郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ICLR, (2017)
ABSTRACT
在具有动态元素的复杂环境中学习导航是开发AI智能体的重要里程碑。在这项工作中,我们将导航问题表述为RL问题,并表明通过依靠利用多模式感官输入的额外辅助任务,可以显著提高数据效率和任务性能。特别是,我们考虑与辅助深度预测和闭环分类任务一起学习目标驱动的RL问题。这种方法可以在复杂的3D迷宫中从原始的感觉输入中学习导航,甚至在目标位置频繁变化的情况下也可以达到人类水平的性能。我们提供了对智能体行为,其定位能力及其网络活动动态的详细分析,表明该智能体隐式学习了关键的导航能力。
1 INTRODUCTION
在环境中有效导航的能力是智能行为的基础。传统的机器人方法(如同时定位与制图(SLAM))通过明确地专注于位置推断和制图来解决导航问题(Dissanayake et al., 2001),在此我们关注深度RL中的最新工作(Mnih et al., 2015; 2016),并提出导航能力可以作为学习策略以最大化奖励的智能体的副产品而出现。这种内在且端到端方法的一个优点是动作不会与表征分离,而是共同学习,从而确保表征中存在与任务相关的特征。然而,在部分可观察的环境中学习从RL中导航会带来一些挑战。
首先,奖励通常很少分布在可能只有一个目标位置的环境中。其次,环境通常包含动态元素,要求智能体在不同的时间范围内使用内存:快速one-shot内存(用于目标位置),短期内存(用于保存速度信号和视觉观测的时间积分),以及长期内存(用于环境的恒定方面)(例如边界,线索)。
为了提高统计效率,我们通过使用辅助任务来增强损失,从而自举RL过程,这些辅助任务提供了支持导航相关表征学习的更密集的训练信号。我们考虑了两个额外损失:第一个涉及通过从其他输入通道(颜色通道)预测一个输入模态(深度通道),在每个时间步骤重建低维深度图。此辅助任务涉及环境的3D几何形状,旨在鼓励学习有助于避障和短期轨迹规划的表征。第二项任务直接从SLAM调用闭环:训练智能体以预测当前位置是否先前已在本地轨迹中访问过。
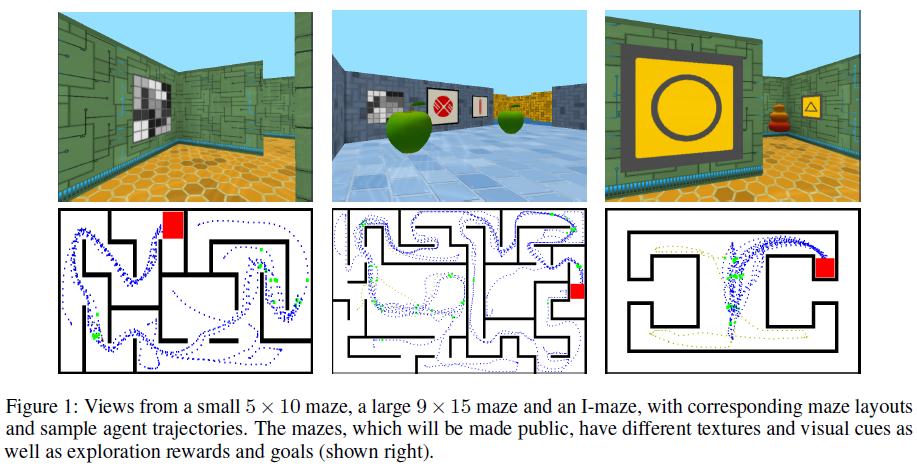
为了解决任务的内存需求,我们依赖于堆叠式LSTM架构(Graves et al., 2013; Pascanu et al., 2013)。我们使用五个3D迷宫环境评估了我们的方法,并演示了所提议的智能体架构的学习加速和性能提高。这些环境具有复杂的几何结构,随机的起始位置和方向,动态的目标位置以及需要数千个智能体步骤的长回合(参见图1)。我们还提供对受过训练的智能体的详细分析,以显示获得关键的导航技能。这很重要,因为位置推断和映射都不是损失的直接部分;因此,目标发现任务的原始性能并不一定是获得这些技能的良好标志。特别是,我们表明提出的智能体解决了模糊的观察并迅速将自己定位在复杂的迷宫中,并且这种定位能力与更高的任务奖励相关。
2 APPROACH
我们依赖于包含多个目标的端到端学习框架。首先,它尝试使用actor-critic方法来最大化累积奖励。其次,它最小化了从RGB观察推断深度图的辅助损失。最后,训练该智能体以检测闭环,作为鼓励隐式速度积分的额外辅助任务。
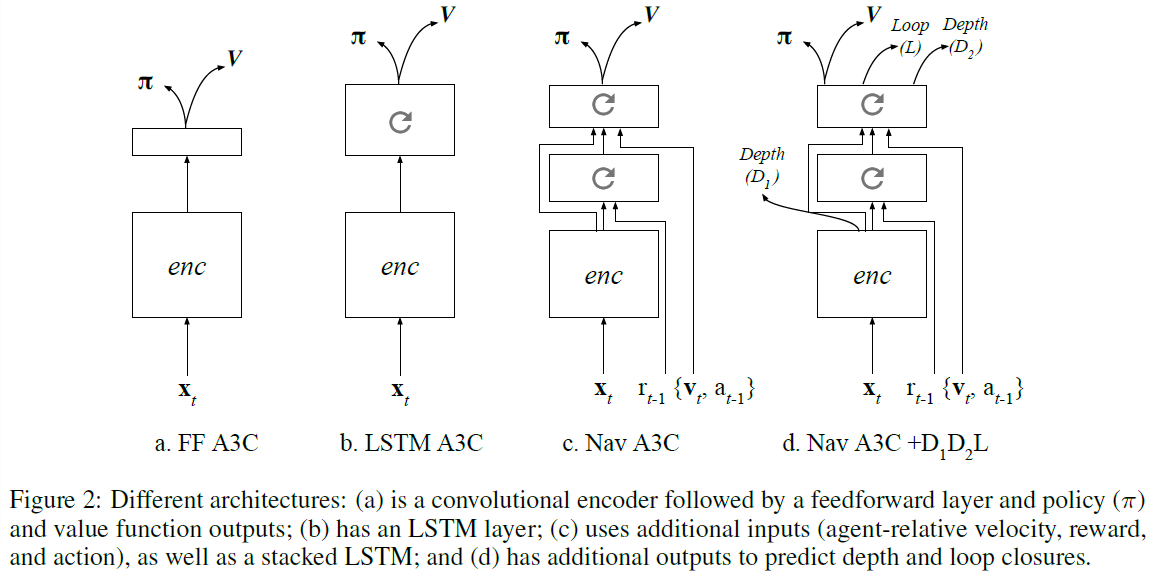
