前面我们演示分析了100+个wireshark TCP实例,拥塞控制部分也介绍常见的拥塞处理场景以及4种拥塞撤销机制,但是我们一直使用的都是reno拥塞控制算法。实际上拥塞控制发展到今天已经有了各种各样的拥塞控制算法,而且普遍认为单纯基于丢包的reno拥塞控制算法已经不适应当前internet网络了,最近谷歌又折腾出了一个BBR拥塞控制算法,对比国内,还没有一个在TCP领域有突出贡献的公司,谷歌在TCP领域真是甩了其他公司好几条街。闲言少叙吧,拥塞控制关注的Scalability、RTT fairness、TCP friendliness、 convergence等等需要复杂的数学推理,响应函数(response function) 则是拥塞控制的一个重要特性,从响应函数的斜率、与AIMD(1,0.5)的交汇等可以大致观察出RTT fairness、TCP friendliness、Scalability等特点。好在多数时候我们即使不理解太深奥的数学推理也可以从直观上理解一个拥塞控制算法的处理思路和原理。下面简单介绍一下TFRC和一些其他的拥塞控制算法。
1、TFRC
TFRC(TCP Friendly Rate Control)是Internet环境中单播数据流的一个拥塞控制机制。整体的发送速率上,TFRC可以相对公平的与TCP竞争网络带宽,但是相比TCP,其吞吐量在时间上更为平稳,因此TFRC更适合需要平稳速率的流媒体应用。注意TFRC是一个拥塞控制机制,它可以应用在传输层中,如DCCP,也可以使用在应用层中做拥塞控制。
TFRC要保证与TCP公平竞争的同时还要保证传输速率的平稳,带来的后果就是TFRC对网络可用带宽的变化的响应比TCP的响应更慢。因此RFC5348指出只有确实需要平滑传输速率的应用才应该使用TFRC。而应用层如果只是简单的想要在尽可能短的时间内传输尽可能多的数据,那么还是建议使用TCP,或者与TCP类似的AIMD拥塞控制机制。
TFRC是设计用来控制发送数据包大小基本不变业务,TFRC通过改变每秒发送的数据包的个数来响应拥塞。它是一个接收端的机制,但是也可以在发送端来实现。
TFRC基本原理:Padhye在1998年给出了TCP速率估计公式,推导除了TCP发送速率与RTT和丢包率的关系。RFC5348中的TFRC则是根据这个公式,通过探测网络的丢包率和RTT来限制发送端的速率。这样整体速率上就可以保证与TCP相对公平竞争,另外一方面在保证整体速率符合该公式限制的前提下,TFRC在发生拥塞时,降低发送速率不会如TCP那么猛烈。例如TFRC在RTO(RTO为4*RTT)超时时,只会把允许的发送速率降低为一半,而TCP会把cwnd直接降低为1。
2、HSTCP
之前演示的一直是reno拥塞控制算法,我们可以粗略估计一下reno在高速TCP环境下的处理,在一个RTT为100ms,带宽为10Gbps,包大小为1500bytes的网络中,如果要满速率发送cwnd>=10*1000*1000*1000*100/1000/8/1500=83333。假设cwnd=83333,如果发生快速重传cwnd减半后重新进行拥塞避免过程,拥塞避免过程中每一个RTT,cwnd增1,那么大约需要83333/2*100=4166666ms=4166s=69min,通过简单计算我们可以发现,这种场景下大约需要69分钟,reno的拥塞避免过程才能让cwnd足够大以充分利用10Gbps的带宽,显然69分钟的拥塞避免过程时间太长了,而且很可能会造成带宽浪费。实际上受限于丢包率,reno的一个典型问题就是还没等cwnd增长到足够利用10Gbps的值就已经发生丢包并削减cwnd了。
