原文:https://blog.csdn.net/u011098327/article/details/72865934
依赖:
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.11</artifactId>
<version>${mongodb-spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
</dependency>
<spark.version>2.1.1</spark.version> <mongodb-spark.version>2.0.0</mongodb-spark.version>
spark2.x向mongodb中读取写入数据,读取写入相关参数参考 https://docs.mongodb.com/spark-connector/current/configuration/#cache-configuration
从mongodb中读取数据时指定数据分区字段,分区大小提高读取效率, 当需要过滤部分数据集的情况下使用Dataset/SQL的方式filter,Mongo Connector会创建aggregation pipeline在mongodb端进行过滤,
然后再传回给spark进行优化处理
val spark = SparkSession .builder .appName("AppMongo") .master("local[*]") .config("spark.worker.cleanup.enabled", "true") .config("spark.scheduler.mode", "FAIR") .getOrCreate() val inputUri="mongodb://test:pwd123456@192.168.0.1:27017/test.articles" val df = spark.read.format("com.mongodb.spark.sql").options( Map("spark.mongodb.input.uri" -> inputUri, "spark.mongodb.input.partitioner" -> "MongoPaginateBySizePartitioner", "spark.mongodb.input.partitionerOptions.partitionKey" -> "_id", "spark.mongodb.input.partitionerOptions.partitionSizeMB"-> "32")) .load() val currentTimestamp = System.currentTimeMillis() val originDf = df.filter(df("updateTime") < currentTimestamp && df("updateTime") >= currentTimestamp - 1440 * 60 * 1000) .select("_id", "content", "imgTotalCount").toDF("id", "content", "imgnum")
val rdd = MongoSpark.load(sc) val aggregatedRdd = rdd.withPipeline(Seq(Document.parse("{ $match: { test : { $gt : 5 } } }"))) println(aggregatedRdd.count) println(aggregatedRdd.first.toJson)
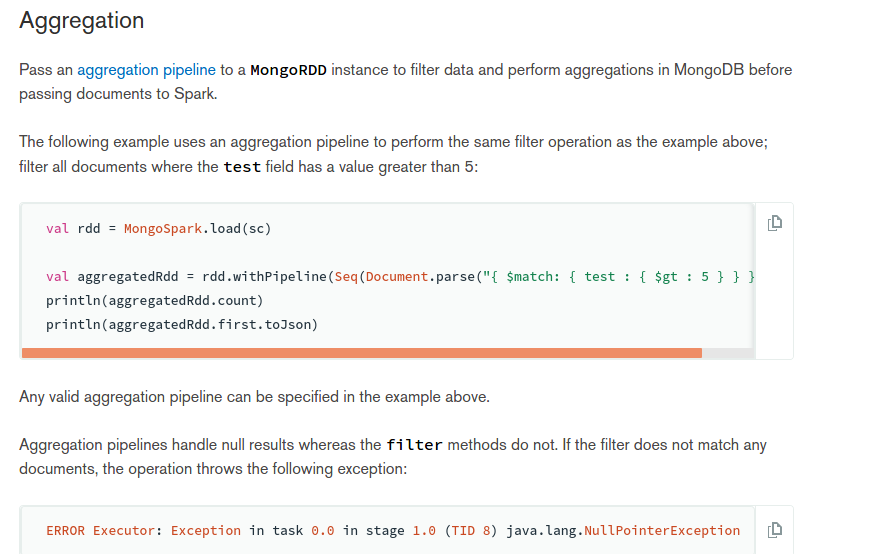
spark操作mongodb的scala-api文档:https://docs.mongodb.com/spark-connector/current/scala-api/
向mongo里面写数据可以使用两种不同的方式mode=overwrite,append
overwirite 以覆盖的方式写入
append 以追加的方式写入
al outputUri="mongodb://test:pwd123456@192.168.0.1:27017/test.article_garbage" saveDF.write.options(Map("spark.mongodb.output.uri"-> outputUri)) .mode("append") .format("com.mongodb.spark.sql") .save()