hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar中存有MapReduce的例子程序
运行Hadoop 的jar包:
D:Hadoop2.6.4hadoop-2.6.4sharehadoopyarn下的所有jar包,D:Hadoop2.6.4hadoop-2.6.4sharehadoopyarnlib下的所有jar包
D:Hadoop2.6.4hadoop-2.6.4sharehadoopmapreduce下的所有jar包,D:Hadoop2.6.4hadoop-2.6.4sharehadoopmapreducelib下的所有jar包
运行代码:
map阶段:
package com.lq.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; //KEYIN:输入的key的泛型 这里指(读取的文件)每一行的偏移量,mapperduce读取文件以字节流方式读取 指每一行的起始偏移量 一般没用 //VALUEIN:输入的值的类型,指一行的内容 //KEYOUTL:输出的key的类型 //VALUEOUT:输出的value的类型 mappreduce处理数据要数据传输到磁盘或网络传输时要序列化与反序列化 //Java的序列化接口serializable 连同类结构进行序列化,反序列化 Hadoop不用这个方法,Hadoop提供序列化接口:Writable //Hadoop提供的不同类型对应的序列化类型:int-----IntWritable Long----LongWritable double-----DoubleWritable String---Text none---NullWritable
//Hadoop提供的类型转为Java类型:get()方法;Java类型转为Hadoop类型:Intwritable()..... //将每个单词拆出标签<单词,1> public class WordCountMapper extends Mapper<LongWritable, Text, Text,IntWritable > { /* * //LongWritable key:每一行的起始偏移量 //Text value:每一行的内容,每次读取的内容 //Context * context:上下文对象,用于传输 */ @Override protected void map(LongWritable key, Text value,Context context) //一行调用一次 throws IOException, InterruptedException { //获取到每一行的内容,进行每个单词的切分,加标签 String line = value.toString(); //获取到一行的内容 String[] words = line.split(" "); //切分每个单词 for(String word:words) { context.write( new Text(word), new IntWritable(1)); //为每个单词添加标签1,需要转换Hadoop提供的类型 } } }
reduce阶段:
package com.lq.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /* KEYIN:mapper输出的类型Text VALUEIN:mapper输出的value类型IntWritable KEYOUT:reduce处理完结果key的类型Text VALUEOUT:reduce处理完单词出现的类型IntWritable */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> //输入为map的输出 { /* Text key:reduce的输入,每一组中的相同的key Iterable<IntWritable> value:reduce的输入 <word,1>,相同的单词在一起,map端传输到reduce端过程中mappreduce框架会将key相同的分组到相同的一组,每一组相同的key对应的所有value值,迭代器中存放很多1 Context context:上下文对象,传输到hdfs(或本地) */ @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int sum=0; for(IntWritable value:values) { sum+=value.get(); //get()将Hadoop类型转换为Java类型并相加 } context.write(key, new IntWritable(sum)); } }
主驱动类:
代码流程:
1,加载配置文件
2,调用计算程序,封装计算程序的mapper,reduce,输入,输出
3,设置主驱动类反射
4,设置mapper类,reduce类以及mapper,reduce输出的key,value类
5,设置输入,需要统计单词的路径,args[0]为控制台手动输入的参数;设置输出,最终结果输出的路径,输出路径之前不能存在
6,提交Job
package com.lq.test; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /* * mappreduce代码运行: * 1,将代码打jar包,提交到集群运行,真实生产中用,缺点:不便于代码的修改和调试 mapperduce的组装 mapreduce的计算程序:job */public class Driver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //加载配置文件 Configuration conf=new Configuration(); Job job=Job.getInstance(conf); //调用计算程序,封装计算程序的mapper,reduce,输入,输出 job.setJarByClass(Driver.class); //设置主驱动类反射 Hadoop运行是jar包类型 job.setMapperClass(WordCountMapper.class);//设置mapper类 job.setReducerClass(WordCountReducer.class);//设置reduce类 job.setMapOutputKeyClass(Text.class); //设置map的输出类型 代码运行时泛型会被自动擦除 job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);//设置reduce的输出类型 job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); //设置输入,需要统计单词的路径,args[0]为控制台手动输入的参数 FileOutputFormat.setOutputPath(job, new Path(args[1]));//设置输出,最终结果输出的路径,输出路径之前不能存在 // job.submit(); //job提交,一般不打印日志 job.waitForCompletion(true); //true为打印执行日志 } }
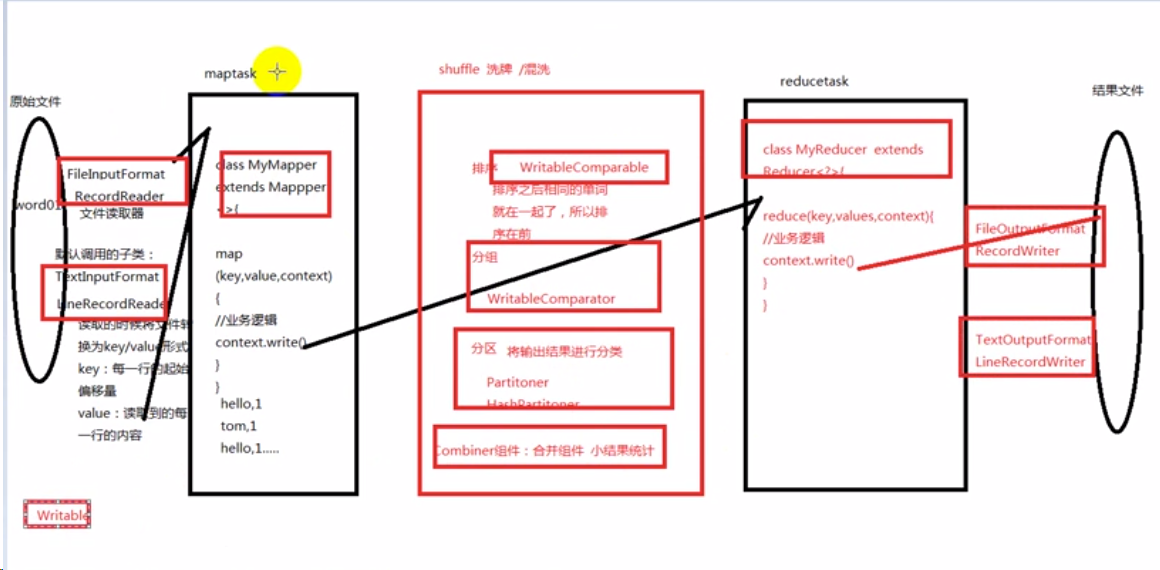
MapReduce程序流程: