Hive的hql注意事项
1、使用分区裁剪,列裁剪
在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤,
SELECT a.id
FROM lxw1234_a a
left outer joint_lxw1234_partitioned b
ON (a.id = b.url);
WHEREb.day = ‘2015-05-10′
使用SELECT a.id
FROM lxw1234_a a
left outer joint_lxw1234_partitioned b
ON (a.id =b.url AND b.day = ‘2015-05-10′);
或者直接写成子查询:
SELECT a.id
FROM lxw1234_a a
left outer join(SELECT url FROM t_lxw1234_partitioned WHERE day = ‘2015-05-10′) b
ON (a.id = b.url)
这两者的效果相同
列裁剪就不会导致全表扫描
2、少用COUNTDISTINCT
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换:
SELECT day,
COUNT(DISTINCT id)AS uv
FROM lxw1234
GROUP BY day
可以转换成:
SELECT day,
COUNT(id) AS uv
FROM (SELECTday,id FROM lxw1234 GROUP BY day,id) a
GROUP BY day;
虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
还有就是distinct会多启动一个job,如果不是有意义的distinct的就不要使用
3、是否存在多对多的关联
只要遇到表关联,就必须得调研一下,是否存在多对多的关联,起码得保证有一个表或者结果集的关联键不重复。
如果某一个关联键的记录数非常多,那么分配到该Reduce Task中的数据量将非常大,导致整个Job很难完成,甚至根本跑不出来。
还有就是避免笛卡尔积,同理,如果某一个键的数据量非常大,也是很难完成Job的。
关联键请参考后面的join详解
4、合理使用MapJoin
参考后面的join详解
5、并行执行job
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。
子查询并行也可以提供并行度,前提是资源足够
数据倾斜的处理
导致数据倾斜的操作GROUP BY, COUNTDISTINCT, join
原因:key分布不均匀、业务数据本身特点
办法:
1、 使用COUNT DISTINCT和GROUP BY造成的数据倾斜:
存在大量空值或NULL,或者某一个值的记录特别多,可以先把该值过滤掉,在最后单独处理:
多重COUNT DISTINCT,通常使用UNION ALL +ROW_NUMBER() + SUM + GROUP BY来变通实现。
2、使用JOIN引起的数据倾斜关联键存在大量空值或者某一特殊值,
如”NULL”空值单独处理,不参与关联,空值或特殊值加随机数作为关联键;
不同数据类型的字段关联转换为同一数据类型之后再做关联
3、控制Map数和Reduce数
a、控制hive任务中的map数
不是map越多越好也不是越少越好,小文件太多导致map太多,从而map的启动和初始化时间远远大于逻辑处理时间,就会造成资源的浪费
也不是map的处理的文件越接近128M越好,如果map处理的业务逻辑过于复杂,就会比较耗时,
所以针对小文件个数比较多就要合并小文件,减少map个数
在map执行前合并小文件,减少map数,方法如下:
set mapred.max.split.size=100000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
再执行上面的语句,用了74个map任务,map消耗的计算资源:SLOTS_MILLIS_MAPS= 333,500
对于这个简单SQL任务,执行时间上可能差不多,但节省了一半的计算资源。
大概解释一下,100000000表示100M, sethive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;这个参数表示执行前进行小文件合并,
前面三个参数确定合并文件块的大小,大于文件块大小128m的,按照128m来分隔,小于128m,大于100m的,按照100m来分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),
进行合并,最终生成了74个块。
遇到文件比较大且处理逻辑复杂时,适当增加map个数
Select data_desc,
count(1),
count(distinct id),
sum(case when …),
sum(case when …),
sum(…)
from a group by data_desc
如果表a只有一个文件,大小为120M,但包含几千万的记录,如果用1个map去完成这个任务,肯定是比较耗时的,这种情况下,我们要考虑将这一个文件合理的拆分成多个,
