1.数据类型和类。
所有编程都是处理输入和输出。
关于输入参数,从右至左把参数入栈,这样根据栈基址,可以定位第一个参数。因为很多函数是参数数量不定的,比如printf.
关于输出,记得输出时,一般是把值放入eax 寄存器,
所以一般数据类型,直接放入返回值数据,寄存器可以装下,
而返回对象,会返回对象的指针,并在调用者的栈中,按位复制。之后清栈
而返回指针,会把指针放入寄存器,之后清栈。
所以第一条守则:不要返回或传参为函数局部对象的指针,而是返回局部对象或堆中地址。
隐藏守则:如果是返回一个集合,如vector<>,而里面是指针,就相当于返回了局部对象的指针。
所以最佳实践:
函数中:
对象的创建,必须明确,仅仅是局部使用,还是会传出去,局部使用,就可以直接在栈中,如果会传出去(或返回,或包含在返回对象中,或作为参数),必须传递对象,或者堆中的地址(智能指针)
就算是主函数中,不会清栈的情况下。还是为了语义的正确和统一性已经性能,也必须在堆中申请。
类中:
如果是类中的变量,自己new 了,必须自己delete .如果是指针,由外部传入,那么必须使用智能指针(因为你不确定使用者何时会delete)
一句话,除考虑性能之外,判断是否new,看变量的生存期是本函数,还是超过本函数。
考虑性能,可以对于生存期在本函数类的变量。new 之后再 delete.极端情况是个大数据,而中间还要调用很深的栈。
非常明确的局部使用小对象,小数据,不需要new.否则智能指针吧。
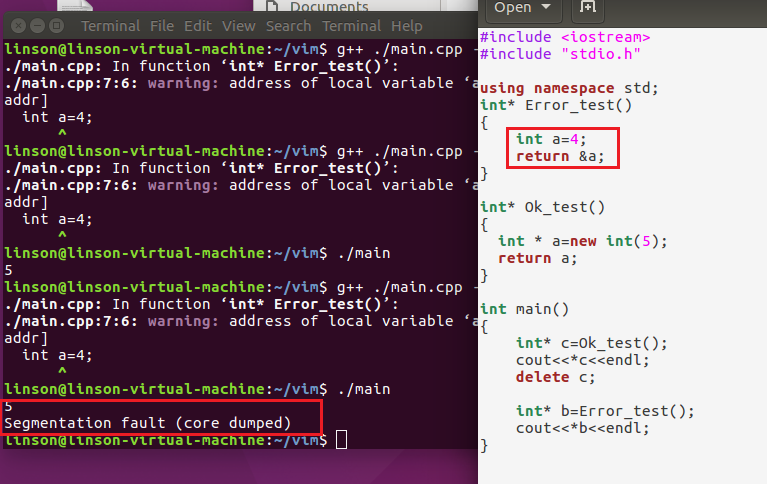
当然根据 raii,用类管理资源的守则,应该写成用类管理资源。
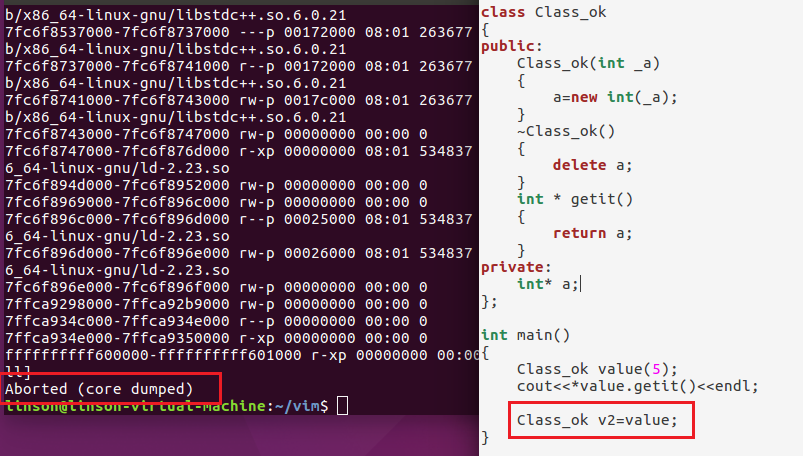
但是默认的复制构造函数是按位复制。所以会出现2次析构。导致错误。
所以1,自定义复制构造函数。
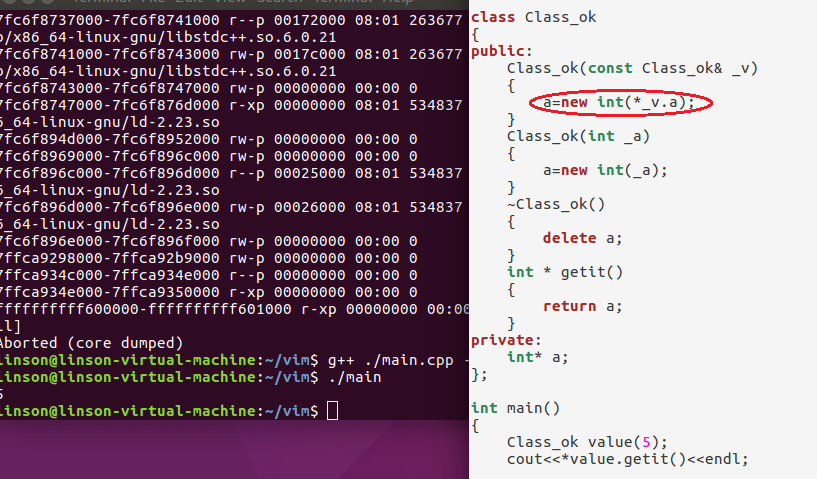
2,使用智能指针。

使用智能指针,就为我们定义了一个根据引数进行的析构函数,只有当引数为0才进行delete 操作。
使用智能指针,就要说到为什么使用指针。必须要使用指针的场合,自己好像只碰到过的,只有在继承场合下。而且此指针需要传递给外部。否则可以局部对象,加&。
所以准则2:当由于继承或其他情况下需要使用指针时,使用智能指针代替原指针。用智能指针这个模板类来管理资源。
再返回去说数据。基本数据没什么好说。int,char,都是定死的资源。对于c来说。使用指针感觉就是为了char *.字符串。
类,只包含基本类型。也没什么好说。复制是成员数据类型按位复制,
如果类包含另外一个类的对象。那么1,为了节省栈空间。可以只包含类的指针。2,同一个对象会被不同的类包含,那么必须使用指针就节省了整个内存。
使用指针,当然就是用智能指针,省去自己处理拷贝构造函数的编写。
根据准则一,不要返回局部变量的指针,我们可以返回局部变量,而继承必须使用指针来表示。所以有一种必须使用new 的场合,就是返回包含派生类指针的集合。
所以目前总结,适合使用到智能指针(指针)的场合:1.继承,2。某个类的对象,会被多个另外不同的对象包含。3.需要作为返回值,而为了性能,可以返回堆中的地址(智能指针)4.容器包含指针,而且作为返回值,必须在堆中new.