而RFC3649中的HSTCP(HighSpeed TCP)就是根据这种场景进行的优化改进,HSTCP的慢启动过程与我们之前介绍的reno算法的慢启动过程一致,但是HSTCP会改变AIMD行为。我们把标准TCP的AIMD过程泛化为下面的公式
cwnd=cwnd+a(w)/cwnd
cwnd=cwnd-b(w)*cwnd
在标准TCP中a(w)=1,b(w)=0.5,而在HSTCP中a(w)和b(w)则是一个随着cwnd的大小而变化的值,根据linux代码中的相关参数绘制了如下的关系曲线,其中a(w)/cwnd就表示每收到一个数据包的ACK,cwnd_cnt这个状态变量自增多少,在cwnd<=38的时候,a(w)=1,b(w)=0.5,因此对于低速TCP,HSTCP算法与标准TCP算法是一致的,但是对于高速TCP,a(w)变大,b(w)变小,这样当发生快速重传的时候cwnd的削减就不会如标准TCP那么猛烈,而且收到ACK报文的时候,cwnd_cnt的增长也更为迅速。
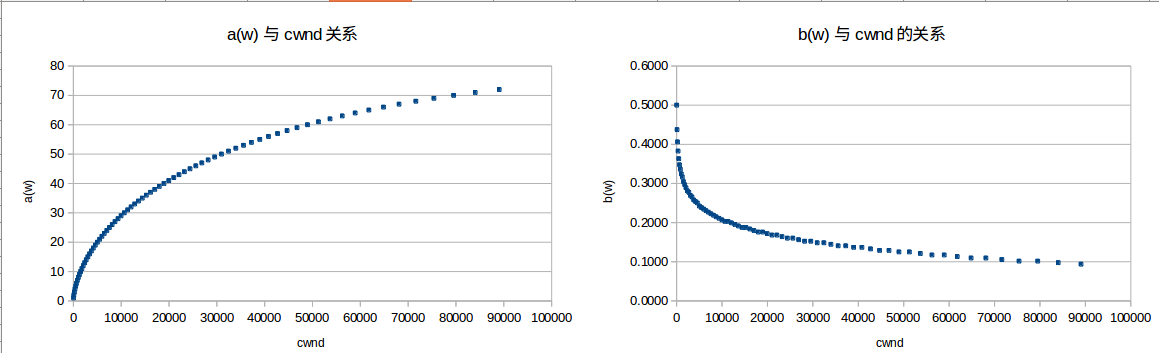
实际上HSTCP是把标准TCP的响应函数(response function)由w = 1.2/sqrt(p)近似改为了w= 0.12/p^0.835,其中w表示每个RTT允许发送的报文的个数,p表示丢包率。对这个感兴趣的可以参考RFC3649或者其他相关资料。HSTCP的实现代码其实也只有一百多行了,感兴趣的自行参考。
我们再粗略估计一下之前的那个例子使用HSTCP的时候,需要多长时间来恢复,在linux代码实现中当75401<cwnd<=79517时候,a(w)=70, b(w)=0.1016, 当75401<cwnd<=79517时a(w)=71,b(w)=0.0977,因此对于上面举的10Gbps的例子,当cwnd=83333,发生快速重传并且快速恢复后,更新cwnd=cwnd-0.0977*cwnd=75171,恢复所需要的总时间为,((79517-75171)/70+(83333-79517)/71)*RTT=12s。通过对比可以看到快速重传/快速恢复后通过拥塞避免恢复到相同水平,reno需要约69分钟,而HSTCP只需要大约12s。而且在实际的reno的69分钟恢复过程中,很可能已经发生了比特错误(比特错误虽然是一个概率很低的事件,但是在高速网络中69分钟内可以传输大量的数据包,因而这期间发生比特错误的概率是非常高的,可以参考BICTCP的论文)从而导致再次触发快速重传,cwnd因此很难达到理论最高水平,reno拥塞控制也就不能充分利用高速网络了。
3、BIC(Binary Increase Congestion Control)
BICTCP同样是针对LFN(long fat networks)网络的,BICTCP最开始叫做BITCP。值得一提的是BICTCP和下面要介绍的CUBIC的主要作者中有一个是北京科技大学毕业的,后在NCSU期间与人合作设计了这两个拥塞控制算法。在2004年BITCP的论文中,作者们研究发现当时已有的针对高速网络的TCP拥塞控制算法HSTCP和STCP有严重的RTT不公平性,这种RTT的不公平性在没有AQM机制的路由器中尤为严重。BITCP(Binary Increase TCP)分为两部分,一部分叫做binary search increase,另外一部分叫做additive increase。在快速重传/快速恢复后,BITCP会以二分查找来更新cwnd以找到最合适的窗口大小(作者称呼为saturation point),举个例子假如,cwnd=100的时候触发了一次快速重传/快速恢复过程,假设BITCP的参数β=0.2,则cwnd更新为 cwnd=cwnd*(1-0.2)=80,接着收到ACK的时候会把cwnd更新为cwnd+=((100+80)/2-80)/cwnd,即一个RTT内cwnd自增10,接着下一个RTT内cwnd自增5,以此类推,这个过程就叫做binary search increase。至于additive increase过程是为了防止上面binary search increase过程中cwnd自增过快,因此会有一个最大自增参数,限制cwnd每个RTT的自增值不超过最大自增参数。
