//事务处理不管如何,必定要获得事务是否正确的标志,还要根据标志执行或回滚。
// 1.如sqllite这里到最后设置成功标志,并且无论如何会执行db.endTransaction();来进行判断,执行还是回滚。
//2.还有mysql ,最后几条语句直接根据系统的错误标志来进行判断执行还是回滚。
进程和线程
所有的一切的根源是cpu太快。其他慢资源,如显卡,声卡等,更别说人类的操作,显得是蜗牛的速度, 所以让人类同时发出命令。 如阻塞了声卡,那么让不需要声卡的进程用下cpu跑下。
所以划分内存,划分现场。来执行不同的程序。让人看起来是同时执行。这就是进程。分配了内存和cpu,这就是所谓进程是资源分配的最小单位
而cpu还是太快,进程有时候会阻塞(等待网络或其他资源),就算有多个,但是cpu实在太快。很多进程同时执行,在cpu看来,还有很多时间是在空转。
而可以配合cpu把资源利用起来的有一个是内存。 内存一般不会用满。所以cpu+内存。这个组合可以把cpu有效的利用起来,
所以进程可以开多个线程,尤其是单核时代,在等 IO 的时候,一般会手动开一个线程。利用cpu和内存来计算。
而到了多核时代,开线程就非常必要了。从硬件上面cpu直接开挂了。同时运行。
所以线程是CPU调度的最小单位,在进程中随便开几个线程是没有问题的。
开线程后你把程序还理解为在一个线程在运行也是可以的。只要注意把内存保护好就可以。线程间没有任何内存隔离保护的。
所以如果要安全的话:
共享数据建议必须都用类封装。提供方法。可以清晰在多线程环境下进行。可以考虑定义一个接口类,所有进程的参数必须实现这个接口。就可以了。哈哈。而且进一步定义一个线程的接口类ithread。规定参数。
程序中必须使用 实现了ithread的线程。
可以隐喻为一个厉害的导演同时导演几部不同风格的电影。而且导演在拍一个电影的同时,变拍戏边炒菜。边说这个演员往里走走,边给炉子加火。 只要注意炒菜别用到剧组资源,否则加个锁,让剧组和导演线性使用炉子。
不同风格的电影就是不同的进程,吵菜等就是线程,炒菜不利用剧组紧张资源。
for 用于循环次数不变,而且最好从0开始,任何时候都表示次数,和逻辑不挂钩。需要反序的话,自己用大数减i,
次数变化的用while处理。逻辑更简洁。i就表示具体的业务数值了。
//recursion 和 循环的区别,除了性能和简洁之外。
//recursion 还可以有一个回退上层的动作。如果需要回退上层再做一点事情,特别是必须从底往上的工作。那么recursion是非常合适的。联想到平衡树的插入之后检查平衡的操作。
//如果不需要回退做任何工作。也就是尾递归。那么就用循环。
关于尾递归的详细介绍:
https://baike.sogou.com/v162175.htm?fromTitle=%E5%B0%BE%E9%80%92%E5%BD%92
要满足
1.递归在最后的语句,并且无任何动作。
2.即回归无动作,因为循环是前进的,无法回撤到中途某现场。
具体可以看链接的例子。来思考1*2*3*4*5 的一般递归写法和尾递归写法。一般写法是到最后一层才开始计算。而尾递归是中途就开始计算。到最后一层计算完毕。直接返回,重点,直接返回最终结果了。
return MyArrayList.this.theData[Index++];
是一个很好的后++的例子。next 需要返回某个item后,自动移动当前索引哨兵。 也说明了没有太多东西是必要的。但是掌握后,可以简洁有效。
//基于栈的特点和堆的特点,决定了,在函数内部是否需要new.
//清栈是函数离开自动清,所以尽量用栈.但是共享数据必须new,如给多个类使用(一般共享指针).
//栈大小默认都不大.小于1m.因此,大数据,如稍大的数组,必须new(一般共享指针).
//编译器要求入栈必须确定栈的大小.可变的数组也必须new(一般用vector,数据是堆中的)
//由以上几点,可推导出特殊需求,如共享一个可变数据.那么就是vector的共享指针.
//同理在类内部,由于不能确定类对象是否会被new,还是在栈中.也要避免栈的缺点.
//共享数据必须在外部new,类只需要包含指针。
//稍大的数组,必须new,析构函数delete
//可变的数组也必须new(一般用vector,数据是堆中的)
//如果是类内部new,那么必须析构delete
//一些外部api,一般需要的是指针,是堆指针还是栈指针,还是依据上面原则。
//有一些特殊,如这个api,是一个异步的处理。异步的回调,又传出了这个指针,那么必须是new,要是堆中的。
1,windows下 ,c++ , ,其实还是会插入
2.
因为系统提供的默认拷贝构造函数工作方式是内存拷贝,也就是浅拷贝。如果对象中用到了需要手动释放的对象,则会出现问题,这时就要手动重载拷贝构造函数,实现深拷贝。
下面说说深拷贝与浅拷贝:
浅拷贝:如果复制的对象中引用了一个外部内容(例如分配在堆上的数据),那么在复制这个对象的时候,让新旧两个对象指向同一个外部内容,就是浅拷贝。(指针虽然复制了,但所指向的空间内容并没有复制,而是由两个对象共用).
2.int out 的参照物的内存。所以out 是从内存写入到输出设备。 in是从外部读入到内存。
int main()
{
sales lulu=sales();
sales fun();// 从语法上看是定义了一个名为fun,返回值为sales的无参数函数。
sales lulu2=fun();
sales lulu3;
cout<<lulu.GetSalary()<<endl;
cout<<lulu2.GetSalary()<<endl;
cout<<lulu3.GetSalary()<<endl;
//lulu.Getjob(1000,3000);
return 0;
}
sales fun()
{
sales a;
return a;
}
声明为explicit的构造函数不能在隐式转换中使用
对比一下blockcode 和手工编译的命名就可以知道以后怎么处理了。
构造函数的,初始化的参数是输入构造参数的,不是说里面生成一个对象,在复制过去。
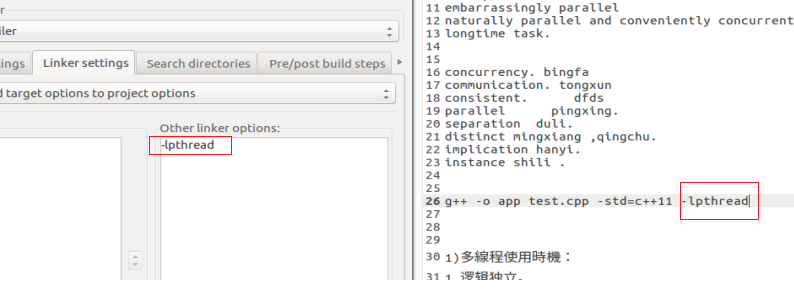
//多线程。
1)共享数据建议必须都用类封装。提供方法。可以清晰在多线程环境下进行。
3)
socket 是双向通讯
#include <sys/types.h> #include <sys/socket.h> #include <stdio.h> #include <stdlib.h> #include <error.h> #include <string.h> #include <unistd.h> #include <iostream> using namespace std; int main() { int status; int socketNo[2]; status=socketpair(AF_LOCAL,SOCK_STREAM,0,socketNo); if(status==-1) { //printf("error:%s",strerror(errno)); printf("hihi"); } else { cout<<socketNo[0]<<socketNo[1]<<endl; } status=write(socketNo[1],"hi",2); if(status==0) { cout<<"error wirte"<<endl; } else { cout<<status<<endl; } char readStr[10]; status= read(socketNo[0],readStr,10); if(status==0) { cout<<"error wirte"<<endl; } else { readStr[9]=0x0; cout<<readStr<<endl; } status=write(socketNo[0],"hi, tow",10); if(status==0) { cout<<"error wirte"<<endl; } else { cout<<status<<endl; } status= read(socketNo[1],readStr,10); if(status==0) { cout<<"error wirte"<<endl; } else { readStr[9]=0x0; cout<<readStr<<endl; } status= read(socketNo[1],readStr,10); if(status==0) { cout<<"error wirte"<<endl; } else { readStr[9]=0x0; cout<<readStr<<endl; } close(socketNo[0]); close(socketNo[1]); }
利用socket编程。如果使用tcp/ip协议栈,不需要考虑数据丢失,重复,顺序,和溢出。onreceive 原则上是接受完了一个发送,才会给系统的。所以丢包不是上层程序会接触到的。
几本好书, 汇编原理, unix网络编程.effect c++.简明,详细又深入.
1)socket下(短连接)一般编写思路顺序。
1.对象成员数据和方法。 涉及的收发消息格式。send并shutdown.
2.后台线程的方法,涉及的收发消息格式。send并shutdown.
3.非阻塞下io的接收,涉及的收消息格式。receive 并function .
2)socket 下排错。
1.先检查客户和服务端的内存数据。
2)再查看socket的收发状态。
要这样
vector<Book> mybooks=bookManager.GetmyBooks();
vector<Book>::iterator ret= MyFind(mybooks.begin(),mybooks.end());
千万不能.
vector<Book>::iterator ret= MyFind(bookManager.GetmyBooks().begin(),bookManager.GetmyBooks().end());
mysql
PK:primary key 主键
NN:not null 非空
UQ:unique 唯一索引
BIN:binary 二进制数据(比text更大)
UN:unsigned 无符号(非负数)
ZF:zero fill 填充0 例如字段内容是1 int(4), 则内容显示为0001
AI:auto increment 自增
g:所谓Cenerated Column,就是数据库中这一列由其他列计算而得
MySQL 数据类型中的 integer types 有点奇怪。你可能会见到诸如:int(3)、int(4)、int(8) 之类的 int 数据类型。刚接触 MySQL 的时候,我还以为 int(3) 占用的存储空间比 int(4) 要小, int(4) 占用的存储空间比 int(8) 小。
后来,参看 MySQL 手册,发现自己理解错了。
| 代码如下 | 复制代码 |
|
int(M): M indicates the maximum display width for integer types. |
|
在 integer 数据类型中,M 表示最大显示宽度。
原来,在 int(M) 中,M 的值跟 int(M) 所占多少存储空间并无任何关系。 int(3)、int(4)、int(8) 在磁盘上都是占用
4 btyes 的存储空间。说白了,除了显示给用户的方式有点不同外,int(M) 跟 int 数据类型是相同的。
另外,int(M) 只有跟 zerofill 结合起来,才能使我们清楚的看到不同之处。
| 代码如下 | 复制代码 |
|
mysql> drop table if exists t; mysql> select * from t; mysql> alter table t change column id id int(3) zerofill; mysql> select * from t; mysql> mysql> select * from t; mysql> mysql> select * from t; |
|
从上面的测试可以看出,“(M)”指定了 int 型数值显示的宽度,如果字段数据类型是 int(4),则:当显示数值 10 时,在左边要补上 “00”;当显示数值 100 是,在左边要补上“0”;当显示数值 1000000 时,已经超过了指定宽度“(4)”,因此按原样输出。
在使用 MySQL 数据类型中的整数类型(tinyint、smallint、 mediumint、 int/integer、bigint)时,非特殊需求下,在数据类型后加个“(M)”,我想不出有何意义。
下面补充一下数据类型
1、整型
| MySQL数据类型 | 含义(有符号) |
| tinyint(m) | 1个字节 范围(-128~127) |
| smallint(m) | 2个字节 范围(-32768~32767) |
| mediumint(m) | 3个字节 范围(-8388608~8388607) |
| int(m) | 4个字节 范围(-2147483648~2147483647) |
| bigint(m) | 8个字节 范围(+-9.22*10的18次方) |
取值范围如果加了unsigned,则最大值翻倍,如tinyint unsigned的取值范围为(0~256)。
int(m)里的m是表示SELECT查询结果集中的显示宽度,并不影响实际的取值范围,没有影响到显示的宽度,不知道这个m有什么用。
2、浮点型(float和double)
| MySQL数据类型 | 含义 |
| float(m,d) | 单精度浮点型 8位精度(4字节) m总个数,d小数位 |
| double(m,d) | 双精度浮点型 16位精度(8字节) m总个数,d小数位 |
设一个字段定义为float(5,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位。
3、定点数
浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值。
decimal(m,d) 参数m<65 是总个数,d<30且 d<m 是小数位。
4、字符串(char,varchar,_text)
| MySQL数据类型 | 含义 |
| char(n) | 固定长度,最多255个字符 |
| varchar(n) | 固定长度,最多65535个字符 |
| tinytext | 可变长度,最多255个字符 |
| text | 可变长度,最多65535个字符 |
| mediumtext | 可变长度,最多2的24次方-1个字符 |
| longtext | 可变长度,最多2的32次方-1个字符 |
5.一个大坑。
使用类库,类库尽量不要存在静态变量。非要使用,静态变量的定义在类库项目中。
尽量在大思路,大框架基本无盲点后开始项目开发。
选择方案时,尽量模拟2个方法的得失,最关键是必须验证可行。有时候冗余的方案,对于逻辑上反而更简洁。
如果时间紧迫,也必须在开发模块时,
1)把模块的输入,输出压缩到最小,
2)复杂的需求,分开做出几个模块,不要做大而全的模块。特别是在需求会变或全新的项目下。
保证项目过程中的思路,框架的变更后,原有模块可以完美适用。
不然,修改模块是一个很耗费时间和测试的工作。切记!!!!!!!!!!!!!!!!!!!!!!!!!!!
写模块时,先从主输入输出模块写起。回调或委托先写好,这样,功能铺开时,才好处理。各功能间的接口,参数就好确定。
目的:有时候有些情况比较复杂,写完了代码。也没法确定是否完全正确。画图感觉比较复杂,只能靠测试。这个时候使用状态机分析法。就能比较好。
所以最佳实践:对象的创建,必须明确,仅仅是局部使用,还是会传出去,局部使用,就可以直接在栈中,如果会传出去(或返回,或包含在返回对象中),必须传递对象,或者堆中的地址(智能指针)
修改一些bug,或添加新功能时候,非常有必要一个一个来完整的修改测试。不然,一遍一遍的检查是否完成, 修改完一个更新一个。难得可以先跳过。但不要做到一半!!!!!!!!!,切记。
不管是模块设计,还是类规划,还是小功能策划,必须画图。就算是几个方法的结合也必须画图。画图可以让思路请i下。切记。queryreport的教训。
按常理,一般半个工作日 可以整理 2天左右的代码,大概10个左右方法。所以20!30个方法间的代码,需要3天左右。别太盲目在紧急时重够代码。又是血的教育。一定要做好单元测试。这样才是bug的保障。
内存对齐:
3规则
:第一个从0开始。
二:每个从自身的整数倍开始。
三,最后收尾按最大的类型的整数倍。
所以感觉随意一点就只要先写最小的。大的放最后,非要完全节省,就要细细摆了。感觉这个是编译器的事情。不用太关注。
- class S
- {
- int i;//0.3 第一规则
- short s[5];//4.13
- char c;//14 补 到4的倍数, 14-15第三规则
- };
- class D
- {
- char c0;//0-0
- double d[3];//8-31第二规则
- char c;//32 补 到8的倍数, 32-39第三规则
- };
文件的操作。
常用就3种模式
附加:fstream fs(filepath.c_str(),ios_base::app|ios_base::out);
覆盖:fstream fs(filepath.c_str(),ios_base::out);
读起: ifstream fin; fin.open(filepath.c_str(),ios::in);
二维数组
int rows=5; int column=6; int **array3=new int*[rows]; for(int i=0;i<rows;++i) { array3[i]=new int[column]; } array3[2][3]=5; for(int i=0;i<rows;++i) { delete[] array3[i]; } delete[] array3; int* array2=new int[rows*column]; array2[0]=1; array2[0+1]=2; array2[1+0]=2; for(int i=0;i<rows;++i) { for(int j=0;j<column;++j) { cout<<i*column+j; array2[i*column+j]=i*10+j; } cout<<endl; } for(int i=0;i<30;++i) { cout<<array2[i]<<endl; } delete[] array2;
位运算符作用于位,并逐位执行操作。&、 | 和 ^
& 同时为真
| 有一个为真 : 更改某位值为1
2个不同且有一个为真。 :更改某位值为0
注意到一个使用指针的指针的场景。
系统或基础类会生成一个指针,并且自己要使用到它。而使用者需要这个指针,那么可以设置一个出参,为指针的指针,来获取。这样就比较安全,简便。
1。千万不要返回局部对象的引用
2.在类的成员函数中,赋值可以返回*this.因为赋值是a=b。a是左值,是一定存在且this是隐指针参。
3.如ostream& operator<<(ostream& os,const compleNumber& complexNumb), 可以返回 os。
因为 cout<<b. cout是操作符左值,是一定存在的 且os是引用参数。
4。char& Mystring::operator[](unsigned int index)
这里也是一样。this是隐指针参。
综合所述,返回引用,一般是返回一个 引用参数,或指针参数 的全部或部分,或者局部静态变量。
本质就是要求返回的对象,离开函数后是否还存在。存在才可以用引用。
1.
依赖倒置的理解:
按照直觉,是先写个具体方法,再在上层调用这个方法。
而依赖倒置就是先写上层方法。而具体方法可以先不写,直接先用个抽象代替。
这个和事件驱动编程,就是一样思维啊。
大部分的模式都是用了抽象的思想。抽象才是根本。
2.winform 第一个类不是页面类,会打不开设计器。
移动第一个 非页面类到后面。 是否ok了。否则 把输入的下拉。从编译改外无,再改为编译,看看是否会重新加载设计器。
public FPSProcess()
{
preTime = System.DateTime.Now;
}
public DateTime preTime = System.DateTime.Parse("1982-01-02");
可以发现c#中,定义式居然比构造函数还早执行。这个。。。。
可以理解为c# ,一旦确定某个内存是什么数据,之后马上在内存中放置默认值, 之后再执行 定义式和 构造函数。
所以会浪费几条指令,但是保证了数据的类型正确。
所以最ok的做法还是任何类都定义默认的构造函数。而不放在定义式中。
后面发现和java是一样的。构造函数会覆盖定义。
4)第四个是模板,初写模板,以为只是一套代码的抽象。非常粗浅的看了c++的iterotarstl代码,自己感觉原来模板才是真正的面向对象编程。之前真的只是面向类编程而已。继续看下去。看下模板元编程会不会也有思维重大改变。
目前只有一个认识:无需继承也可实现多态。模板是要钱出钱,要力出力,一声令下,提前准备。所以模板会导致代码膨胀。
新的认识:又一次被模板所惊叹,既然是代码生成器,那么对于可调用类型。如方法,防函数等 T(a),模板是不在乎T的类型的,所以一个模板类,可以同时接受函数对象和函数或函数指针。来完成一些可扩展的功能。如泛型算法,就可以接受任何可调用类型。
5)第五个是学习了c++后,再次复习c#,和java后的理解。更工业化的语言类的对象,都已经固定放在 heap中,让人省去实例化后到底放哪里的考虑,一个简单的强制设定,省去了无数的麻烦,自己学c++时,也曾打算这样,和个人想法不谋而合,
完全可以避免栈满的情况,看到类中的非基本数据成员,就知道是指针。而非基本数据成员,它其中的任何非基本数据成员,又一定是指针,非常清晰明白。感觉c#应该也是这样设定的。所有对象都是new出来到堆中。
如果c++自由真的是完美的话,为什么所有公司都要裁剪呢?自由和强制都要把握度。