仅供参考,如有不妥之处,请多指正
在网上看到许多博客说 java 的 volatile 修饰的 double 和 long 在 32 位机上也是保证原子性的。
但是没有说明为什么,怎么具体实现,是使用互斥量吗,但是要访问的 volatile 修饰的 long,double 变量的地址是随机的,而且数量可能很多
难道要给他们每人配一把 互斥量?就算真的配上,互斥量是需要一个资源变量来模拟资源数(至少32位)的,每次变量的读写都要为他分配至少32位的内存,而且因为不知道这个变量什么时候死亡,互斥量也无法被得知什么时候要回收,上述情况几乎不可能。
于是作者就去下载了 32位 机上的 Hotspot,重点查看 32 位的 X86 体系 和 ARM 体系中的实现
1.先查看 ARM体系
在 srccpuaarch32vm emplateTable_aarch32.cpp 文件中,找到 putfield_or_static 这个方法,这个方法中是具体的java写入某个域(实例的或静态的,差别不大,实例的是oopDesc,静态的是 javaMirror,也是给oopDesc,简单来说就是 他们都是一块内存),
找到负责 long 型写入的汇编,查找方法是根据栈顶缓存类型(long type top of stack caching,简称 l tos)
作者在注释上写了
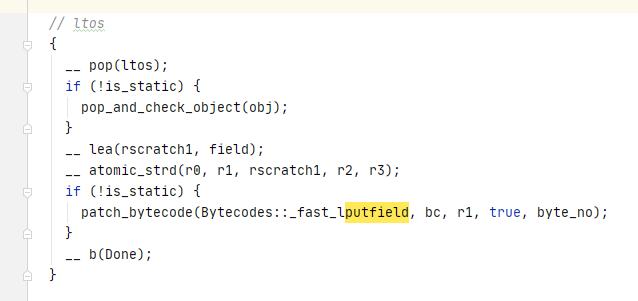
第一行的 pop 只是将操作数栈 栈顶的值,pop 到 rax 寄存器,rax 寄存器中的值是要写入到对应 long 变量内存里的
第二行是查看是否是 写静态变量,如果不是,则需要将 被修改的实例的地址 pop 到对应寄存器
第三行是取这个变量的偏移量,准备写入
第四行是原子性地将 64 位的 long 写入到对应地址中
着重讨论atomic_strd 这条语句
这条语句 根据 ARM 不同平台选用的指令集,去使用不同的汇编指令
在多核情况下,并且在 一般的 ARMV7 或者 ARMV6K 下,使用的是 ldrexd 和 strexd 这两条指令
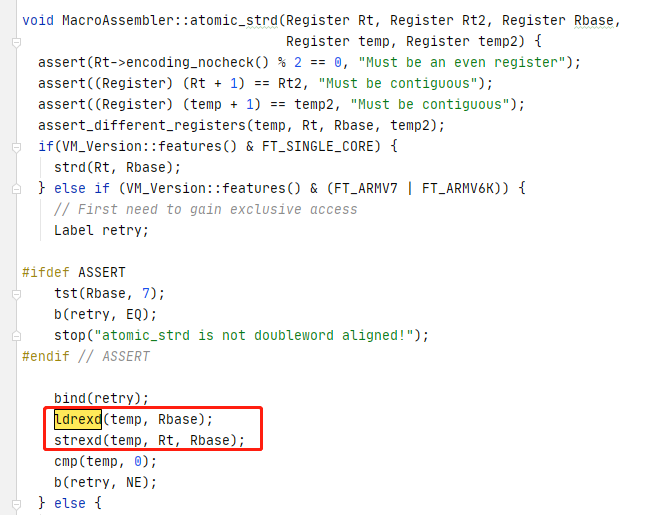
使用 ldrexd 和 strexd 则相当于一种 预定-修改操作
首先是 CPU 的架构,在 ARM 中,有 本地监视器 和 全局监视器

