郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

arXiv:1902.08102v1 [stat.ML] 21 Feb 2019
Abstract
我们通过递归估计回报分布的统计量,提供了一个统一的框架,用于设计和分析分布强化学习(DRL)算法。我们的主要见识在于,可以将DRL算法分解为一些统计量估计和一种方法的组合,该方法插补与该统计集一致的回报分布。有了这种新的理解,我们就能对现有DRL算法进行改进的分析,并基于对回报分布期望的估计来构造新的算法(EDRL)。我们将EDRL与各种MDP上的现有方法进行比较,以说明我们的分析的具体方面,并开发了算法ER-DQN的深度RL变体,我们在Atari-57游戏套件上进行了评估。
1. Introduction
在强化学习(RL)中,一个中心概念是回报,即折扣奖励的总和。通常,这些回报的均值由价值函数估算,并用于策略改进。然而,最近,尝试学习回报分布的方法已被证明是行之有效的(Morimura et al., 2010a; b; Bellemare et al., 2017; Dabney et al., 2017; 2018; Gruslys et al., 2018);我们将学习回报分布的一般方法称为分布RL(DRL)。
尽管具有令人印象深刻的实验性能(Bellemare et al., 2017; Barth-Maron et al., 2018; Dabney et al., 2018)和基本理论结果(Rowland et al., 2018; Qu et al., 2018),但它仍然存在开发和分析DRL算法具有挑战性。在本文中,我们提出通过递归估计回报分布统计集来表达DRL算法,以解决这些挑战。我们观察到DRL算法可以看作是将统计量估计与我们作为插补策略的过程相结合,它会生成与统计估计集一致的回报分布。这种高度通用的方法(见图1)要求对分布RL中统计量和样本的不同作用进行精确处理。
使用此框架,我们能够为现有DRL算法提供新的理论结果,并演示基于回报分布期望的新算法的推导。更重要的是,我们的新颖方法可立即应用于大量的统计量和插补策略,为未来的研究提供了几种途径。具体来说,我们能够提供以下问题的答案:
- 我们可以在统一框架中描述现有的DRL算法,并且可以使用这种框架开发新算法吗?
- 通过Bellman更新可以确切地学习哪些回报分布统计量?
- 如果无法准确地学习某些统计量,我们如何在原则上估计它们,并保证它们相对于这些统计量的真实价值的近似误差?
在回顾了相关的背景材料之后,我们从(i)开始,介绍一个用于理解DRL的新框架,即根据要学习的一组统计量以及用于指定动态编程更新的插补策略。然后,我们通过引入用于统计集的Bellman封闭性概念来形式化(ii),并表明在广泛的统计类别中,可以通过Bellman更新准确获知的回报分布的唯一属性是矩。有趣的是,这排除了诸如分位数之类的统计量,这些数据构成了成功的现有DRL算法的基础。但是,我们然后通过显示该框架允许我们通过近似Bellman封闭性的概念来保证学习这些统计量时引入的近似误差,从而解决(iii)。我们将在回答这些问题时开发的框架应用于期望统计的案例,以开发新的分布RL算法,我们将其称为“期望分布RL”(EDRL)。最后,我们在各种MDP和更大范围的环境中测试这些新见解,以说明和扩展本文前面开发的理论贡献。

2. Background

2.1. Bellman equations
经典的Bellman方程(Bellman, 1957)通过以下方式将每个状态-动作对![]() 的期望回报与MDP中可能的下一状态的期望回报联系起来:
的期望回报与MDP中可能的下一状态的期望回报联系起来:
![]()
这产生了以下不动点迭代方案:
![]()
用于更新逼近其真实价值的近似集合![]() 。这种基本算法与近似动态编程和随机近似技术相结合,可以学习并改进MDP中的期望回报,从而构成所有基于价值的RL的基础(Sutton&Barto, 2018)。
。这种基本算法与近似动态编程和随机近似技术相结合,可以学习并改进MDP中的期望回报,从而构成所有基于价值的RL的基础(Sutton&Barto, 2018)。
分布Bellman方程在概率分布水平上描述了与等式(1)相似的关系(Morimura et al., 2010a;b; Bellemare et al., 2017)。当根据π选择动作时,令![]() 是随机回报的分布
是随机回报的分布![]() ,我们有下式:
,我们有下式:
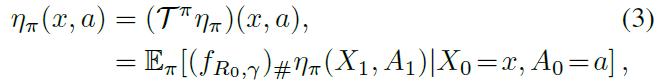
其中期望给出了下一个状态的混合分布,![]() 由
由![]() 所定义,并且
所定义,并且![]() 是通过函数g进行度量μ的前推,因此对于所有Borel子集
是通过函数g进行度量μ的前推,因此对于所有Borel子集![]() ,我们有
,我们有![]() (Rowland et al., 2018)。(参见图1)
(Rowland et al., 2018)。(参见图1)
以根据ηπ(x, a)分布的随机回报Zπ(x, a)表示,采用以下更熟悉的形式:

与等式(2)相似,可以根据等式(3)定义更新操作,以将近似分布的集合![]() 移向真实回报分布。但是,由于分布空间
移向真实回报分布。但是,由于分布空间![]() 是无限维的,因此通常无法直接使用分布Bellman方程,并且现有的分布RL方法通常依赖于此方程的参数逼近。我们在下面简要回顾了这些方法的一些重要示例。
是无限维的,因此通常无法直接使用分布Bellman方程,并且现有的分布RL方法通常依赖于此方程的参数逼近。我们在下面简要回顾了这些方法的一些重要示例。
2.2. Categorical and quantile distributional RL
迄今为止,大规模采用DRL的主要方法包括离散分类分布学习(Bellemare et al., 2017; Barth-Maron et al., 2018; Qu et al., 2018)和分布分位数学习(Dabney et al., 2017; 2018; Zhang et al, 2019);我们将这些方法分别称为CDRL和QDRL。我们在这里简要介绍了这些算法的动态编程版本,并在附录A中给出了随机版本,相关结果和可视化的完整描述。我们还注意到,其他方法,例如高斯混合学习(BarthMaron et al., 2018),也被探索到了。