所以准则3:
不考虑性能问题,必须使用new,就1种情况,需要返回派生类指针的集合,如 vector<base *> fun (); 那么必须在函数中用new;
考虑性能,使用new,多3种情况。1.返回智能指针,而不是类对象。2.某个类的对象,会被另外类的多个不同的对象包含,那么复合类,采用智能指针,3某个类的成员是个大数据,比如缓存类,必须使用new到堆中,栈放不下。以免使用者,直接
在栈中生成对象。
而使用指针在上面的情况外。就是继承。
2.再谈输入与输出。
所以综合考虑,写函数。除非性能和栈空间的考虑,基本可以不用到new .除非需要返回派生类指针的集合
而使用指针也很有限。1.就是为了多态,使用指针。2.传递指针给函数,函数需要修改数据。
3构造和析构
如上所诉,类中需要使用智能指针成员,就是1,为了多态。2为了性能。
感觉不如用function.
构造函数中不能调用基类的虚构造。
析构函数不让异常逃出。
基类必须实现虚析构。
5.资源管理
6.一般实践:
函数内部变量:
1.非常明确的局部变量(不返回,不作为参数)的小数据,用对象,不需要new.
2.否则智能指针吧。
函数参数和返回值:
1.不需要修改那么const ref
2.如要修改用原始指针
3.返回必定智能指针(google 的硬性规定就是指针,好像不推荐返回对象)
见例子,非常实用的干货。
作者:陈硕 链接:https://www.zhihu.com/question/22821303/answer/22759540 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 class Request : boost::noncopyable { /* ... */ }; class Buffer { /* network I/O buffer */ }; // return unique_ptr means caller taking ownership std::unique_ptr<Request> parseRequest(Buffer* inputMessage) { std::unique_ptr<Request> req(new Request); // make_unique<Request>() in C++14 // fill in req with inputMessage return std::move(req); } // pass unique_ptr means callee taking ownership void processRequest(std::unique_ptr<Request> req) { /* may process in a different thread, taking ownership of req */ } // pass raw pointer means changing it but not taking ownership void augmentRequest(Request* req) { /* fill in more fields, but not keeping the pointer longer than the scope of this function. */ } // pass const reference means read it but not taking ownership bool validateRequest(const Request& req) { /* do not keep the pointer or reference outside this function. */ } void onNetworkMessage(Buffer* inputMessage) { std::unique_ptr<Request> req = parseRequest(inputMessage); augmentRequest(req.get()); if (validateRequest(*req)) { processRequest(std::move(req)); } }
类内部变量:
以下3种情况有智能指针,或者引用。否则直接对象。
1)多态必须指针,就智能指针
2)可能和别的类共享,或者只是引用某个对象,所以生命周期不是很确定(考虑智能指针)
就比如lock_gurad ,锁类,里面的互斥锁mutex ,必须是外部对象引用(stl里面放入的是引用)。 智能锁类,不管理锁本身内存,只关注锁的锁定和放锁。
#include <iostream> #include "stdio.h" #include <memory> #include <unistd.h> #include <thread> #include <vector> #include <mutex> #include <unistd.h> #include <stdlib.h> using namespace std; mutex mtx; class mylock_guard { public: mylock_guard(mutex& _mtx):mtx(_mtx) { mtx.lock(); } ~mylock_guard() { mtx.unlock(); } private: mylock_guard(const mylock_guard&); mylock_guard& operator=(const mylock_guard&); mutex& mtx; }; void ShowMsg() { //lock_guard<mutex> lck(mtx); mylock_guard lck(mtx); cout<<"1 seconed"<<endl; sleep(1); } int main() { thread t1(ShowMsg); thread t2(ShowMsg); thread t3(ShowMsg); t1.detach(); t2.detach(); t3.detach(); string cmd; cin>>cmd; }
3)大数据,如果定义成对象,会导致当前对象无法在栈内创建