#坐标轴负一问题
plt.rcParams['axes.unicode_minus'] =False
#分割数据集
from sklearn.model_selection import train_test_split
data=pd.read_csv('./贝叶斯.csv',header=None)
print(data.shape) #显示几行几列
#拆分数据
dataset_X,dataset_y =data.iloc[:,:-1],data.iloc[:,-1]
# print(dataset_X.head())
## 将pandas转为np.ndarray 可以用dataset = df.as_matrix()
dataset_X =dataset_X.values
dataset_y =dataset_y.values
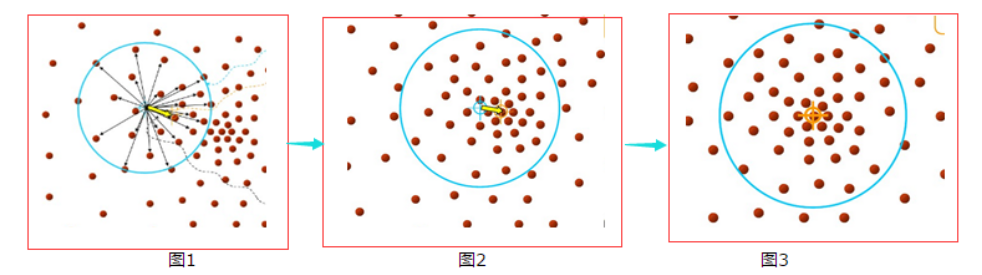
#估算带宽
from sklearn.cluster import estimate_bandwidth,MeanShift
# estimate_bandwidth有估计带宽的意思 n_clusters聚类的个数 quantile分位数,分位点
bandwidth = estimate_bandwidth(dataset_X,quantile=0.1,n_samples=len(dataset_X))
#打印出带宽
print(bandwidth).
#初始化聚类模型 band带宽 bin_seeding网格化数据点(加速模型)
meanshift = MeanShift(bandwidth=bandwidth,bin_seeding=True)
# 训练模型
meanshift.fit(dataset_X)
print(meanshift.cluster_centers_)
print(meanshift.labels_)
此时打印除掉数据如下,

#最后一步,将图形绘制出,查看一下效果
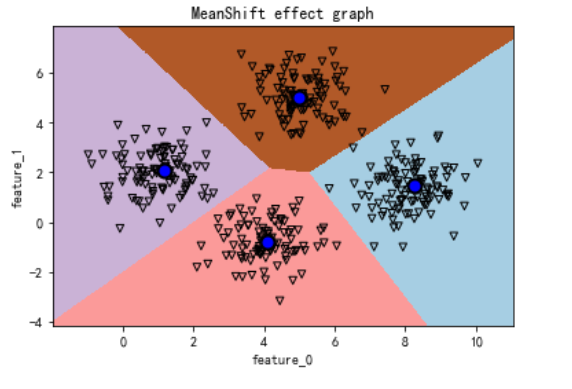
def visual_meanshift_effect(meanshift,dataset):
assert dataset.shape[1]==2,'only support dataset with 2 features'
X=dataset[:,0]
Y=dataset[:,1]
X_min,X_max=np.min(X)-1,np.max(X)+1
Y_min,Y_max=np.min(Y)-1,np.max(Y)+1
X_values,Y_values=np.meshgrid(np.arange(X_min,X_max,0.01),
np.arange(Y_min,Y_max,0.01))
# 预测网格点的标记
predict_labels=meanshift.predict(np.c_[X_values.ravel(),Y_values.ravel()])
predict_labels=predict_labels.reshape(X_values.shape)
plt.figure()
plt.imshow(predict_labels,interpolation='nearest',
extent=(X_values.min(),X_values.max(),
Y_values.min(),Y_values.max()),
cmap=plt.cm.Paired,
aspect='auto',
origin='lower')
# 将数据集绘制到图表中
plt.scatter(X,Y,marker='v',facecolors='none',edgecolors='k',s=30)
# 将中心点绘制到图中
centroids=meanshift.cluster_centers_
plt.scatter(centroids[:,0],centroids[:,1],marker='o',
s=100,linewidths=2,color='k',zorder=5,facecolors='b')
plt.title('MeanShift effect graph')
plt.xlim(X_min,X_max)
plt.ylim(Y_min,Y_max)
plt.xlabel('feature_0')
plt.ylabel('feature_1')
plt.show()
visual_meanshift_effect(meanshift,dataset_X)