ldrexd Rx , Ry 会把 Ry 中地址 指向的 内存值读出来保存在 Rx 寄存器中,Rx 在此处是 R3 寄存器,如果该变量是当前CPU独享的,则在本地监视器写下“自己要更改”这一预定记录,如果变量是共享的,则在本地监视器和全局监视器都要写上。
ldrexd:(load register double words)
着重讨论共享变量:
strexd Rx, Rm, Ry 会先检查全局监视器中自己写入的预定记录是否还存在,如果存在则把 Rm 中的内容写入到 Ry 指向的地址中去,并且将 Rx 清0,并且将全局监视器上的所有CPU对该变量 的预定记录删除。
strexd:(store register double words)
所以对于全局变量,如果全局监视器中自己写入的预定记录已经不存在了,说明有其他CPU已经写入过了,则需要重试。

strexd 下的 cmp 就是检查 temp ,也就是 Rx 是否已清除,也就是是否写入成功,如果不成功则重试。
这里的 temp 相当于 Rx 寄存器,实际传入的是 ARM 的 R3 寄存器
Rt 相当于 Rm,实际传入的是 R0 寄存器
作者没有解开的疑问:R0~R3 寄存器在32位 ARM 都是 32 位的,怎么能容得下 64 位的 double words ?32 位机下 一个word 32 位
也就是,strexd 和 ltrexd 是用于 64 位寄存器的,但是 R0 和 R3 都是 32 位的。具体可能还要深入研究硬件架构。
最后要说的是,在 ARM 中,无论是否是 volatile 修饰的 ,long 和 double 都要使用 上述的 ldrexd 和 strexd,所以可以猜测,在 ARM-32 下的hotspot,就算对 long 和 double 不加 volatile 也可以保证写入的原子性(未证实)。
2. X86 体系
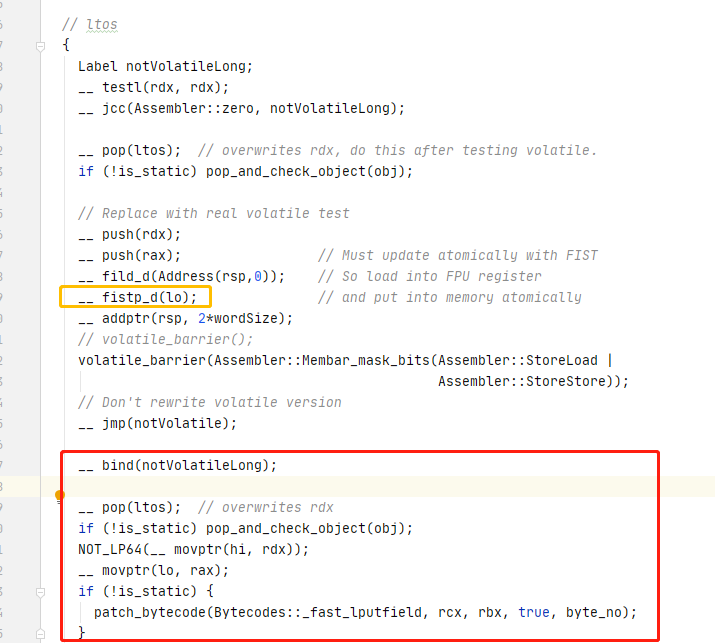
用的是fistp_d语句,生成的汇编为:

这里用到的是硬件堆栈,也就是寄存器堆栈
在X86中,浮点寄存器堆栈中除了状态寄存器,其他寄存器可达80位,大于64位
![]()
在X86下,使用浮点寄存器来达到原子性地对 内存中的 64 位进行操作。
值得注意的是,如果不是volatile 修饰,会跳到 上图的红色框,bind(地址) 是 hotspot 中向 CodeBuffer 写入汇编的一种特殊写法
如果使用 jmp(地址),则会跳到 bind 对应的位置上。
如果不是64位机,则先对 高32位部分写入,然后再对 低32位写入。如果是64位机,则写入一次即可(第二句)

所以在X86下,如果不用volatile 修饰 long 或者 double ,在并发清空下,可能引发一个线程修改了高32位,其他线程读到新的高32位,旧的32位的问题。