Write a SQL query to rank scores. If there is a tie between two scores, both should have the same ranking. Note that after a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no "holes" between ranks. +----+-------+ | Id | Score | +----+-------+ | 1 | 3.50 | | 2 | 3.65 | | 3 | 4.00 | | 4 | 3.85 | | 5 | 4.00 | | 6 | 3.65 | +----+-------+ For example, given the above Scores table, your query should generate the following report (order by highest score): +-------+------+ | Score | Rank | +-------+------+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 2 | | 3.65 | 3 | | 3.65 | 3 | | 3.50 | 4 | +-------+------+
这道题目让我们对分数进行排序。如果两个分数之间相同则存在相同的排名,需要注意的是,如果有相同排名后,下一个排名数字应该是一个连续的整数值:
在这里我们先拓展一下,先使用Excel函数来对此项题目求解:
在Excel中,可以使用SUMPRODUCT()函数来求解:
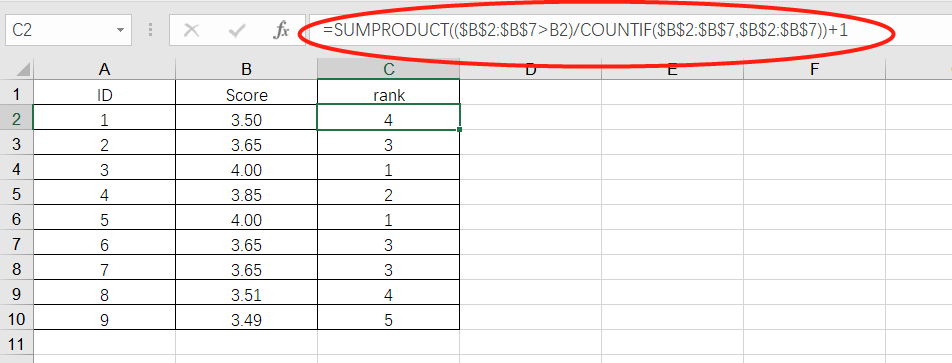
接着我们使用SQL语句来实现该需求:
解法一:
SELECT Score, (SELECT COUNT(DISTINCT Score) FROM Scores WHERE Score >= s.Score) Rank FROM Scores s ORDER BY Score DESC;
此题的解法是把成绩按照倒序排序,再把去重后每一门成绩做比较大小来统计数;
咱们再做一次扩展:就是成绩依然排名,不过要求是当要重复排名的时候,之后的排名数会跳过重复数的排名
我们知道在Excel中使用Rank函数就可以实现:

那么在SQL中怎么实现这个排名呢:
select score, RANK() OVER(order by Score DESC) rank from scores ORDER BY score DESC;
在这里可以使用排名函数就可以实现这个需求。
解法二:
SELECT Score, (SELECT COUNT(*) FROM (SELECT DISTINCT Score s FROM Scores ) t WHERE s >= Score) Rank FROM Scores ORDER BY Score DESC;
解法二与解法一的解题思路是一致的,只不过写法上略有不同。
解法三:
SELECT s.Score, COUNT(DISTINCT t.Score) Rank FROM Scores s JOIN Scores t ON s.Score <= t.Score GROUP BY s.Id ORDER BY s.Score DESC;
本方法使用了内交,join是inner join 的简写形式,自己和自己内交,条件是右表的分数大于等于左表,然后群组起来根据分数的降序排列。
解法四:
SELECT Score, @rank := @rank + (@pre <> (@pre := Score)) Ranking FROM Scores, (SELECT @rank := 0, @pre := -1) INIT ORDER BY Score DESC;
这里用了两个变量,变量使用时其前面需要加@,这里的:= 是赋值的意思,如果前面有Set关键字,则可以直接用=号来赋值,如果没有,则必须要使用:=来赋值,两个变量rank和pre,其中rank表示当前的排名,pre表示之前的分数,下面代码中的<>表示不等于,如果左右两边不相等,则返回true或1,若相等,则返回false或0。初始化rank为0,pre为-1,然后按降序排列分数,对于分数4来说,pre赋为4,和之前的pre值-1不同,所以rank要加1,那么分数4的rank就为1,下面一个分数还是4,那么pre赋值为4和之前的4相同,所以rank要加0,所以这个分数4的rank也是1,以此类推就可以计算出所有分数的rank了。