这样就可以用多个map任务去完成。
set mapred.reduce.tasks=10;
create table a_1 as
select * from a
distribute by rand(123);
这样会将a表的记录,随机的分散到包含10个文件的a_1表中,再用a_1代替上面sql中的a表,则会用10个map任务去完成。
每个map任务处理大于12M(几百万记录)的数据,效率肯定会好很多。
控制map数量需要遵循两个原则:使大数据量利用合适的map数;使单个map任务处理合适的数据量;
b、控制hive任务的reduce数
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1)
调整reduce个数的方法
1、调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
2、set mapred.reduce.tasks = 15;
reduce个数并不是越多越好
以下情况会出现不管怎么都只会有一个reduce的情况
1、没有group by的汇总,比如把select pt,count(1) from popt_tbaccountcopy_mes where pt =‘2012-07-04′ group by pt; 写成 select count(1) frompopt_tbaccountcopy_mes where pt = ‘2012-07-04′;
2、用了Order by。会进行全表的统计
3、有笛卡尔积
详解hive的join
Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join)。本文简单介绍一下两种join的原理和机制
Hive中Join的关联键必须在ON ()中指定,不能在Where中指定,否则就会先做笛卡尔积,再过滤。
1、Hive Common Join
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join.
整个过程包含Map、Shuffle、Reduce阶段。
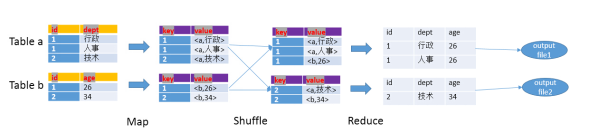
- Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
按照key进行排序
- Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
- Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
- 以下面的HQL为例,图解其过程:
- SELECT
- a.id,a.dept,b.age
- FROM a join b
- ON (a.id = b.id);
2、Hive Map Join
MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。
Hive0.7之前,需要使用hint提示 /*+ mapjoin(table) */才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true.
仍然以9.1中的HQL来说吧,假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为MapJoin。
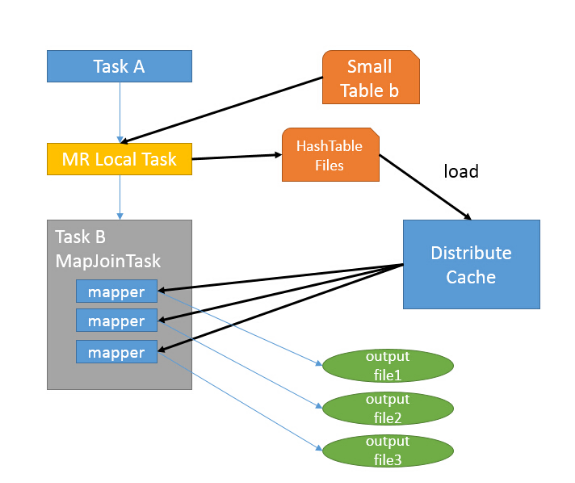
- 如图中的流程,首先是Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中
- 接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
- 由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件。
mapjoin比common join多了一步,首先启动了一个本地的Map Reduce作业,读d表,
然后启动了一个非本地的Map Reduce作业,是一个真实的Map操作,读e表,
然后并没有启动真实的Reduce操作,而直接在Map端进行了join操作,最后展示数据。
使用优化器将commmon join 优化成mapjoin,省掉了Reduce操作,效率更高。
count() count(if) count(distinct if) sum(if)的用法和区别
博客地址https://www.cnblogs.com/zzhangyuhang/p/9799303.html
如:
--初步统计域名数据到临时表中
INSERT OVERWRITE TABLE tmp.tmp_table_arch_50x_report_access_${date}
SELECT host,count(1) AS req_cnt,
sum(if(status in (500,502,503,504),1,0)) as error_cnt
from ods.ods_table_log_vps_ngx_access
where dt="${date}"
GROUP BY host
采用这种方式不用group by两个字段,并且可以统计出来