一、说明
本文的直接起因是上周公司的一个比赛用到了排列组合,之前没用过,这里记一记。
本文说的排列组合是借助itertools实现,而不是自己写代码实现。
itertools的其他一些函数还是比较有意思的,所以在最后也会做下简单的介绍。
二、排列组合实现
| 功能需求 | 总数算法 | 实现函数 | 示例 | 示例输出 |
| 元素可重复使用的排列 | n的m次方 | product(*iterables, repeat=1) | product('ABCD', repeat=2) | AA AB AC AD BA BB BC BD CA CB CC CD DA DB DC DD |
| 元素不可重复使用的排列 | A n m | permutations(iterables, r=None) | permutations('ABCD', 2) | AB AC AD BA BC BD CA CB CD DA DB DC |
| 元素可重复使用的组合 | C n m + n | combinations_with_replacement(iterable, r) | combinations_with_replacement('ABCD', 2) | AA AB AC AD BB BC BD CC CD DD |
| 元素不可重复使用的组合 | C n m | combinations(iterable, r) | combinations('ABCD', 2) | AB AC AD BC BD CD |
说明:
1. 上边函数的第一个参数iterables表示可迭代的对象,包括字符串、列表等等。所以排列组合的元素如果不是字母而是字符串也是可以的,如permutations(['AB', 'CD', 'EFG'], 2)。
2. 上边函数的第二个参数都是参与排列组合的元素个数。
三、itertools其他函数
3.1 无穷类函数
| 功能 | 实现函数 | 示例 | 示例输出 |
| 从某个数开始,按给定步长一直数下去 | count(start=0, step=1) | count(10, 2) | 10 12 14 ... |
| 不断循环输出给出的元素 | cycle(iterable) | cycle('ABC') | A B C A B C ... |
| 不断重复/重复给定次数给定元素 | repeat(object[, times]) | repeat(10, 3) | 10 10 10 |
3.2 分组遍历函数---groupby()
假设我们有一个如下字典组成的列表,列表中每个字典记录了每个学生的一门课程成绩,在遍历时我们想先打印A同学的各科成绩,再打印B同学的各科成绩。这时就可借助groupby()函数实现这个需求。


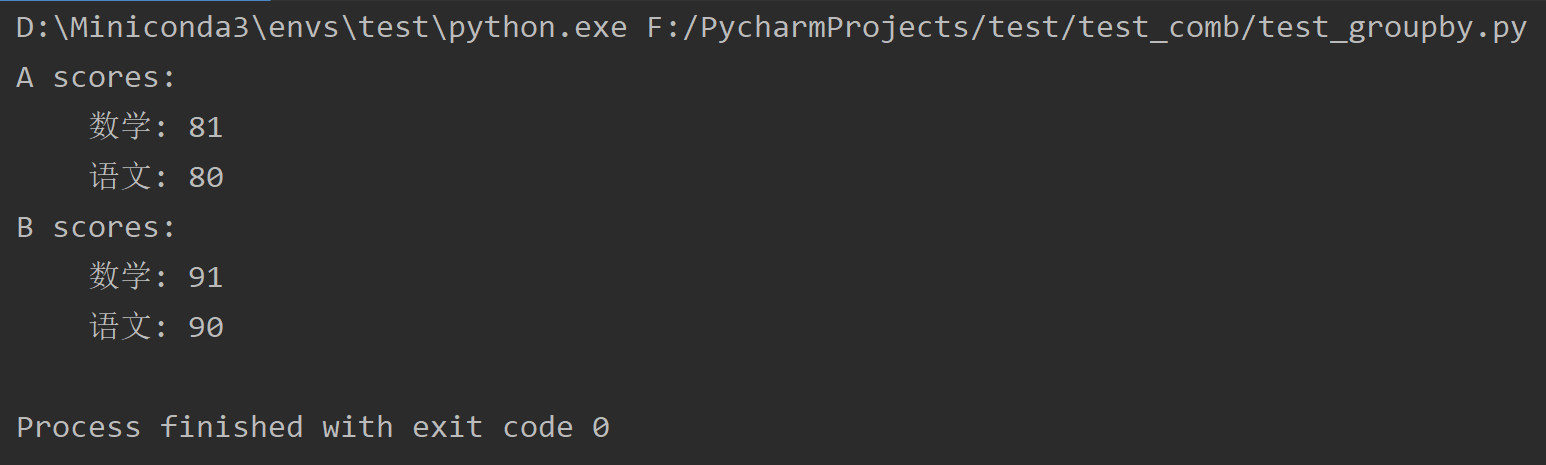
from itertools import groupby student_score_dict_list = [ { "student_name": "A", "course_name": "语文", "scores": 80 }, { "student_name": "B", "course_name": "数学", "scores": 91 }, { "student_name": "B", "course_name": "语文", "scores": 90 }, { "student_name": "A", "course_name": "数学", "scores": 81 }, ] # 定义一个函数,这个函数的作用是传给他一个值,它返回代表这个值的值或表表参与比较等操作 # 如果是列表那就先按第一个排,第一个值相同再按第二个值排 # 用lambda表达示还是用def效果一样的 # 排序使用的选取代表值的方法,我们先以学生名排序,再以课程名排序 # 这里有点小尴尬的是在编码上“数学”比“语文”小,所以“数学”会排前面;如果是数值可以在前面加个负号,字符串还不好处理 sort_key_func = lambda x: (x["student_name"], x["course_name"]) # 分组时使用的选取代表值的方法,我们先以学生名进行分组 groupby_key_func = lambda x: x["student_name"] sorted_student_score_dict_list = sorted(student_score_dict_list, key=sort_key_func) groupby_student_score_dict_list = groupby(sorted_student_score_dict_list, key=groupby_key_func) for student, one_student_score_dict_list in groupby_student_score_dict_list: print(f"{student} scores: ") for student_score_dict in one_student_score_dict_list: print(f" {student_score_dict['course_name']}: {student_score_dict['scores']}")
实现效果如下:
参考:
https://docs.python.org/3/library/itertools.html#module-itertools