首先简单介绍一下NoSQL,意思就是“不仅仅是SQL”,即非关系数据库。而MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
最近要在Windows上搭建一个MongoDB数据库同步系统,实现本地服务器和中心云服务器之间同步数据,用户可以访问中心服务器和本地服务器任何一端进行数据读写。在各大博客和官方文档上查到一个似乎可以解决问题的方案,副本集群。然而我在网络上所找到的方案并不能够实现系统的要求,不过还是一股傻劲的去配置了一波主从模式的副本集。
参考:http://www.mongoing.com/archives/2155
https://blog.csdn.net/leshami/article/details/60581417
https://blog.csdn.net/forever19911314/article/details/51177102
几经波折之后仍然找不到问题的解决方案,只能硬着头皮去向前辈请教(因为问的问题有点多,前辈也有点烦我了,不过还是很认真的给我讲)。将MongoDB单个节点配置成副本集,我的配置文件如下图

dbpath :数据保存路径
logpath:日志保存路径
journal:还没有去了解
port:端口,连接数据库时需要加上端口号,默认端口号为27017.
auth:顾名思义,身份认证
replSet:副本集的重点,将节点设置为副本集
oplogSize:oplog的文件大小,单位是M。
写好conf配置文件后用命令行以配置文件的方式启动MongoDB服务,如图:

然后是连接数据库,注意了。端口是40001,因为我使用的是localhost 所以我可以这么写
 回车
回车
进入数据库,等等 还没有初始化
cfg={"_id":"mytest","members":[{"_id":0,"host":"127.0.0.1:40001"}]}
rs.initiate(cfg)
初始化完成,回车

查看我们local下的oplog,这个oplog记录了我们对数据库的操作,数据库的同步就是读取各个数据库的oplog信息,将oplog记录下来的操作在中心服务器上再操作一遍就可以实现数据的同步啦
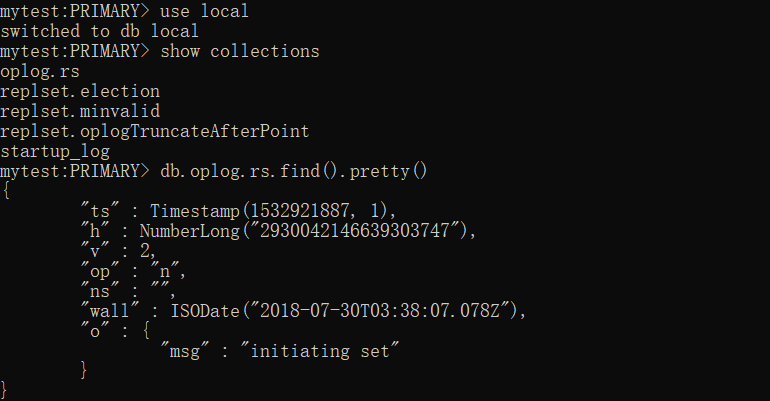
下面介绍一下MongoDB的oplog
1:oplog简介
oplog是local库下的一个固定集合,Secondary就是通过查看Primary 的oplog这个集合来进行复制的。每个节点都有oplog,记录这从主节点复制过来的信息,这样每个成员都可以作为同步源给其他节点。
2:副本集数据同步的过程
副本集中数据同步的详细过程:Primary节点写入数据,Secondary通过读取Primary的oplog得到复制信息,开始复制数据并且将复制信息写入到自己的oplog。如果某个操作失败(只有当同步源的数据损坏或者数据与主节点不一致时才可能发生),则备份节点停止从当前数据源复制数据。如果某个备份节点由于某些原因挂掉了,当重新启动后,就会自动从oplog的最后一个操作开始同步,同步完成后,将信息写入自己的oplog,由于复制操作是先复制数据,复制完成后再写入oplog,有可能相同的操作会同步两份,不过MongoDB在设计之初就考虑到这个问题,将oplog的同一个操作执行多次,与执行一次的效果是一样的。
3:oplog的增长速度
oplog是固定大小,他只能保存特定数量的操作日志,通常oplog使用空间的增长速度跟系统处理写请求的速度相当,如果主节点上每分钟处理1KB的写入数据,那么oplog每分钟大约也写入1KB数据。如果单次操作影响到了多个文档(比如删除了多个文档或者更新了多个文档)则oplog可能就会有多条操作日志。db.testcoll.remove() 删除了1000000个文档,那么oplog中就会有1000000条操作日志。如果存在大批量的操作,oplog有可能很快就会被写满了。
4:oplog注意事项:
local.oplog.rs特殊的集合。用来记录Primary节点的操作。
为了提高复制的效率,复制集中的所有节点之间会相互的心跳检测(ping)。每个节点都可以从其他节点上获取oplog。
oplog中的一条操作。不管执行多少次效果是一样的
5:oplog的大小
第一次启动复制集中的节点时,MongoDB会建立Oplog,会有一个默认的大小,这个大小取决于机器的操作系统
rs.printReplicationInfo()
db.getReplicationInfo()
可以用来查看oplog的状态、大小、存储的时间范围