁。减少内存开销。
- max_pred_locks_per_page:当单个页内多少条记录被加预加锁时,升级为页预加锁。减少内存开销
PostgreSQL 10提供了视图pg_hba_file_rules方便查询访问控制的黑白名单:
osdba=# select * from pg_hba_file_rules;line_number | type | database | user_name | address | netmask | auth_method | options | error-------------+-------+---------------+-----------+---------+---------+-------------+---------+-------80 | local | {all} | {all} | | | peer | |83 | host | {all} | {all} | 0.0.0.0 | 0.0.0.0 | md5 | |88 | local | {replication} | {all} | | | peer | |
psql增加了:if, elif, else, and endif.
SELECTEXISTS(SELECT 1 FROM customer WHERE customer_id = 123) as is_customer,EXISTS(SELECT 1 FROM employee WHERE employee_id = 456) as is_employeegsetif :is_customerSELECT * FROM customer WHERE customer_id = 123;elif :is_employeeecho 'is not a customer but is an employee'SELECT * FROM employee WHERE employee_id = 456;elseif yesecho 'not a customer or employee'elseecho 'this will never print'endifendif
其它的一些功能:
-
提升了聚合函数sum()、avg()、stddev()处理numeric类型的性能
-
Allow hashed aggregation to be used with grouping sets
-
Improve sort performance of the macaddr data type (Brandur Leach)
-
Add pg_stat_activity reporting of low-level wait states (Michael Paquier, Robert Haas, Rushabh Lathia)
- This change enables reporting of numerous low-level wait conditions, including latch waits, file reads/writes/fsyncs, client reads/writes, and synchronous replication.
-
Show auxiliary processes, background workers, and walsender processes in pg_stat_activity (Kuntal Ghosh, Michael Paquier)
-
This simplifies monitoring. A new column backend_type identifies the process type.
-
Prevent unnecessary checkpoints and WAL archiving on otherwise-idle systems (Michael Paquier)
-
Increase the maximum configurable WAL segment size to one gigabyte (Beena Emerson)
-
Add columns to pg_stat_replication to report replication delay times (Thomas Munro)
- The new columns are write_lag, flush_lag, and replay_lag.
-
Allow specification of the recovery stopping point by Log Sequence Number (LSN) in recovery.conf (Michael Paquier)
-
Previously the stopping point could only be selected by timestamp or XID.
-
Improve performance of hot standby replay with better tracking of Access Exclusive locks (Simon Riggs, David Rowley)
-
Speed up two-phase commit recovery performance (Stas Kelvich, Nikhil Sontakke, Michael Paquier)
-
Allow restrictive row-level security policies (Stephen Frost)
-
Add CREATE SEQUENCE AS command to create a sequence matching an integer data type (Peter Eisentraut)
-
Allow the specification of a function name without arguments in DDL commands, if it is unique (Peter Eisentraut)
-
Improve speed of VACUUM’s removal of trailing empty heap pages (Claudio Freire, Álvaro Herrera)
-
Add full text search support for JSON and JSONB (Dmitry Dolgov)
-
The functions ts_headline() and to_tsvector() can now be used on these data types.
-
自增列原先只有用serial和bigserial创建自增列,现在可以标准的语法创建自增列
CREATE TABLE test01 (id int PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,t text);
- 增加减号为jsonb类型的删除某个key的操作符
postgres=# select '{"a": 1, "b": 2, "c":3}'::jsonb - '{a,c}'::text[];?column?----------{"b": 2}(1 row)
-
Allow specification of multiple host names or addresses in libpq connection strings and URIs (Robert Haas, Heikki Linnakangas)。
- libpq will connect to the first responsive server in the list.