RL问题通过A3C算法(Mnih et al., 2016)解决,该算法既依赖于学习策略π(at|st; θ),也依赖于学习给定状态观察st的价值函数V(st; θV)。策略和价值函数均共享所有中间表征,两者均使用与模型最顶层不同的线性层进行计算。智能体的设置紧跟(Mnih et al., 2016)的工作,我们详细参考此项工作(例如使用卷积编码器后跟着MLP或LSTM,使用动作重复,熵正则化以防止策略饱和等)。这些详细信息也可以在附录B中找到。
我们在这项工作中考虑的基准是A3C智能体(Mnih et al., 2016),它使用循环模型或纯前馈模型仅从环境中接收RGB输入(请参见图2a, b)。RGB输入的编码器(用于所有其他考虑的结构)是3层卷积网络。为了支持我们方法的导航能力,我们还依赖于Nav A3C智能体(图2c),该智能体在卷积编码器之后采用了两层堆叠式LSTM。我们扩展对智能体的观察,以包括智能体相对速度,从随机策略中采样的动作以及从上一时间步骤获得的即时奖励。我们选择将速度和先前选择的动作直接提供给第二个循环层,而第一层仅接收奖励。我们假设第一层可能能够在奖励和视觉观察之间建立关联,这将作为上下文提供给从中计算策略的第二层。因此,观测值st可以包括图像xt ∈ R3xWxH (其中W和H是图像的宽度和高度),相对于智能体的横向和旋转速度vt ∈ R6,先前的动作at-1 ∈ ![]() ,以及先前的奖励rt-1 ∈ R。
,以及先前的奖励rt-1 ∈ R。
图2d显示了Nav A3C的增强以及不同的可能辅助损失。特别是,我们考虑从卷积层(将这种选择称为D1),从顶层LSTM层(D2)或从闭环(L)来预测深度。通过单层MLP在当前帧上计算辅助损失。通过应用来自A3C的梯度,来自深度预测的梯度(乘以βd1, βd2)和来自闭环的梯度(按βl缩放)的加权和来训练智能体。在线学习算法的更多细节在附录B中给出。
2.1 DEPTH PREDICTION
智能体的主要输入为RGB图像形式。但是,覆盖智能体中心视野的深度信息可能会提供有关环境3D结构的有价值信息。虽然深度可以直接用作输入,但我们认为,如果将其表示为额外损失,实际上对学习过程更有价值。特别是,如果预测损失与策略共享表征,则可以帮助更快地构建学习层,从而为RL建立有用的特征。由于我们从(Eigen et al., 2014)中知道单个帧就足以预测深度,因此我们知道可以学习此辅助任务。附录C中给出了将深度作为输入与额外损失之间的比较,该比较显示了深度作为损失的可观收益。
由于辅助损失的作用只是建立模型的表征,因此我们不必关心获得的特定性能或预测的性质。我们确实关心问题的数据效率方面以及计算复杂性。如果损失对主要任务有用,那么与解决RL问题(使用较少的数据样本)相比,我们应该在损失上收敛更快,并且额外计算成本应该最小。为此,我们使用深度图的低分辨率变体,将屏幕分辨率降低到4x16像素。
我们为损失探索了两种不同的变体。第一个选择是将其表述为回归任务,这是最自然的选择。虽然此公式结合较高的深度分辨率可以提取最多的信息,但均方差强加了单峰分布(van den Oord et al., 2016)。为了解决这个可能的问题,我们还考虑了分类损失,其中每个位置的深度被离散为8个不同的波段。这些波段分布不均匀,因此我们更加关注遥远的物体(附录B中的详细信息)。分类公式的动机是,尽管它大大降低了深度分辨率,但从学习的角度来看,它更具灵活性,并且可以导致更快的收敛(因此可以更快地进行自举)。
