1、MySQL 索引使用的注意事项
- 更新频繁的列不要加索引
- 数据量小的表不要加索引
- 重复数据多的字段不要加索引,比如性别字段
- 首先应该考虑对where 和 order by 涉及的列上建立索引
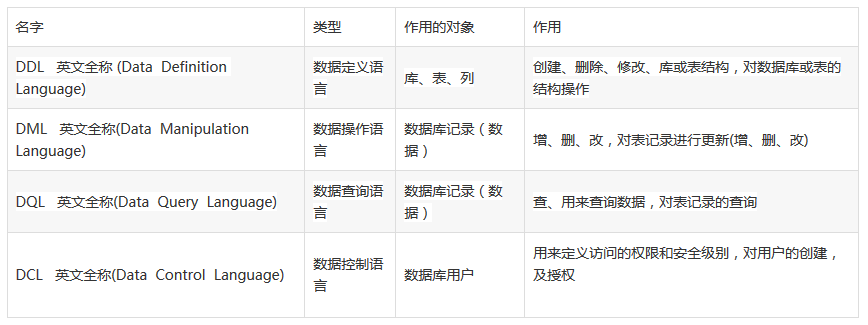
2、DDL、DML、DCL、DQL分别指什么
3、explain命令
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
示例:
explain select surname,first_name form a,b where a.id=b.id
| type | 本次查询表联接类型,从这里可以看到本次查询大概的效率 |
| key | 最终选择的索引,如果没有索引的话,本次查询效率通常很差 |
| key_len | 本次查询用于结果过滤的索引实际长度 |
| rows | 预计需要扫描的记录数,预计需要扫描的记录数越小越好 |
| Extra | 额外附加信息,主要确认是否出现 Using filesort、Using temporary 这两种情况 |
4、left join,right join,inner join
- left join: 左连接,返回包括左表中所有记录和右表中 连接字段相等的记录
- right join:右连接,与左连接相反
- inner join:内连接,只返回两表中连接字段相等的记录
5、数据库事物ACID
原子性、一致性、隔离性、持久性
6、事物的隔离级别
读未提交、读以提交、可重复读、可序列化读
7、脏读、幻读、不可重复读
-
脏读:事务A读到了事务B未提交的数据。
-
不可重复读:事务A第一次查询得到一行记录row1,事务B提交修改后,事务A第二次查询得到row1,但列内容发生了变化。
-
幻读:事务A第一次查询得到一行记录row1,事务B提交修改后,事务A第二次查询得到两行记录row1和row2。
6和7关系表
| 脏读 | 不可重复读 | 幻读 | |
| 读未提交 | 可能出现 | 可能出现 | 可能出现 |
| 读提交 | 不会出现 | 可能出现 | 可能出现 |
| 重复读 | 不会出现 | 不会出现 | 可能出现 |
| 序列化 | 不会出现 | 不会出现 | 不会出现 |
如果数据库的隔离级别为(第一列),会出现的问题(第一行)
8、数据库的几大范式
- 第一范式:每一个属性都不能再分割,都是原子项。
- 第二范式:在满足第一范式的基础上,确保表中的每列都和主键相关
- 第三范式:在满足第二范式的基础上,确保每列都和主键列直接相关,而不是间接相关
参考:https://www.cnblogs.com/1906859953Lucas/p/8299959.html
9、数据库常见的命令
select update delete insert
10、说说分库分表设计
垂直分库,水平分表。
11、说说 SQL 优化之道
使用一切手段,避免全表扫描
参考:https://blog.csdn.net/wang1127248268/article/details/53413655
12、MySQL遇到的死锁问题、如何排查与解决
- 如何排查:查看数据库日志。
- 解决原则:
- 并发插入时,不在一个事务内进行再次事务提交。
- 改并发为串行执行。
查询数据库产生死锁的日志方式(以mysql为例):https://825635381.iteye.com/blog/2339503
13、存储引擎的 InnoDB与MyISAM区别,优缺点,使用场景
区别:
- MyISAM是非事务安全型的,而InnoDB是事务安全型的。
- MyISAM锁的粒度是表级,而InnoDB支持行级锁定。
- MyISAM支持全文类型索引,而InnoDB不支持全文索引。
优缺点:
- MyISAM相对简单,所以在效率上要优于InnoDB,小型应用可以考虑使用MyISAM。
- MyISAM表是保存成文件的形式,在跨平台的数据转移中使用MyISAM存储会省去不少的麻烦。
- InnoDB表比MyISAM表更安全,可以在保证数据不会丢失的情况下,切换非事务表到事务表(alter table tablename type=innodb)。
使用场景:
- MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择。(1)做很多count 的计算;(2)插入不频繁,查询非常频繁;(3)没有事务。
- InnoDB用于事务处理应用程序,具有众多特性,包括ACID事务支持。如果应用中需要执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能。(1)可靠性要求比较高,或者要求事务;(2)表更新和查询都相当的频繁,并且行锁定的机会比较大的情况。
14、索引类别(B+树索引、全文索引、哈希索引)、索引的原理
全文索引:将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
哈希索引:
16、什么是自适应哈希索引(AHI)
InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立哈希索引。
17、为什么要用 B+tree作为MySQL索引的数据结构
- 聚集索引:表记录的排列顺序和与数据的存储顺序一致(主键),一个表只能有一个,但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。 -->聚集索引规定了数据文件的存储顺序
- 非聚集索引:表记录的排列顺序和与数据的存储顺序不一致(唯一),一个表可以有多个。 -->是一个单独存放的指针表,用来快速找到对应点的地址
19、limit 20000 加载很慢怎么解决
参考:http://ourmysql.com/archives/1451
20、如何选择合适的分布式主键方案
参考:http://www.cnblogs.com/haoxinyue/p/5208136.html
这个博客中列举了几种常见生成主键的方式,并说明了其优缺点,可以根据实际情况选择主键生成方式。
21、选择合适的数据存储方案
- 关系型数据mysql Oracle
- 非关系型数据库redis、MongoDB
- 全文搜索引擎 ElasticSearch
22、常见的几种分布式ID的设计方案
- UUID
- 通过redis生成唯一的id