#include <iostream>
using namespace std;
inline int Max(int a, int b)
{
if (a > b)
return a;
else
return b;
}
int main()
{
cout << Max(23, 5) << endl;
return 0;
}
- 内联函数和普通函数的区别在于:当编译器处理调用内联函数的语句时,不会将该语句编译成函数调用语句的指令,而是直接将整个内联函数体的代码插入调用语句处,就像整个函数体在调用处被重写了一遍一样。
- 使用内联函数的好处是,不需要付出执行函数调用的额外开销。
- 要使用内联特性,必须采取下述措施之一:
- 在函数声明前加上关键字
inline
- 在函数定义前加上关键字
inline
- 需要注意的是,调用内联函数的语句前必须已经出现内联函数的定义(即整个函数体),而不能只出现内联函数的原型(声明)。
- 通常的做法是省略原型,将整个定义(即函数头和所有函数代码)放在本应提供原型的地方。
- 内联函数也存在缺点,以空间换时间的策略,会使得最终可执行程序的体积增加。程序员请求将函数作为内联函数时,编译器并不一定会满足这种要求。它可能认为该函数过大、或者其中的循环体的执行次数很多,导致要消耗大量的时间、或注意到函数调用了自己(内联函数不能递归),因此不将其作为内联函数;而有些编译器没有启用或实现这种特性。
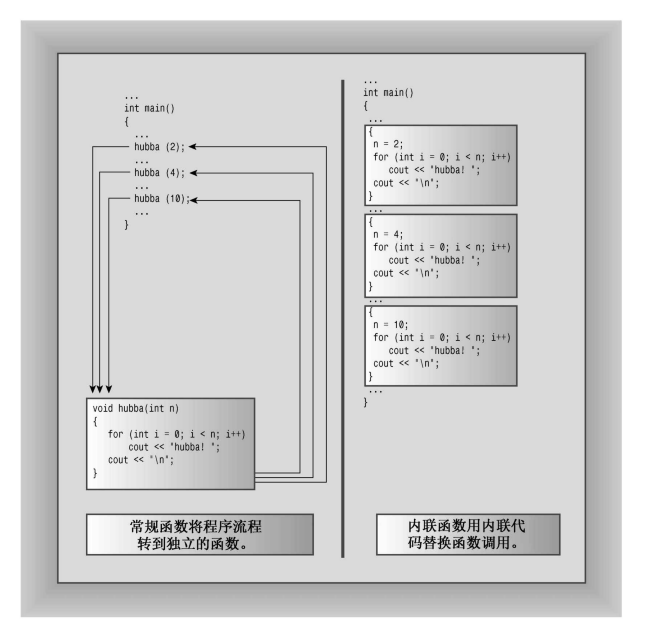
- 内联函数是C++为提高程序运行速度所做的一项改进。常规函数和内联函数之间的主要区别不在于编写方式,而在于C++编译器如何将它们组合到程序中。要了解内联函数与常规函数之间的区别,必须深入到程序内部。
- 编译过程的最终产品是可执行程序——由一组机器语言指令组成。运行程序时,操作系统将这些指令载入到计算机内存中,因此每条指令都有特定的内存地址。计算机随后将逐步执行这些指令。有时(如有循环或分支语句时),将跳过一些指令,向前或向后跳到特定地址。常规函数调用也使程序跳到另一个地址(函数的地址),并在函数结束时返回。下面更详细地介绍这一过程的典型实现。执行到函数调用指令时,程序将在函数调用后立即存储该指令的内存地址,并将函数参数复制到堆栈(为此保留的内存块),跳到标记函数起点的内存单元,执行函数代码(也许还需将返回值放入到寄存器中),然后跳回到地址被保存的指令处(这与阅读文章时停下来看脚注,并在阅读完脚注后返回到以前阅读的地方类似)。来回跳跃并记录跳跃位置意味着以前使用函数时,需要一定的开销。
- C++内联函数提供了另一种选择。内联函数的编译代码与其他程序代码“内联”起来了。也就是说,编译器将使用相应的函数代码替换函数调用。对于内联代码,程序无需跳到另一个位置处执行代码,再跳回来。因此,内联函数的运行速度比常规函数稍快,但代价是需要占用更多内存。如果程序在10个不同的地方调用同一个内联函数,则该程序将包含该函数代码的10个副本。
- 应有选择地使用内联函数。如果执行函数代码的时间比处理函数调用机制的时间长,则节省的时间将只占整个过程的很小一部分。如果代码执行时间很短,则内联调用就可以节省非内联调用使用的大部分时间。另一方面,由于这个过程相当快,因此尽管节省了该过程的大部分时间,但节省的时间绝对值并不大,除非该函数经常被调用。