1.分片内部基本结构
在一个分片中(Lucene),数据(数据原文和倒排索引)以段为单位存储,只有成为段的数据才能被检索。
因为文档先被缓存在内存中,创建倒排索引和其他索引结构之后才会成为段,才能被检索
就像下图中文档先被写入内存,为文档构建一系列索引之后成为段,并且写入磁盘,只有段才是 Searchable (可检索的)。
需要注意的是,段是不可被更改的,也就是写入到硬盘中是什么就是什么,无法再去硬盘中定位他们进行写操作。
不能修改当然有利有弊,最大的好处莫过于:
1.不需要并发控制
2.段被从硬盘读入到操作系统在内存中的文件缓存时,能被长期缓存,不会因为修改删除之类的操作使得内存中的缓存失效
最大的坏处 就是他自己本身:不能修改,或者删除
虽然不能物理上删除或者修改,但是逻辑上行得通,需要使用额外的文件去标记某个段的某条文档是否被删除,更新。
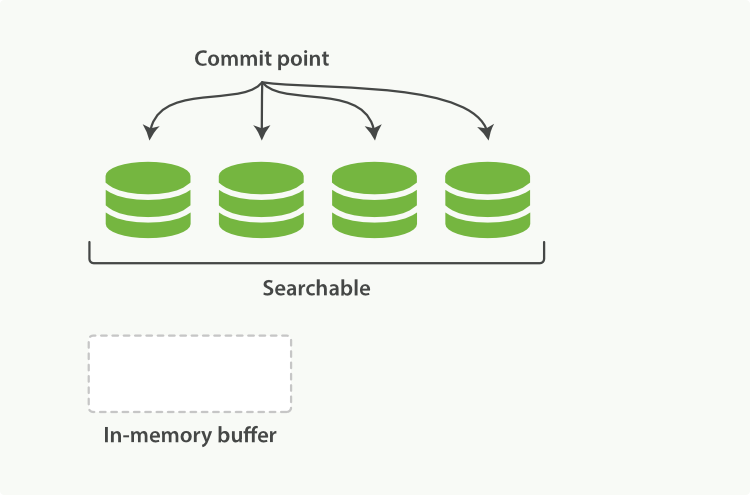
可能你已经注意到 commit point 了,在ES中,commit point 本身是一个集合,记录着一系列段的名字(或者说唯一标识)。
当提交新段的时候,会将这个段写入磁盘,并且写入一个新的 commit point,新的 commit point 包含了 新的段的名字。
提交段生成提交点,语义明确。

其实 commit point 类似于 innodb 中的 checkpoint, innodb中的 checkpoint 表示硬盘中的数据页的最新 LSN ,在通过redolog 崩溃恢复的时候,会从 checkpoint 开始
检查redolog 中 LSN 比 checkpoint 大的记录,并且把他们应用到数据页中去。崩溃恢复其实差不多都是这个老套路。
2.随之而来的问题
假如如上所述,一个新段要同步回硬盘(一般使用系统调用fsync),才能被用来检索的话(Searchable)。
因为fsync 耗时长,对于对实时性要求高的 应用来说,是不能容忍的(写入数据后要求立刻检索到,比如订单业务)
那么就不应该调用 fsync 后才使得新段能被打开使用(“打开”意味着能够被检索使用)。
要知道操作系统在硬盘和用户之间设置了一层缓存,这层缓存在内存中,平时 mmap 文件的时候,使用的也是这一层文件缓存。
假如不调用 fsync,而是把新段写入操作系统文件缓存就能使得新段Searchable的话,显然是可以接受的,因为写入内存的操作耗时比起写硬盘等外设来说短之又短