2.2 LOOP CLOSURE PREDICTION
像深度一样,闭环对于导航智能体很有价值,因为它可以用于有效的探索和空间推断。为了产生训练目标,我们基于回合期间局部位置信息的相似性来检测闭环,这是通过将2D速度随时间积分而获得的。具体来说,在轨迹上记为{p0, p1, ... , pT},其中pt是时间 t 处的智能体位置,如果智能体的位置pt在较早的时间t0接近位置pt',则我们定义一个等于1的闭环标签lt。为了避免在轨迹的连续点上进行琐碎的闭环,我们在中间位置pt''远离pt的位置添加了额外条件。阈值1和2提供了这两个限制。通过最小化lt和模型最后一个隐含层的隐含表征ht的单层输出的输出之间的Bernoulli损失L1来学习预测二值环标签,然后进行sigmoid激活。
3 RELATED WORK
4 EXPERIMENTS
5 ANALYSIS
5.1 POSITION DECODING
为了评估智能体中位置的内部表征(以最后一个LSTM的隐含单位ht,或者对于FF A3C智能体,为conv-net的最后一层上的特征ft),我们训练一个以该表征为输入的位置解码器,该位置解码器由线性分类器组成,该线性分类器在离散迷宫位置上具有多项式概率分布。小迷宫(5 x 10)有50个位置,大迷宫(9 x 15)有135个位置,而I型迷宫有77个位置。请注意,我们不会反向传播从位置解码器到网络其余部分的梯度。位置解码器只能看到模型公开的表征,而不能更改它。
Nav A3C+D2智能体进行位置解码的示例如图6所示,其中随着智能体获取更多的观测值,位置的初始不确定性提高到接近完美的位置预测。我们观察到复位后位置熵峰值,然后一旦智能体获得关于其位置的确定性就降低。另外,智能体位置解码的视频链接在附录A中。在这些复杂的迷宫中,对于实现目标而言,局部化很重要,看来位置精度和最终得分是相关的,如表1所示。前馈结构在具有静态目标的静态迷宫中仍然可以达到64.3%的精度,这表明编码器可以记住砝码中的位置,并且这种小迷宫可以由所有智能体解决,并且需要足够的训练时间。在"随机目标1"中,Nav A3C+D2实现了最优的位置解码性能(准确度为85.5%),而FF A3C和LSTM A3C结构的精度约为50%。
在I型迷宫中,迷宫的相对分支几乎相同,除了非常稀疏的视觉信号。我们观察到,一旦首次找到目标,Nav A3C*+D1L智能体便能够直接返回正确的分支以获取最大分数。但是,此智能体的线性位置解码器的准确度仅为68.5%,而在普通LSTM A3C智能体中为87.8%。我们假设I型迷宫的对称性将导致对称策略,该策略不必对智能体的确切位置敏感(请参阅下面的分析)。
在我们的"随机目标"任务中,导航智能体的期望属性是能够首先找到目标,并在随后的重新生成之后通过有效的路线可靠地返回目标。表1中的延迟列显示,一旦发现目标,Nav A3C+D2智能体达到目标的最低延迟(第一个数字显示第一次找到目标的时间(以秒为单位),第二个数字为后续发现的平均时间)。图5清楚地显示了智能体如何找到目标,并在剩余的回合中直接返回该目标。对于随机目标2,在初始目标获取后,没有任何智能体可以实现较低的延迟;这大概是由于更大且更具挑战性的环境所致。
5.2 STACKED LSTM GOAL ANALYSIS