3. The role of statistics in distributional RL
在本节中,我们将介绍现有分布RL算法的新观点,重点是学习统计集,而不是近似分布。我们从一个精确的定义开始。

从学习统计的角度很容易解释第2.2节中描述的QDRL更新。更新会从目标分布中提取有限的一组分位数统计的价值,有关目标的所有其他信息都会丢失。能否将CDRL更新也解释为跟踪有限的统计集还不太明显,但是以下引理表明确实如此。

尽管从算法的角度来看,将分布RL看作是通过一些参数化来近似回报分布是很直观的,但是在统计集及其递归估计方面进行思考还是有优势的。这种观点使我们能够精确地量化通过连续的分布Bellman更新传递的信息。反过来,这也为DRL算法的开发和分析带来了新的见解。在解决这些问题之前,我们首先考虑一个激励性的例子,其中缺乏精确性可能会使我们误入歧途。
3.1. Expectiles
由于QDRL的成功,我们考虑学习回报分布的期望,这是Newey&Powell(1987)引入的一系列统计量。期望类推平均数的方式与分位数类推中位数的方式类似。由于RL的目标是最大程度地提高平均回报,因此我们推测,尤其是期望,可能导致成功的DRL算法。我们从一个正式的定义开始。

我们注意到:(i)期望回归损失是平方损失的不对称形式,就像分位数回归损失是绝对值损失的不对称形式一样;(ii)1/2-期望只是其均值。因此,我们可以尝试通过将QDRL中的分位数回归损失替换为定义3.3中的期望回归损失来推导算法,从而学习与τ1, ..., τK ∈ [0, 1]对应的期望。
按照这种逻辑,我们再次采用以下形式的近似分布![]() ,我们根据下式执行更新:
,我们根据下式执行更新:
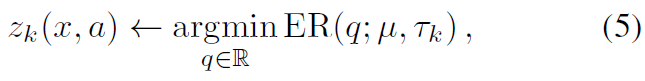
其中![]() 是目标分布。
是目标分布。
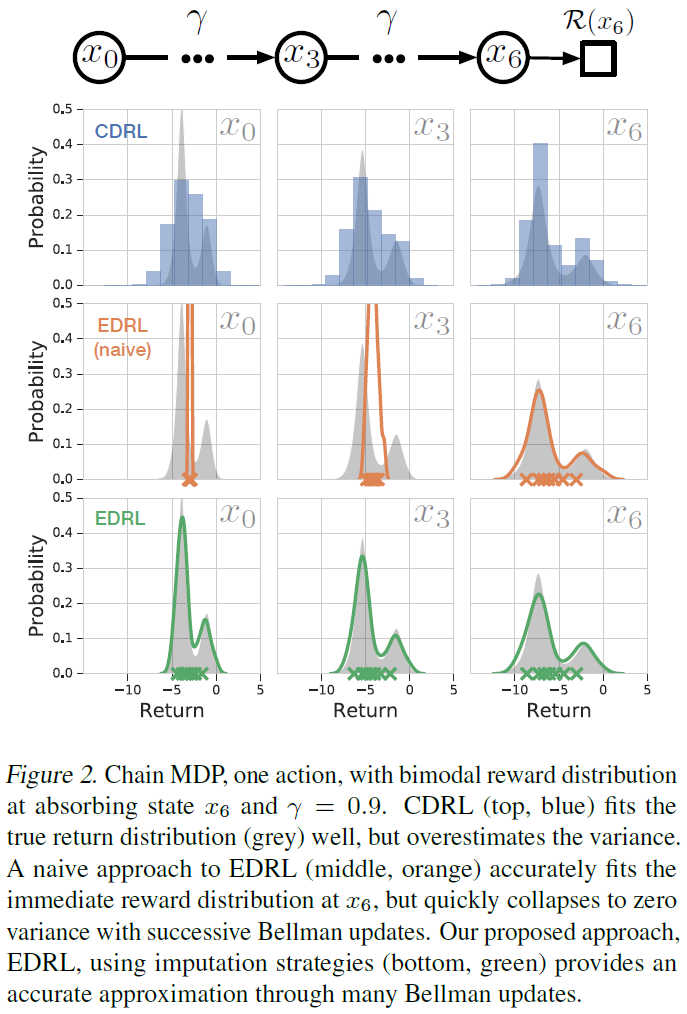
但是,在实践中,该算法不会像我们期望的那样执行,实际上,随着训练的进行,学习到的分布的方差会崩溃,这表明该算法在任何合理的意义上都无法逼近真实期望。在图2中,我们将这种“幼稚”方法的学习统计量与CDRL和我们提出的算法EDRL(在3.3节中介绍)进行了比较,以说明这一点。所有方法都精确地估计了即时奖励分布(右侧),但是当应用连续的Bellman更新时,不同的算法会显示出特征性的近似误差。CDRL算法高估了由于离散支持上的投影ΠC划分概率密度而导致的回报分布方差。相比之下,幼稚的期望方法低估了真正的方差,并迅速收敛到单个Dirac。
我们发现等式(5)中存在“类型错误”;被更新的参数zk(x, a)具有统计量的语义,作为ER损失的最小值,而出现在目标分布![]() 中的参数具有结果/样本的语义。本文的一个关键信息是需要区分分布RL中的统计量和样本。在下一部分中,我们将描述实现此目标的通用框架。
中的参数具有结果/样本的语义。本文的一个关键信息是需要区分分布RL中的统计量和样本。在下一部分中,我们将描述实现此目标的通用框架。
3.2. Imputation strategies
如果我们可以在每个可能的下一个状态-动作对(x', a')上获得全部回报分布估计值η(x', a'),我们将能够避免上一节中描述的样本与统计量之间的混淆。用![]() 表示对状态-动作对
表示对状态-动作对![]() 的统计量sk价值的近似,我们要根据以下条件进行更新:
的统计量sk价值的近似,我们要根据以下条件进行更新:
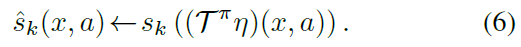
因此,设计DRL算法以收集统计量的原则方法是在算法中包括一个额外的步骤,其中对于我们要从其备份的任何状态-动作对(x', a'),估计的统计量![]() 转换为一致的分布η(x', a')。然后,这将允许执行等式(6)中给出的形式的备份。此概念在以下定义中形式化。
转换为一致的分布η(x', a')。然后,这将允许执行等式(6)中给出的形式的备份。此概念在以下定义中形式化。