- 配合连接参数target_session_attrs=read-write,只是只会连接到一个主库上。
-
Allow file_fdw to read from program output as well as files (Corey Huinker, Adam Gomaa)
-
In postgres_fdw, push aggregate functions to the remote server, when possible (Jeevan Chalke, Ashutosh Bapat)
4. PostgreSQL 11版本的新特性
4.1 PostgreSQL 11版本的功能总结
总结如下:
-
JIT即时编译功能,提升一些批计算如SUM的性能,通常提升在10%左右。
-
存储过程中可以加commit或rollback事物
-
声明式分区表功能大大增强: 分区表可以加主键、外键、索引,支持hash分区表
-
CREATE INDEX可以并行
-
增加非空列也是瞬间完成,不需要rewrite表
-
hash join支持并行
-
vacuum增强:空闲空间可以更快的被重用,跳过一些没有必要的索引扫描
-
提升了多个并发事务commit的性能
- 逻辑复制支持truncate的同步
- 支持存储过程(CREATE PROCEDURE),并可以在存储过程中嵌入事务
- CREATE INDEX使用INCLUDE可以非键值列放到索引中,以便走Covering indexes而不必回表
- 以前触发toast的压缩都需要插入的数据大于1996个字节时才会触发,这个1996字节是固定的,不能改,现在给表加了存储参数 toast_tuple_target,可以设置更新的值就可以触发toast的压缩机制
- 允许在initdb时改变 WAL文件的大小,以前是需要重新编译程序才能改变WAL文件的大小
- 现在在WAL日志中会把使用的部分填0,这样可以提高压缩率
4.2 PostgreSQL 11版本的jit
即时编译功能:
-
常用于CPU密集型SQL(分析统计SQL),执行很快的SQL使用JIT由于产生一定开销,反而可能引起性能下降
-
jit的参数:
- jit = on
- jit_provider = ‘llvmjit’
- jit_above_cost= 100000
4.3 PostgtreSQL一些其它增强
新的变化:
-
可以手工调整复制槽的记录的位置:
- Allow replication slots to be advanced programmatically, rather than be consumed by subscribers (Petr Jelinek)
- This allows efficient advancement of replication slots when the contents do not need to be consumed. This is performed by pg_replication_slot_advance().
-
以前给表加有默认值的列时需要重写文件,现在不需要了
- Allow ALTER TABLE to add a column with a non-null default without doing a table rewrite (Andrew Dunstan, Serge Rielau)
- This is enabled when the default value is a constant.
PostgreSQL 11版本的一些新特性
-
PostgreSQL11: 新增三个默认角色
-
PostgreSQL11: 可通过GRNAT权限下放的四个系统函数
-
PostgreSQL11: Initdb/pg_resetwal支持修改WAL文件大小
-
PostgreSQL11: 新增非空默认值字段不需要重写
–ALTER TABLE table_name ADD COLUMN flag text DEFAULT ‘default values’;
-
PostgreSQL11: Indexs With Include Columns
CREATE TABLE t_include(a int4, name text);CREATE INDEX idx_t_include ON t_include USING BTREE (a) INCLUDE (name);
-
PostgreSQL11: initdb/pg_resetwal支持修改WAL文件大小,以前需要重新编译程序,才能改变。
PostgreSQL 10、11增加了一些 系统角色,方便监控用户的权限:
- PostgreSQL 11 新增三个默认系统角色,如下:
- pg_read_server_files
- pg_write_server_files
- pg_execute_server_program
- PostgreSQL 10
- pg_read_all_settings
- pg_read_all_stats
- pg_stat_scan_tables
- pg_monitor
- PostgreSQL9.6只有一个系统角色:
- pg_signal_backend
PostgreSQL 11 版本的psql中增加了命令gdesc可以查看执行结果的数据类型:
osdba=# select * from test01 gdescColumn | Type--------+---------id | integerid2 | integert | text(3 rows)
PostgreSQL 11版本psql增加了五个变量更容易查询SQL执行失败的原因:
- ERROR
- SQLSTATE
- ROW_COUNT
- LAST_ERROR_MESSAGE
- LAST_ERROR_SQLSTATE
使用示例如下:
osdba=# select * from test01;id | t----+-----1 | 1112 | 222(2 rows)osdba=# echo :ERRORfalseosdba=# echo :SQLSTATE00000osdba=# echo :ROW_COUNT2osdba=# select * from test02;ERROR: relation "test02" does not existLINE 1: select * from test02;^osdba=# echo :ERRORtrueosdba=# echo :SQLSTATE42P01osdba=# echo :LAST_ERROR_MESSAGErelation "test02" does not existosdba=# echo :LAST_ERROR_SQLSTATE42P01
5. PostgreSQL 12版本的新特性
5.1 新特性总结
特性如下:
-
PostgreSQL 12开始取消了recovery.conf,把配置项移动到postgresql.conf中
- 为了表明此库是备库,需要在$PGDATA下建standby.signal 空文件。去掉了配置项standby_mode
- 配置项trigger_file改名为promote_trigger_file
- PostgreSQL 12 只能同时配置恢复目标项的一项,不能同时配置:recovery_target, recovery_target_lsn, recovery_target_name, recovery_target_time, recovery_target_xid
- pg_stat_replication中增加了应用延迟时间字段: reply_time
-
减少了在创建GiST,GIN,SP-GiST索引的WAL日志量
- max_wal_senders 连接数从 max_connections 剥离
-
支持在线重建索引:REINDEX CONCURRENTLY
-
在Btree索引中减少了不必要的多版本数据,提升了性能。
-
PG12默认开启了JIT
-
提升了position函数的性能
-
SERIALIZABLE事物事物隔离级别也可以并行查询
-
VACUUM增加了选项TRUNCATE,有可能不需要vacuum full也能释放部分空间到操作系统
- 分区表的性能得到了加强。
5.2 对VACUUM的增强:
osdba=# h vacuumCommand: VACUUMDescription: garbage-collect and optionally analyze a databaseSyntax:VACUUM [ ( option [, ...] ) ] [ table_and_columns [, ...] ]VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ ANALYZE ] [ table_and_columns [, ...] ]where option can be one of:FULL [ boolean ]FREEZE [ boolean ]VERBOSE [ boolean ]ANALYZE [ boolean ]DISABLE_PAGE_SKIPPING [ boolean ]SKIP_LOCKED [ boolean ]INDEX_CLEANUP [ boolean ]TRUNCATE [ boolean ]and table_and_columns is:table_name [ ( column_name [, ...] ) ]URL: https://www.postgresql.org/docs/12/sql-vacuum.html
如上所示,增加了一些选项:
- DISABLE_PAGE_SKIPPING: 通常,VACUUM将基于可见性映射跳过页面。如果.vm文件损坏,可以把这个参数设置为true.
- SKIP_LOCKED:跳过一给锁定的,防止vacuum被hang
- INDEX_CLEANUP: 默认是YES。
- TRUNCATE:把一些未用连续的数据块空间释放给文件系统,相当与数据文件是一个稀疏文件,即在一些情况下不需要VACUUM FULL也能释放一些空间给文件系统。
其它的一些变化:
-
PostgreSQL 12版本之后:max_wal_senders 连接数从 max_connections 剥离
-
PostgreSQL 12 版本之后支持:REINDEX CONCURRENTLY
- PostgreSQL12版本之后:减少了在创建GiST,GIN,SP-GiST索引的WAL日志量
- PostgreSQL 12 只能配置一个:recovery_target, recovery_target_lsn, recovery_target_name, recovery_target_time, recovery_target_xid.
- pg_basebackup从PostgreSQL 10之后可以支持限流
6. PostgreSQL 13版本的新特性
6.1 新特性总结
总结如下:
- 对vacumm增加了并行的功能
- 改变流复制的配置可以不用重启数据库了
- 更多的一些情况下可以对分区进行裁剪和智能join
- 如原先智能join必须两个分区的范围精确相同,现在可以更智能了。CAFjFpRdjQvaUEV5DJX3TW6pU5eq54NCkadtxHX2JiJG_GvbrCA@mail.gmail.com"">https://www.postgresql.org/message-id/CAFjFpRdjQvaUEV5DJX3TW6pU5eq54NCkadtxHX2JiJG_GvbrCA@mail.gmail.com
- 三个表的full outer join也可以走wise join
- 分区智能join是从PostgreSQL 11版本添加的功能
- 分区表可以支持before trigger(不允许改变插入数据的目标分区)
- 分区表可以支持逻辑复制了
- 之前只能把分区表的各个分区单独的做为复制源,现在可以把分区表直接做为复制源。