图7(a)显示了智能体针对四个目标位置分别遍历的轨迹。在最初的探索阶段找到目标之后,智能体始终返回目标位置。我们通过对四个目标位置的每个位置,在智能体的每个步骤中对单元格激活应用tSNE降维(Maaten&Hinton, 2008)来直观化智能体的策略。在LSTM A3C智能体中,与四个目标位置的每个相对应的簇明显不同,而在Nav A3C智能体中,有两个主要簇——迷宫对角相对臂的轨迹具有相似表示。考虑到相对臂的动作序列是相同的(例如,直行,左转两次为了左上角和右下角目标位置),这表明Nav A3C策略指示LSTM保持了2个子策略的有效表征(即,不是4个独立策略)——包含有关其他LSTM提供的当前相关目标的重要信息。
5.3 INVESTIGATING DIFFERENT COMBINATIONS OF AUXILIARY TASKS
我们的结果表明,根据策略LSTM进行深度预测会产生最优结果。然而,(Jaderberg et al., 2017)同时引入了其他一些辅助任务,因此我们提供了奖励预测与深度预测的比较。在那篇论文之后,我们实现了两种额外的智能体架构,一种使用回放缓存从convnet中执行奖励预测,称为Nav A3C*+R,另一种将convnet的奖励预测与LSTM (Nav A3C+RD2)的深度预测相结合。表2表明奖励预测(Nav A3C*+R)在普通堆叠式LSTM结构(Nav A3C*)上有所改进,但没有策略LSTM (Nav A3C+D2)的深度预测那么大。结合奖励预测和深度预测(Nav A3C+RD2)可以得到与仅深度预测(Nav A3C+D2)可比的结果;归一化的平均AUC值分别为0.995和0.981。未来的工作将探索额外辅助任务。
6 CONCLUSION
我们提出了一种深度RL方法,并增加了记忆和辅助学习目标,以训练这女人在大型且视觉丰富的环境中导航,这些环境包括频繁变化的开始和目标位置。我们的结果和分析突出显示了无/自监督辅助目标(即深度预测和闭环)在提供更丰富的训练信号(自举学习并提高数据效率)中的实用性。此外,我们分析了受过训练的智能体的行为,它们的定位能力以及网络活动动态,以分析其导航能力。
我们用辅助目标增强深度RL的方法允许进行最终学习,并可能鼓励开发更通用的导航策略。值得注意的是,我们与辅助损失有关的工作与(Jaderberg et al., 2017)有关,后者在利用辅助损失时独立地研究数据效率。两件工作之间的区别在于,我们的辅助损失是在线的(针对当前帧),并且不依赖于任何形式的回放。同样,探索的损失在性质上也有很大不同。最后,我们的重点是导航领域,并了解导航是否会作为解决RL问题的副产品而出现,而Jaderberg et al. (2017)则关注任何RL任务的数据效率。
虽然我们表现最好的智能体在导航方面相对成功,但是由于堆叠式LSTM在这方面的能力有限,如果对快速存储(例如程序生成的迷宫)提出了更高的要求,那么它们的能力将会得到扩展。将来,将视觉上复杂的环境与利用外部内存的结构结合起来很重要(Graves et al., 2016; Weston et al., 2014; Olton et al., 1979),以增强智能体的导航能力。此外,尽管这项工作专注于研究辅助任务对开发端到端深度RL的能力的好处,但将来的工作将这些技术与基于SLAM的方法进行比较将是有趣的。
Supplementary Material