因此,插补策略只是一个函数,它接收某些统计量的价值的集合,并返回具有这些统计量价值的概率分布。从某种意义上讲,它是s1:K的伪逆。

现在,我们有了一个定义有原则的分布RL算法的通用框架:(i)选择要学习的统计量族;(ii)选择一种插补策略;(iii)执行(或近似)等式(6)中给出的形式的更新。我们在算法1中对此进行了总结。

3.3. Expectile distributional reinforcement learning
现在,我们将在3.2节中开发的统计量和插补策略的一般框架应用于在3.1节中介绍的特殊情况。我们将定义一个插补策略,以便可以将等式(6)中给出的形式的更新应用于学习期望。
插补策略的任务是接受期望ε1, …, εK的集合作为输入,对应于τ1, ..., τK ∈ (0, 1),并计算概率分布μ,对i=1, …, K,满足![]() 。既然
。既然![]() 是作为q函数的严格凸,这可以在找到满足一阶最优性条件的概率分布时加以重申:
是作为q函数的严格凸,这可以在找到满足一阶最优性条件的概率分布时加以重申:
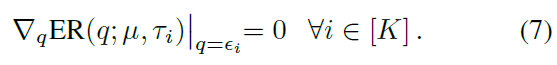
这定义了寻根问题,但可以等效地表述为最小化问题,目的如下:
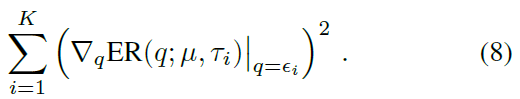
通过将分布μ限制为![]() 的形式,并将上述最小化目标视为z1:N的函数,可以直接验证该最小化问题是凸的。因此,通过声明ψ(ε1:K)由形式为
的形式,并将上述最小化目标视为z1:N的函数,可以直接验证该最小化问题是凸的。因此,通过声明ψ(ε1:K)由形式为![]() 的(8)的极小值给出,隐式定义了插补策略。我们注意到其他的参数选择也是可能的,但是上述Dirac delta的混合会导致特定的易处理优化问题。
的(8)的极小值给出,隐式定义了插补策略。我们注意到其他的参数选择也是可能的,但是上述Dirac delta的混合会导致特定的易处理优化问题。
建立了插补策略后,算法1现在产生了用于学习期望的完整DRL算法,我们将其称为EDRL。回到图2,我们观察到EDRL(底侧行)即使在许多Bellman更新后仍能准确表示真实的回报分布,并且没有表现出3.1节中幼稚的方法所观察到的崩溃。
3.4. Stochastic approximation
实际上,由于MDP动态是未知的与/或难以集成,因此通常无法计算等式(6)中的更新。 因此,通常有必要应用随机近似。令(r, x', a')为通过与环境直接交互而获得的随机变量(R0, X1, A1)的样本。然后,我们使用损失函数![]() 的梯度更新
的梯度更新![]() :
:

对于EDRL,估计统计量![]() 的自然损失函数是在τk处定义3.3的期望回归损失。这将产生EDRL的随机版本,如算法2所述。
的自然损失函数是在τk处定义3.3的期望回归损失。这将产生EDRL的随机版本,如算法2所述。

为了确保将这些随机梯度更新收敛到正确的统计量,应该是这样的情况:(子)梯度(9)对统计量真实价值的期望等于0。可以验证这情况,无论何时(i)分布μ的真实统计量q*满足![]() ,(ii)损失Lk在概率分布参数中是仿射的。M估计器损失及其相关统计量(Huber&Ronchetti, 2009)满足了这些条件,因此代表了大量的统计量族,可以立即将这种DRL方法应用于该统计量;CDRL,QDRL和EDRL中的统计量都是M估计量的特殊情况。
,(ii)损失Lk在概率分布参数中是仿射的。M估计器损失及其相关统计量(Huber&Ronchetti, 2009)满足了这些条件,因此代表了大量的统计量族,可以立即将这种DRL方法应用于该统计量;CDRL,QDRL和EDRL中的统计量都是M估计量的特殊情况。
4. Analysing distributional RL
现在,我们使用第3节中开发的统计量和插补策略框架来更深入地了解可以通过Bellman更新来学习分布RL中统计量的准确性。
4.1. Bellman closedness
经典的Bellman方程(1)表明,在MDP的每个状态-动作对之间,期望回报之间存在闭合形式的关系。如果目标是学习期望回报,则无需跟踪回报分布的任何其他统计量。这个著名的观察,连同对DRL算法作为对回报分布统计量的学习的新解释,引发了一个更普遍的问题:
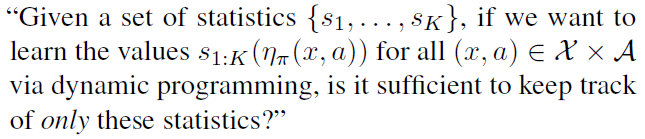
以下定义将这个问题形式化。