- 先前订阅者只能把数据同步到非分区表,现在可以把数据同步到分区表
- Allow whole-row variables (that is, table.*) to be used in partitioning expressions (Amit Langote)
- 支持异构分区表逻辑复制: http://www.postgres.cn/v2/news/viewone/1/604
- https://www.postgresql.org/message-id/flat/CA+HiwqH=Y85vRK3mOdjEkqFK+E=ST=eQiHdpj43L=_eJMOOznQ%40mail.gmail.com
- 索引中重复的项做了优化处理,更节省空间。重复的项只存储一次
- 聚合时使用hash算法可以使用磁盘做溢出存储
- 增量排序(Incremental sort)的功能
- 提升了PL/pgSQL中简单表达式的性能
- pg_stat_statements插件增加了选项可以跟踪SQL的planning time,而不仅仅是执行时间
6.2 分区表智能join
6.2.1 不要求分区的范围完全相等
具体可见:advanced partition matching algorithm for partition-wise join
看例子:
create table t1(id int) partition by range(id);create table t1_p1 partition of t1 for values from (0) to (100);create table t1_p2 partition of t1 for values from (150) to (200);create table t2(id int) partition by range(id);create table t2_p1 partition of t2 for values from (0) to (50);create table t2_p2 partition of t2 for values from (100) to (175);
然后我们分别在PostgreSQL 12版本和PostgreSQL 13执行下面的SQL:
explain select * from t1, t2 where t1.id=t2.id;
对比如下:

6.2.2 三个分区表full outer join也智能join
看例子:
create table p (a int) partition by list (a);create table p1 partition of p for values in (1);create table p2 partition of p for values in (2);set enable_partitionwise_join to on;

6.3 索引消除重复项
PostgreSQL 13中对索引的重复的项做了优化处理,更节省空间。重复的项只存储一次。
看例子:
PG13索引的大小:
postgres=# create table test01(id int, id2 int);CREATE TABLEpostgres=# insert into test01 select seq, seq / 1000 from generate_series(1, 1000000) as seq;INSERT 0 1000000postgres=# create index idx_test01_id2 on test01(id2);CREATE INDEXpostgres=# imingTiming is on.postgres=# select pg_relation_size('idx_test01_id2');pg_relation_size------------------7340032(1 row)
如果是PG9.6:
postgres=# select pg_relation_size('idx_test01_id2');pg_relation_size------------------22487040(1 row)
可以看到索引的大小是以前的三分之一。
索引中去除重复项的原理:
- 类似倒排索引GIN,一个索引的key值,对应多个物理行。
- pg_upgrade升级数据库后,需要reindex才能让旧索引使用到此特性
有一些情况可能无法去除重复项:
- numeric不能使用去重
- jsonb类型不能使用去重
- float4和float8不能使用去重
- INCLUDE indexes不能使用去重
- text, varchar, and char 类型的索引使用了非确定性排序(nondeterministic collation)
- Container types (such as composite types, arrays, or range types) cannot use deduplication.
给索引增加了存储参数deduplicate_items以支持这个功能。
6.4 聚合时使用hash算法可以使用磁盘做溢出存储
以前当表特别大时,hash表超过work_mem的内存时,聚合时就走不到hash,只能走排序的算法,而排序聚合比hash聚合通常慢几倍的性能,现在有了用磁盘存储溢出的hash表,聚合的性能大大提高
同时增加了参数hash_mem_multiplier,hasn聚合的内存消耗现在变成了work_mem* hash_mem_multiplier,默认此参数hash_mem_multiplier为1,即hash表的大小还是以前的大小
现在使用了 HyperLogLog算法来估算唯一值的个数,减少了内存占用。
请看例子:
CREATE TABLE t_agg (x int, y int, z numeric);INSERT INTO t_agg SELECT id % 2, id % 10000, random()FROM generate_series(1, 10000000) AS id;VACUUM ANALYZE;SET max_parallel_workers_per_gather TO 0;SET work_mem to '1MB';explain analyze SELECT x, y, avg(z) FROM t_agg GROUP BY 1,2;
在12.4版本中聚合使用了排序算法,时间花了14.450秒,如下图所示:
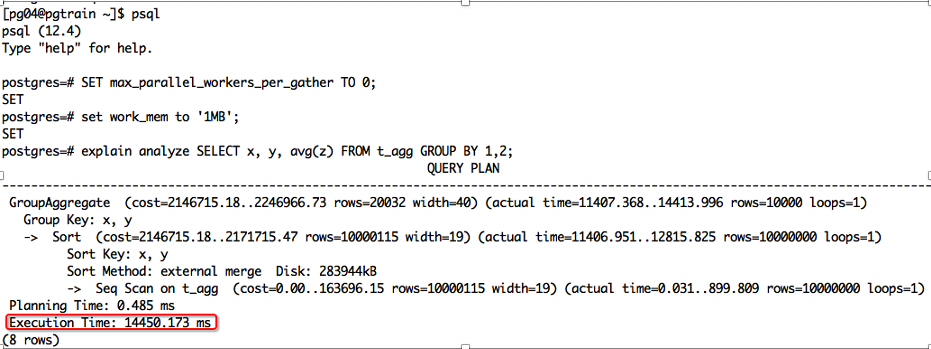
而在13版本中,走了hash聚合,时间花了6.186秒,时间缩短了一半还多,如下图所示:

6.5 增量排序(Incremental sort)的功能
官方手册中也有例子:https://www.postgresql.org/docs/13/using-explain.html#USING-EXPLAIN-BASICS
见我们的例子:
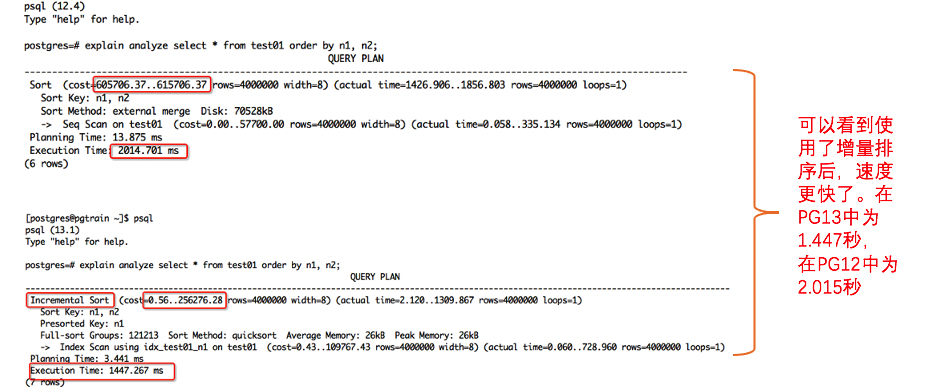
create table test01(n1 int, n2 int);insert into test01 select seq/3, (seq / 97) % 100 from generate_series(1, 4000000) as seq;create index idx_test01_n1 on test01(n1);analyze test01;
然后分别在PostgreSQL 12版本和PostgreSQL 13版本下看下面SQL的执行计划和执行时间:
explain analyze select * from test01 order by n1, n2;
可以看到使用了增量排序后,速度更快了。在PG13中为1.447秒,在PG12中为2.015秒:
6.6 vacumm增加了并行的功能
具体实现是SQL命令vacuum上增加了parallel的选项:
vacuum (parallel 5);
命令行工具vacuumdb增加了选项—parallel=:
vacuumdb -P 3
主要是实现了对索引的并行vacuum
并行度受到max_parallel_maintenance_workers参数的控制
索引的大小至少要大于参数min_parallel_index_scan_size的值(512KB),才会并行vacuum
具体可以见:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=40d964ec997f64227bc0ff5e058dc4a5770a70a9
6.7 其它的一些功能增强
增强的功能如下:
-
增加参数autovacuum_vacuum_insert_threshold、 autovacuum_vacuum_insert_scale_factor:
- 原先如果对于只有insert的表(append only table)不会触发vacuum,这时会一直累积到aggressive vacuum,这样会导致vacuum太不及时,现在有这个参数,解决了这个不及时的问题。
- 为了实现这个功能在pg_stat_all_tables表中增加了列n_ins_since_vacuum,记录自上一次vacuum以来这个表插入了多少行。
- https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=b07642dbcd8d5de05f0ee1dbb72dd6760dd30436
- https://news.knowledia.com/US/en/articles/postgresql-v13-new-feature-tuning-autovacuum-on-insert-only-tables-f0a6f5028ecaed253723bab69926a04b45cd3a2f
-
reindexdb增加了—jobs,可以建多个数据库连接来并发来重建索引。
- wal_skip_threshold
- Skip WAL for new relfilenodes, under wal_level=minimal.
- https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=c6b92041d38512a4176ed76ad06f713d2e6c01a8
- 提升了PL/pgSQL中简单表达式的性能,如”x+1”或”x>0”,性能提升大致2倍
- effective_io_concurrency参数
- 默认值改为1,与原先一样。如果设置大于1的值,则为实际的并发IO
- 测试发现PostgreSQL在bitmap index scan时,如果要读入大量堆page,读IO的速度会远低于正常的顺序读,影响性能,这时可以把此值设置大。
- 允许的范围是 1 到 1000,或 0 表示禁用异步 I/O 请求。当前这个设置仅影响位图堆扫描
- jsonb @>
- https://www.postgresql.org/message-id/12237.1582833074%sss.pgh.pa.us
- Less-silly selectivity for JSONB matching operators
- https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=a80818605e5447b9b846590c3d3fab99060cb53e
- pg_stat_slru 查看slru的统计信息
- https://www.postgresql.org/message-id/flat/20200119143707.gyinppnigokesjok%40development
- https://www.postgresql.org/docs/13/monitoring-stats.html#MONITORING-PG-STAT-SLRU-VIEW
- 原文地址:http://www.pgsql.tech/article_101_10000102