A VIDEOS OF TRAINED NAVIGATION AGENTS
B NETWORK ARCHITECTURE AND TRAINING
B.1 THE ONLINE MULTI-LEARNER ALGORITHM FOR MULTI-TASK LEARNING
我们介绍了一类基于神经网络的智能体,这些智能体具有模块化结构,并经过多项任务训练,输入来自不同的模态(视觉,深度,过去的奖励和过去的动作)。模块化结构简化了实现我们的智能体架构的过程。本质上,我们使用共享的构建基块构建多个网络(每个任务一个),并共同优化这些网络。一些模块(例如用于感知视觉输入的conv-net或用于学习导航策略的LSTM)在多个任务之间共享,而其他模块(例如深度预测器gd或闭环预测器gl)则是特定于任务的。使用强化学习来训练输出策略和价值函数的导航网络,而使用自监督学习来训练深度预测和闭环预测网络。
在异步训练环境的每个线程中,智能体会在自己的游戏环境中进行游戏,因此会看到观察和奖励对{(st, rt)},并采取与其他智能体所经历的不同的动作(并行线程)。在一个线程中,可以按照自己的时间表来训练多个任务(导航,深度和闭环预测),并且在它们到达时将梯度添加到共享参数向量中。在每个线程中,我们使用基于标志的系统来对A3C强化学习过程进行梯度更新。
B.2 NETWORK AND TRAINING DETAILS
对于所有实验,我们使用一个编码器模型,该模型具有2个卷积层,然后是一个全连接层或循环层,从中可以预测策略和价值函数。该架构类似于(Mnih et al., 2016)中的架构。卷积层如下。第一个卷积层的核大小为8x8,步长为4x4,并具有16个特征图。第二层具有大小为4x4,步长为2x2的核以及32个特征图。在图2a的FF A3C架构中,全连接层具有256个隐含单元(并输出视觉特征ft)。LSTM A3C结构中的LSTM具有256个隐含单元(并输出LSTM隐含激活ht)。图2c和2d中的LSTM被提供了额外的输入(先前的奖励rt-1,先前的动作at被表示为8维的one-hot向量,以及由6维向量编码的相对于智能体的横向和旋转速度vt, Nav A3C结构(图2c, d)的第一个LSTM具有64或128个隐含单元,第二个LSTM具有256个隐含单元。深度预测器模块![]() 和闭环检测模块gl都是具有128个隐含单元的单层MLP。深度MLP之后是64个独立的8维softmax输出(每个深度像素一个)。闭环MLP之后是二维softmax输出。我们在图8上说明了Nav A3C+D+L+Dr智能体的结构。
和闭环检测模块gl都是具有128个隐含单元的单层MLP。深度MLP之后是64个独立的8维softmax输出(每个深度像素一个)。闭环MLP之后是二维softmax输出。我们在图8上说明了Nav A3C+D+L+Dr智能体的结构。
(省略)
C ADDITIONAL RESULTS
C.1 REWARD CLIPPING
C.2 DEPTH PREDICTION AS REGRESSION OR CLASSIFICATION TASKS
C.3 NON-NAVIGATION TASKS IN 3D MAZE ENVIRONMENTS
C.4 SENSITIVITY TOWARDS HYPER-PARAMETER SAMPLING
C.5 ASYMPTOTIC PERFORMANCE OF THE AGENTS