BICTCP还有一个快速收敛过程和慢启动过程,注意这个慢启动过程并不是我们之前介绍的慢启动过程,BITCP的的慢启动是在拥塞避免的过程内的一个慢启动。另外同样为了保证TCP friendliness,在cwnd很小的时候,依然按照标准TCP的AIMD过程更新cwnd,并不会启动BICTCP。快速收敛和BITCP的慢启动过程等内容请参考作者的论文吧,这里不再进行详细介绍。可先阅读作者原始论文中的伪代码,然后就容易理解linux的实现代码了。
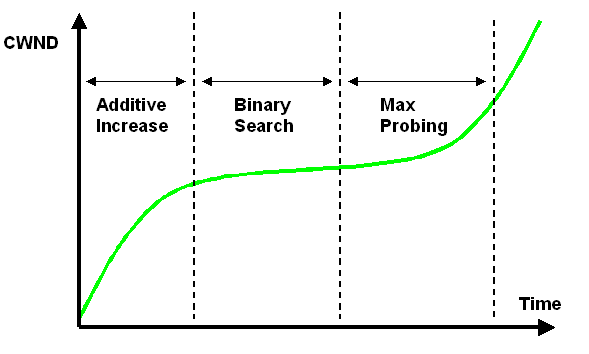
最后给出BICTCP的cwnd增长图示,其中右侧的Max Probing就是BICTCP在拥塞避免过程中的慢启动过程。
4、CUBIC
目前CUBIC是linux内核的默认拥塞控制算法。BICTCP的作者认为BICTCP有两个不足,一个是BICTCP的拥塞避免划分为三个阶段:additive increase、binary search increase和slow start,增加了复杂性。另外在低速网络或者网络RTT比较小的时候,BICTCP的增长函数对于TCP来说太激进。因此作者使用了一个立方函数(cubic function)来作为cwnd的增长函数,这种改进后的拥塞控制算法就称为cubic算法。
CUBIC中使用的立方函数如下
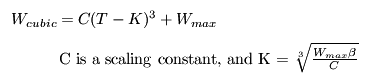
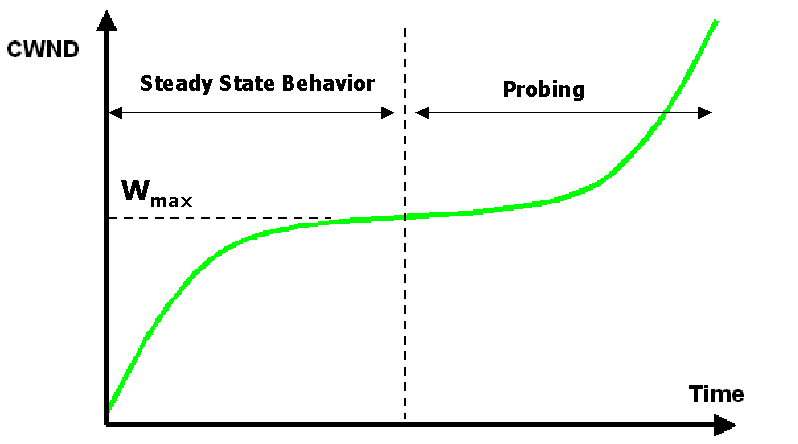
其中Wcubic表示在时间T时刻,允许发发送窗口大小,Wmax表示在发生快速重传前的cwnd,C是一个常量参数(默认为0.4),β是乘法减小常量因子(默认为0.2)。CUBIC的增长曲线如下,可以看到CUBIC的增长与BICTCP的增长趋势非常类似。相比BICTCP,CUBIC在Wmax附近的增长更为平缓。CUBIC的详细内容可以参考<CUBIC: A New TCP-Friendly High-Speed TCP Variant>,本篇仅作概述不再深入。
另外NCSU那帮人后来又提出了一个HyStart(Hybrid Start)的慢启动算法,传统的慢启动算法每个RTT时间cwnd翻一倍,当cwnd接近BDP的时候, 容易造成大量丢包,在不支持AQM的路由器上还会造成同步丢包,降低了TCP的性能。HyStart可以使用ACK train或者Delay increase机制来提前终止慢启动并进入拥塞避免。目前在linux中的CUBIC算法默认是使能HyStart慢启动算法的。另外在HyStart的原始论文中还介绍了其他的几种慢启动算法LSS、Astart、Vstart等,感兴趣的可以一读。
5、Vegas
Vegas是第一个基于时延的比较系统完整的拥塞控制算法,后续很多基于时延的拥塞控制都借鉴了Vegas的思想,其实在Vegas之前也有一些基于时延改善拥塞控制的算法。我们在拥塞控制概述的时候,给出了一张网络负载与响应时间的关系图吧。当网络负载逐渐加大,网络拥塞的时候,数据包就会在中间设备上缓存等待处理,进而使得网络的RTT变大,因此我们可以使用网络的时延来估计网络的拥塞情况。在1995年的Vegas论文中提出了三种技术来提升TCP的吞吐量降低丢包。第一个是Vegas可以采用一个更早期的决定来重传丢失的数据包。第二个是Vegas在拥塞避免阶段,TCP通过估计网络的拥塞程度,进而调整TCP的发送速率。第三个是修改了TCP的慢启动机制,在初始慢启动阶段可以在避免丢包的情况下找到合适大小的可用带宽,这就是我们上面提到的Vstart慢启动方法。