因此,由均值统计量组成的单例集是Bellman封闭的。相应的Bellman方程为等式(1)。众所周知,由均值和方差统计量组成的集合是Bellman封闭的(Sobel, 1982)。原则上,给定一个Bellman封闭统计量集{s1, …, sK},可以通过求解对应于相关Bellman算子Tπ的不动点方程来找到回报分布的相应统计量。此外,如果Tπ在某种度量上是一种压缩,则有可能通过基于算子Tπ的不动点迭代方案找到MDP的真实统计量。相反,如果统计量的集合s1:K不是Bellman封闭的,则不存在与回报分布的统计量相关的Bellman方程,因此,不可能以独立的方式使用动态编程来精确地学习统计量;必须扩大统计量集以使其Bellman闭合,或者可以使用插补策略执行备份,如3.2节所述。
下列结果给出了一类重要的Bellman封闭统计量(Sobel, 1982;Lattimore&Hutter, 2012)。

下一个结果表明,在广泛的统计量中,矩集合实际上是Bellman闭合的仅有的有限统计量集。该证明依赖于Engert(1970)的结果,该结果刻画了可平移函数在闭合条件下封闭的有限维向量空间。

我们认为这将是一个重要的新颖结果,这有助于凸显出Bellman封闭统计量的罕见性。定理4.3的一个重要推论是,将CDRL的特征描述为对引理3.2的回报分布的学习期望,这是CDRL所学的统计量没有被Bellman封闭。QDRL也有类似的结果,我们在以下结果中记录了这些事实。
这样做的直接结果是,一般而言,分布RL算法中学习到的统计量价值不必与MDP的真实基础价值完全对应(即使在表格设置中),因为通过DRL动态编程更新传播的统计量还不够确定我们想要学习的统计量。在原始论文中特别指出了CDRL和QDRL的这种不精确性(Bellemare et al., 2017; Dabney et al., 2017)。在本文中,我们的分析和实验证实,即使在完全可观察的域中使用表格智能体,这些伪像也会出现,从而代表了相关分布RL算法的固有属性。但是,从经验上讲,这些算法学习到的分布通常是准确的。在下一节中,我们提供定量描述此现象的理论保证。
4.2. Approximate Bellman closedness
根据第4.1节中有关Bellman封闭性的结果,我们可能会问,在什么意义上DRL算法学习到的统计值与相关MDP的相应真实基础值有关。此分析中的关键任务是,在DRL算法中将低近似误差的概念形式化,以寻求学习非Bellman封闭的统计量集合。也许令人惊讶的是,通常不可能在非Bellman封闭集中的所有统计量上同时实现低逼近误差。为此,我们在附录第C节为此提供了一些CDRL和QDRL示例。
由于通常不可能很好地均匀学习统计量,因此,我们将统计量集合中的平均近似误差形式化为近似封闭性的概念,如下所述。

现在,根据这个新概念,我们可以研究CDRL和QDRL的近似误差。尽管第4.1节中的分析表明,由于缺少Bellman封闭性,CDRL和QDRL必然会引起一些近似误差,但以下结果令人放心地表明,可以通过增加学习到的统计量的数量来任意减小近似误差。

两者都扩展了对CDRL和QDRL的现有分析。特别是,定理4.6改进了Rowland et al.(2018)的界限,定理4.7是QDRL的第一个近似结果;现有结果仅涉及W∞下的压缩映射(Dabney et al, 2017)。
4.3. Mean consistency
到目前为止,我们的讨论集中在评估上。对于控制而言,正确估计期望回报很重要,以便可以执行准确的策略改进。我们在以下结果中分析了在现有DRL算法中正确学习了期望回报的程度。CDRL的结果先前已经显示过(Rowland et al., 2018; Lyle et al., 2019),但是我们在这里的证明为统计提供了新的视角。

重要的是,对于EDRL,只要在统计数据集中包含1/2-期望(即平均值),就可以准确地学习期望回报;我们将在5.2节中回到这一点。
5. Experimental results
我们首先以表格形式的EDRL展示结果,以说明和扩展第3和4节中介绍的理论结果。然后,我们将EDRL更新与DQN风格的架构结合起来,以创建新颖的深度RL算法(ER-DQN),并评估Atari-57环境的性能。我们在附录D.1中提供了实验中使用的结构的完整详细信息。
在实践中可以通过多种方式解决寻根/优化问题(7)和(8)。在我们的实验中,我们使用SciPy优化例程(Jones et al., 2001)。
5.1. Tabular policy evaluation
我们经验证明,与第3.1节所述的简单方法相比,使用示例插补策略的EDRL能更好地近似于策略回报分布的真实期望。然后,我们证明QDRL的变体也是如此。
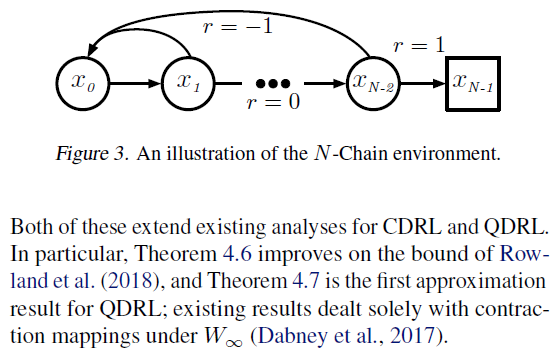
我们使用经典的N链域的变体(请参见图3)。该环境是一个长度为N的一维链,在每个状态下都有两个可能的动作:(i)forward,将智能体以0.95的概率向右移动一步,以0.05的概率向x0移动,然后backward,将智能体向x0移动的概率为0.95,向右移动的概率为0.05。转换为最左边的状态时的奖励为-1,转换为最右边的状态时的奖励为+1,而其他位置为0。episode从最左边的状态开始,到最右边的状态终止。折扣因子是γ = 0.99。对于长度为15的N链,我们计算最优策略的回报分布,该最优策略在每个状态下选择forward动作。随着与目标状态的距离增加,这种环境公式在策略下会导致越来越多的多模态回报分布。我们根据策略π*下1000个蒙特卡洛部署的经验分布来计算真实初始状态期望。
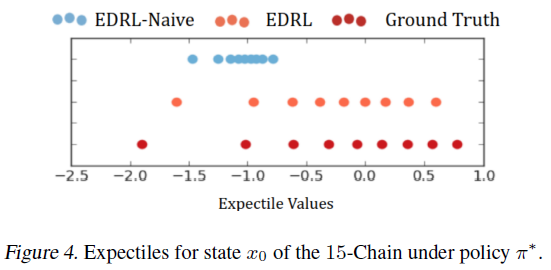
EDRL. 我们在此N链环境中运行了两种DRL算法:(i)EDRL,在每个步骤中使用SciPy优化例程插补目标样本;(ii)EDRL-Naive,使用第3.1节中所述的更新。我们学习了{1, 3, 5, 7, 9}期望,将学习率设置为α = 0.05,并执行30000个训练步骤。
在图4中,我们说明了由EDRL-Naive算法使用9个期望学习的初始状态期望的崩溃,这导致很高的期望估计误差,如定义4.5中所述。在图5中,我们表明该误差随着到目标状态的距离和学习到的期望的增加而增加。相反,在EDRL中,这些误差要低得多。对于不同数量的期望和到EDRL目标的距离,该误差仍然相对较低。在附录E中,我们说明了这种观察可以推广到N链中的其他回报分布。

QDRL. 在实际的实现中,QDRL通常使Huber分位数损失最小化:
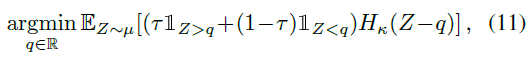
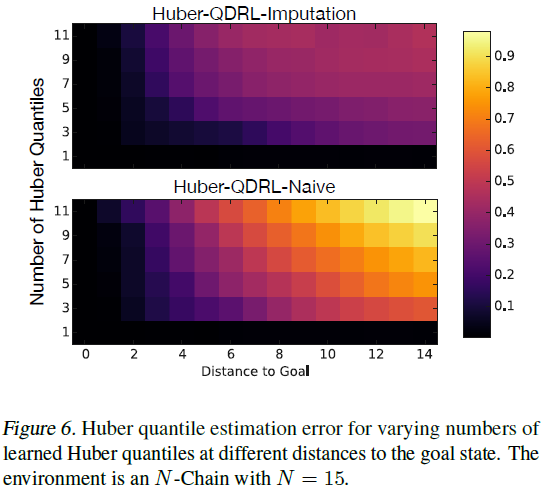
而不是分位数损失(4)以获得数值稳定性,其中Hκ是具有宽度参数的Huber损失函数,如Dabney et al.(2017)所述(我们设定κ = 1)。与幼稚的EDRL一样,简单地用等式(11)代替QDRL中的分位数回归损失会使样本和统计量膨胀,导致分布的近似值变差。我们提出了一种学习Huber分位数的新算法,Huber-QDRL-Imputation,该算法通过解决类似于Huber分位数损失的(8)的优化问题,结合了插补策略。在图6中,我们将其与在N链环境中学习Huber分位数的标准算法Huber-QDRL-Naive进行了比较。与预期情况一样,使用插补策略时,Huber分位数估计误差会大大降低。
5.2. Tabular control
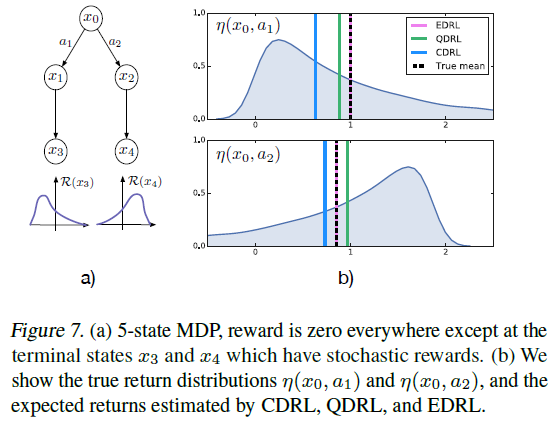
在第4.3节中,我们讨论了均值一致性的重要性。在图7a中,我们给出了一个简单的五状态MDP,其中学习到的控制策略直接受到均值一致性的影响。在初始状态x0,智能体可以选择两个动作,即沿着两个路径前进并最终达到两个不同的奖励分布。终止状态x3和x4处的奖励分别从密度为![]() 和
和![]() 的(移位)指数分布中采样。转换是确定性的,且γ=1。对于CDRL,我们将容器位置设为(z1, z2, z3)=(0, 1, 2)。
的(移位)指数分布中采样。转换是确定性的,且γ=1。对于CDRL,我们将容器位置设为(z1, z2, z3)=(0, 1, 2)。
图7b显示了真实的回报分布,它们的期望以及由CDRL,QDRL和EDRL估算的均值。由于缺乏平均一致性,CDRL和QDRL都学习了局部最优的贪婪策略。对于CDRL,这是由于真正的回报分布有在[0, 2]外的支持,对于QDRL,这是由于分位数没有捕获尾部行为。相反,EDRL正确地学习了两种回报分布的均值,因此能够发挥最优作用。
5.3. Expectile regression DQN
为了大规模展示EDRL的有效性,我们将算法2中的EDRL更新与QR-DQN的架构相结合,以获得新的深度RL智能体,期望回归DQN(ER-DQN)。有关结构,训练算法和环境的详细信息,请参阅附录D。我们使用Arcade学习环境对一套57种Atari游戏进行了ER-DQN评估(Bellemare et al., 2013)。 在图8中,我们绘制了具有11个原子的ER-DQN的平均数和中位数的人为归一化分数,并与DQN,QR-DQN(可学习200个Huber分位数统计量)和未使用一种插补策略的ER-DQN的简单实现进行比较,学习201个期望。本文重新运行所有方法,并将结果在3个种子中进行平均。在实践中,我们发现,相对于其他方法,ER-DQN在11个期望上已经提供了强大的性能,并且通过如此大量的统计,由于SciPy优化程序调用而导致的额外训练开销很低。

在人为归一化分数均值方面,ER-DQN相对于QR-DQN和未使用插补策略的朴素版本的ER-DQN都取得了实质性的进步。我们假设EDRL的平均一致性(与其他DRL方法相反;请参阅第4.3节)部分地归因于这些改进,因此,我们将进一步研究DRL中的平均一致性在未来工作中的作用。我们还指出,ER-DQN的性能表明,将本文开发的框架应用于其他统计族可能具有重大的实用价值。是否存在部分可观察性可能会引起非平凡的分布还有待观察,这也可以解释ER-DQN在某些游戏中的性能提高。对于所使用的精确插补策略,对ER-DQN的鲁棒性进行调查也是以后工作的自然问题。
6. Conclusion
我们已经从统计估计量和插补策略方面为DRL开发了一个统一的框架。通过这个框架,我们开发了一种新的算法EDRL,并提出了对现有方法的算法调整。 我们还使用此框架来定义Bellman封闭性的概念,并为现有算法提供了新的近似保证。
本文还为将来的研究开辟了一些途径。首先,插补策略框架有可能被广泛应用于各种统计量收集中,从而为探索新算法开辟了广阔空间。其次,我们的分析表明,缺乏Bellman封闭性必然会在许多DRL算法中引入近似误差。有趣的是,它如何与函数逼近引入的误差相互作用。最后,我们关注于DRL算法,该算法可以解释为学习有限的统计量。一个值得注意的替代方法是隐式分位数网络(Dabney et al., 2018),该网络尝试使用有限容量的函数逼近器来学习不可数的分位数集合; 将我们的分析扩展到此设置也将很有趣。
Appendices
A. Distributional reinforcement learning algorithms
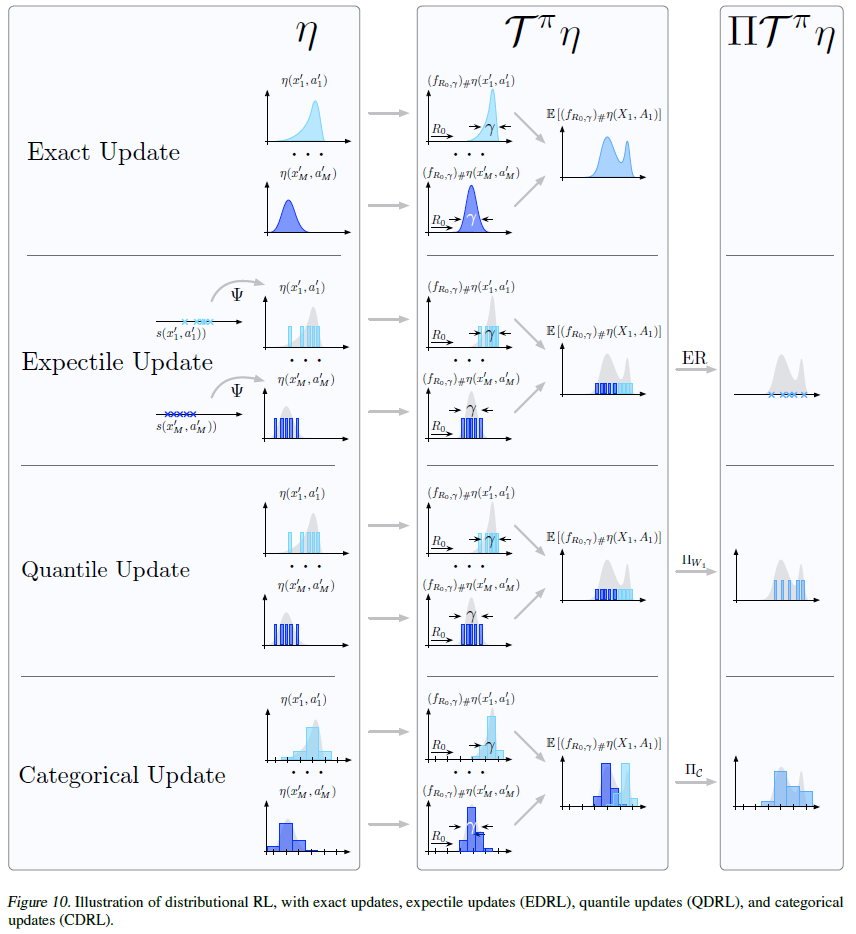
为了完整起见,我们在本节中对CDRL和QDRL算法进行了完整描述,并补充了第2.2节中提供的详细信息。在本节末尾的图10中,我们还总结了CDRL,QDRL,分布RL的确切方法以及我们提出的算法EDRL。
A.1. The distributional Bellman operator

A.2. Categorical distributional reinforcement learning


A.3. Quantile distributional reinforcement learning

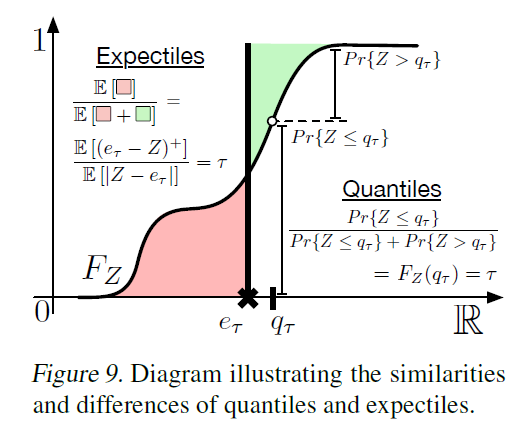
A.4. Quantiles versus expectiles

B. Proofs
B.1. Proofs of results from Section 3

B.2. Proofs of results from Section 4.1



B.3. Proofs of results from Section 4.2


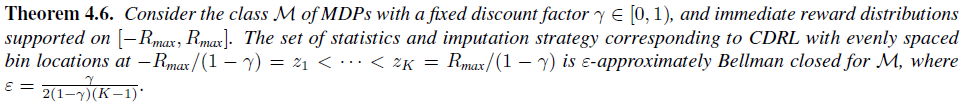





B.4. Proofs of results from Section 4.3

C. Additional theoretical results




D. ER-DQN experimental details
D.1. ER-DQN architecture

D.2. Training details
在6个Atari游戏的子集中,测试完0.00001、0.00003、0.00005、0.00007和0.0001的学习率之后,我们使用学习率为0.00005的Adam优化器。训练中的所有其他超参数都与(Dabney et al., 2017)中使用的参数相对应。特别地,从目标网络计算目标分布。请注意,每个训练遍历都需要调用SciPy优化器来计算插补样本,因此,与其他深度分布Q学习型智能体(例如C51和QR-DQN)相比,总体而言,其计算开销更大。 但是,通过并行化优化器要求在多个CPU上进行最小转换的调用,我们发现使用11个期望时的训练时间与QR-DQN的训练时间相当。
对于朴素的ER-DQN,我们发现使用201个期望与使用11个期望相比略有改进,因此在主论文中包括具有大量统计量的结果。我们根据与QR-DQN相同的方法采取τ1:201:线性间隔,其中τ1 = 1/(2 x 201)和τ201 = 1 - 1/(2 x 201)。
D.3. Environment details
我们使用Arcade学习环境(Bellemare et al., 2013)对57种Atari游戏进行训练和评估ER-DQN。环境的精确参数设置与在QR-DQN上进行的实验完全相同,以便进行直接比较。
D.4. Detailed results
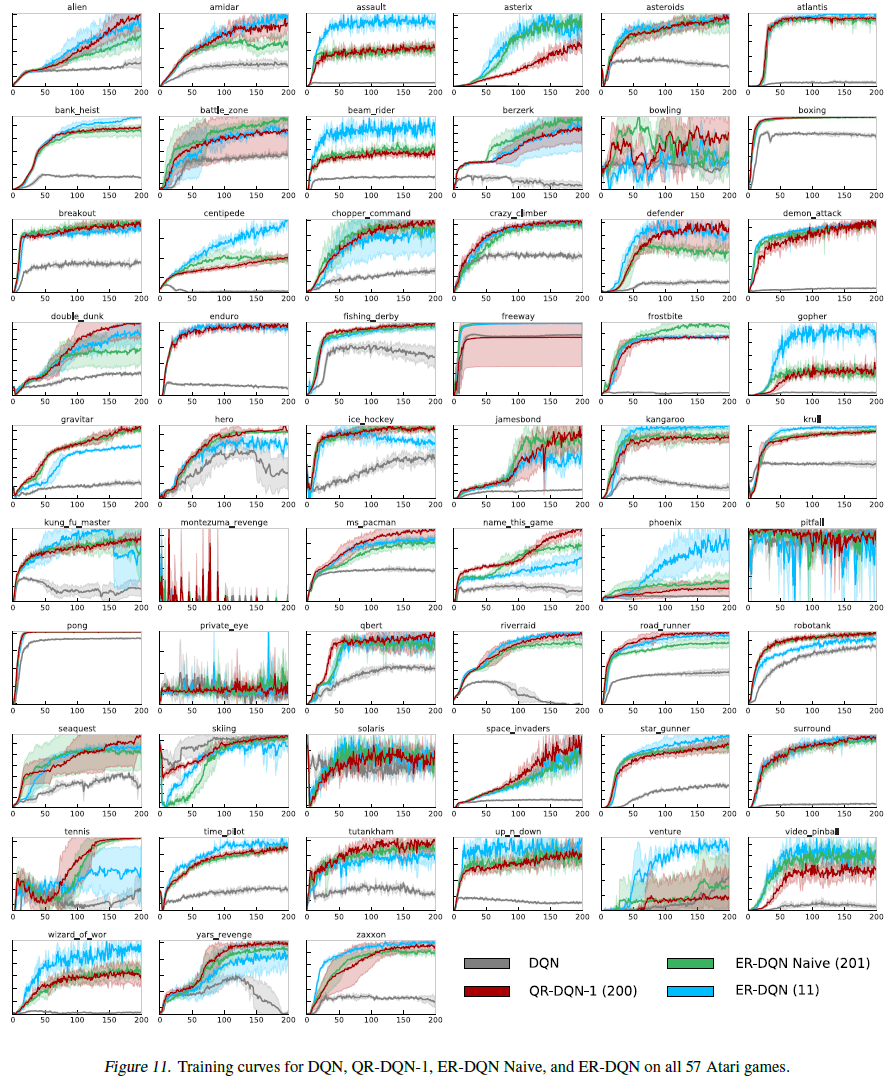
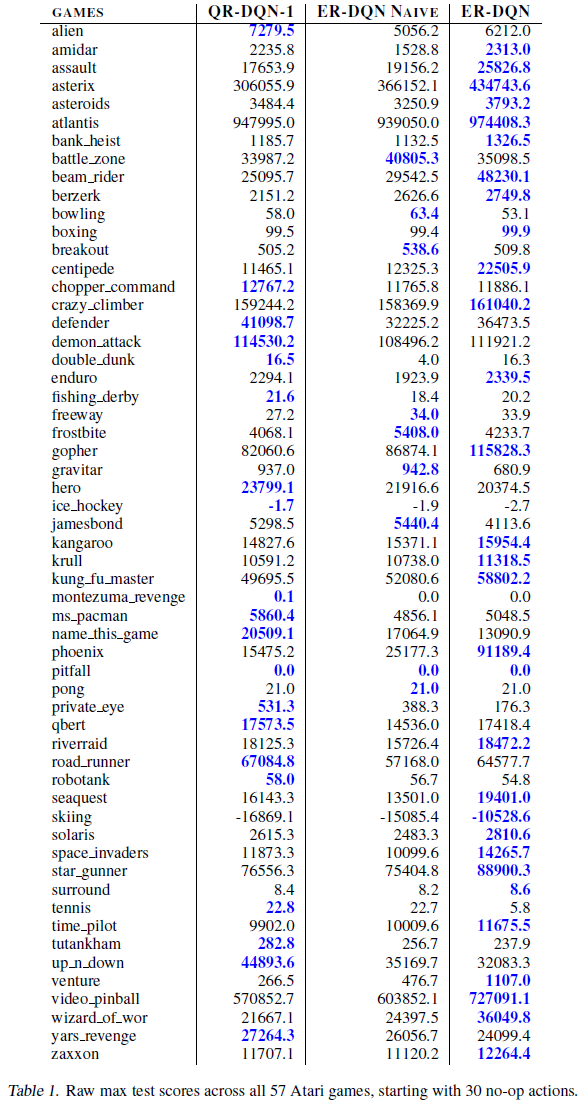
除了主要论文中给出的人为归一化均值/中位数结果外,我们还包括图11中所有57种Atari游戏中所有4种评估过的智能体的训练曲线,以及表1中获得的原始最大分数。
E. Additional experimental results
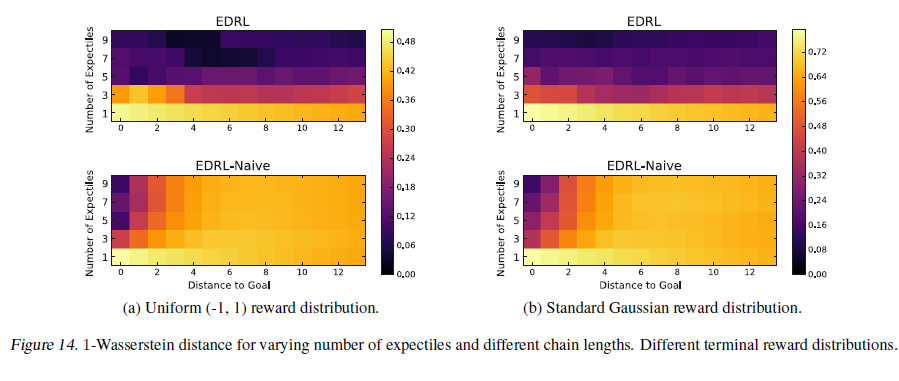
在第5.1节中,我们看到EDRL-Naive在长度为15的N链上学习到的期望出现崩溃,而EDRL学到的期望是回报分布的真实期望的合理近似。如定义4.5中所述,这导致后者的期望平均预期误差较低。在图12中,我们通过绘制用于学习的统计量的插补分布与真实回报分布之间的Wasserstein距离来补充这一点。这提供了一个替代度量,该度量另外指示了学习到的统计量收集汇总完整回报分布的程度。在此度量下,我们观察到,在EDRL下,增加期望的数量总是可以改进性能,而对于EDRL-Naive,对于大量的期望与/或距目标状态的距离,观察到较差的Wasserstein重建误差。
我们还包括具有不同奖励分布的N链环境的结果,观察到的定性现象与图12所示的相似。具体地说,我们在目标状态下使用了奖励分布的两个其他变体:均匀分布和高斯分布。我们在图13中绘制平均期望误差,并在图14中绘制插补回报与真实回报分布之间的Wasserstein距离。