官方提出 近实时搜索 ,就是依据这一点出发的。下图中灰色的是新段,新段还未从内存(操作系统文件缓存)刷入到硬盘。但是他依据是可检索的了(Searchable)
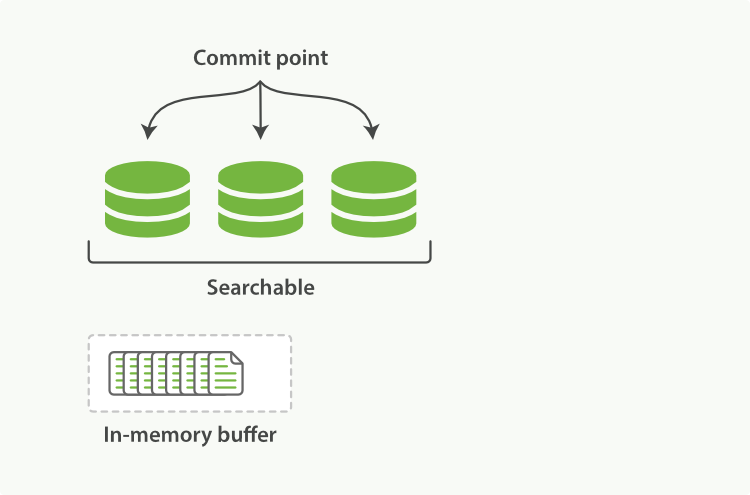
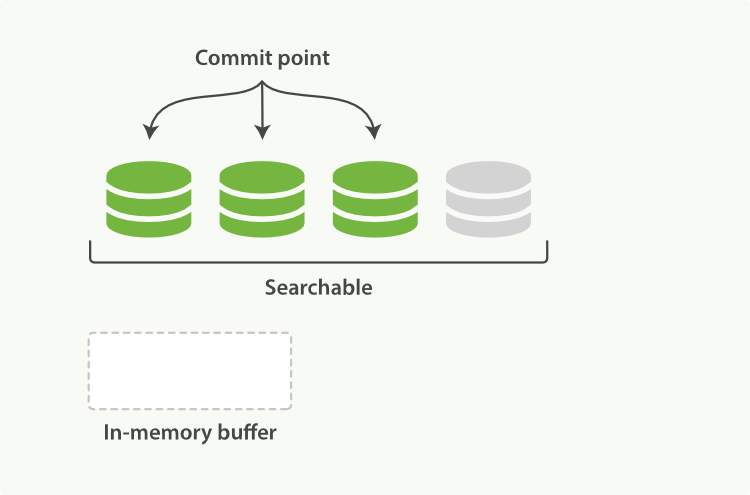
官方提供 refresh 操作,将内存中的文档制作成新段,写入到操作系统缓存中(注意不是 flush 操作)
值得注意的是,对于对实时性要求不高的搜索,可以降低 refresh 的频率,默认是每 秒中 refresh 一次,也就是上一秒写入,下一秒就可检索。
refresh频率可以手动设置,当然也可以手动 refresh。
假如对实时性不高,但是数据量大的话,就可以降低频率,从而充分使用 ES 的文档内存缓存
3.持久化
我个人觉得持久化其实套路都差不多;1是用日志的硬盘顺序写代替离散写;2是将只有部分内容,比较小的日志频繁刷盘,或者在事务完成的时候刷盘,保证落盘,保证数据物理安全,并且使用一个 检查点去做为恢复起点。
ES 使用的策略是 使用类似 Mysql redolog 的 Translog,功能差不多。
ES 每次提交的时候都会生成一个 commit point,Mysql 在内存中脏数据页刷回硬盘的时候也会产生一个 checkpoint。这两个点都是恢复点。
Translog 的刷盘频率默认是 每5秒一次,可以改成每次索引文档的时候就刷盘。上面提到的refresh并不会让 Translog刷盘,只是把文档内存缓冲区的内容制作成
新段放入 os cache。
官方把Translog 的 刷盘 称为 flush:
将文档缓冲区的文档做成新段写入 os cache
清空文档缓冲区
产生新的 commit point 写入 os cache
调用 fsync 将 尚在os cache 中的新段 和 Translog 刷入硬盘,落盘完毕。
4.段合并
是追加型日志的老套路,redis 的 AOF 重写也是如此。本质的问题是 之后的 语句可以和 之前的语句合并成实际占用物理空间更小的结果
比如之前新增 A 记录,后来修改 A 记录,然后删除 A 记录。AOF 重写之前需要记录这三条操作,但是重写合并之后,这条操作就不存在了,所以不需要空间记录 A 留下过的痕迹。
ES 也是如此,对于删除的段,不会出现在合并之后的段中(未证明被更新的旧段是否会删除,理论上会)
段这个单位需要耗损一定的物理资源 占用一定的物理时间,将属于多个段的内容合并成一个段可以达到清洁的效果。
并且检索的时候,也是以段为单位 访问的,所以合并段有助于性能提升