Vegas的重点是上面描述的三个技术中的第二个,即拥塞窗口调整。其基本思想是:当拥塞窗口增大的时候,预期发送速率也会同步增大,但是这个发送速率不能超过可用带宽,当发送速率到达可用带宽的时候,再次增大拥塞窗口,发送速率不会再次增大,额外发出的数据包(作者在论文中称呼这种数据为extra data)只会在产生瓶颈的路由器中积累。Vegas的目标就是维护合适的extra data数据量。如果一个TCP连接发送太多的extra data,那么就会产生拥塞最终丢包,如果extra data太少,那么当可用带宽变大的时候,对应的连接可能就不能快速的响应。按照作者描述,Vegas会计算一个实际发送速率Actual和一个预期的速率Expected,其中Expected=cwnd/BaseRTT,BaseRTT是测量到的最小的RTT,而Actual则是根据当前连接采样的RTT和cwnd计算得来。接着计算Diff=Expected-Actual,Vegas会维护两个门限参数α和β(α<β),当Diff<α的时候,Vegas线性的增大cwnd,当Diff>β时候,Vegas线性的减小拥塞窗口,当α<Diff<β的时候,Vegas维持cwnd不变。
Vegas在拥塞避免阶段采用的是AIAD的方式来更新cwnd。Vegas的性能实际上是比reno要好的,但是因为Vegas一般是在发生丢包前起作用,而reno则是一直增大发送速率直到丢包,因此在带宽的争夺上Vegas竞争不过reno,从而限制了Vegas的应用。对详细内容感兴趣的建议阅读一下作者的原始论文,这篇论文相比BIC、HSTCP的论文并没有复杂的数学推算,是相对容易理解的一篇。
6、Westwood和Westwood+
Westwood TCP(简称为TCPW)可以看成是reno和Vagae的结合,TCPW在Lossy-Link网络环境下有非常优异的表现。Loss-Link是指具有非常高的非拥塞丢包比例的网络环境,例如Wifi网络。Westwood+ TCP(简称为TCPW+)则使用更长的带宽估计间隔和优化的滤波器修复了TCPW在ACK compression(之前我们介绍过,ACK compression指接收端间隔发送的ACK确认包一起到达发送端)场景下对带宽估计过高的问题。Linux中实现的是TCPW+,我们这里直接概述一下TCPW+的处理。
TCPW+使用端到端的带宽估计来处理非拥塞丢包)。类似Vegas,TCPW+在每个RTT都会就算一个估计一个带宽值BW=D/RTT,其中D表示在这个RTT里面成功传输到接收端的数据量,接着对BW进行滤波后得到带宽的估计值BWE,另外在TCPW+还会维护更新一个RTT的最小值min_RTT,当发生超时重传时,更新cwnd=1,ssthresh=max(2,(BWE*min_RTT)),在快速重传/快速恢复后,更新cwnd=ssthresh=max(2,(BWE*min_RTT))。
当发生非拥塞丢的时候,RTT一般不会有剧烈变化,因此BWE能有有效的估计可用带宽。而发生拥塞丢包的时候,RTT显著上升,BWE则会显著变小同样可以估计可用带宽。因此TCPW+能高效的处理非拥塞丢包和拥塞丢包。
7、其他拥塞控制算法
上面着重介绍了几个比较典型的拥塞控制算法,HSTCP是针对高速网络的拥塞控制,Vegas是基于时延的拥塞控制,而TCPW+是综合利用时延和丢包进行的拥塞控制,CUBIC是当前Linux内核的默认拥塞控制算法。理解这些典型的拥塞控制算法(代码+论文/协议)对于学习其他的拥塞控制算法会有很大帮助。下面简单概述一下其他的拥塞控制算法
FAST TCP:FAST TCP是一个与Vegas紧密关联的拥塞控制算法,而且作者已经在USPTO申请了专利。FAST TCP同样是针对高BDP网络的,当测量到的RTT接近最小RTT的时候,说明网络并没有发生拥塞,FAST TCP相比Vegas会更激进的调整cwnd,从而可以与reno竞争带宽。
Veno TCP:Veno同样是一个Vegas与Reno的综合体,Veno尝试解决的是lossy-link网络的拥塞控制,而不是高带宽网络的拥塞控制。和Vegas类似,Veno通过Nqueue = cwnd - BWE×min_RTT来估计队列缓存,在拥塞避免阶段会根据Nqueue来更新cwnd,当发送速率接近链路饱和点的时候,cwnd更新就会变缓。另外当发生丢包的时候,Veno会根据Nqueue来判断当前丢失是拥塞丢包还是非拥塞丢包,并对ssthresh做不同的处理。
Hybla TCP:针对高时延网络的拥塞控制,典型的如卫星网络。标准的Reno混合组网下,RTT较大的连接的速率将会远小于正常RTT的连接。Hybla则是针对这种场景做的优化,Hybla会选定一个RTT0作为参考RTT,RTT0默认为25ms,它会使得其他RTT的TCP连接在拥塞控制方面等效于RTT0的Reno的TCP连接。
另外还有很多拥塞控制算法我也没有了解,例如前面ECN介绍文章中提到的DCTCP、利用剩余带宽的LP TCP、高速网络中的HTCP、YeAH TCP、还有最新的BBR等等。
补充说明:
1、注意第二版TCP/IP Illustrated Vol1 P769给出的速率公式分母有问题,公式过于复杂这里不再给出,详细请查询RFC5348或者我总结的部分勘误
2、https://en.wikipedia.org/wiki/TCP_Friendly_Rate_Control
3、TFRC速率公式 http://conferences.sigcomm.org/sigcomm/1998/tp/paper25.pdf
4、TFRC https://tools.ietf.org/html/rfc5348
5、HSTCP http://www.icir.org/floyd/papers/hstcp.pdf https://tools.ietf.org/html/rfc3649
6、BIC TCP http://netsrv.csc.ncsu.edu/export/bitcp.pdf
7、CUBIC http://netsrv.csc.ncsu.edu/export/cubic_a_new_tcp_2008.pdf
8、BIC与CUBIC https://research.csc.ncsu.edu/netsrv/?q=content/bic-and-cubic
9、HyStart http://netsrv.csc.ncsu.edu/export/hystart_techreport_2008.pdf https://research.csc.ncsu.edu/netsrv/sites/default/files/hybridstart_pfldnet08.pdf
10、Vegas http://www.cs.toronto.edu/syslab/courses/csc2209/06au/papers/vegas.pdf
11、TCPW/TCPW+ http://www.signal.uu.se/Research/PCCWIP/Mobicom01Mascolo.pdf http://c3lab.poliba.it/images/f/f7/Ccr_v31.pdf