郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
论文笔记:https://zhuanlan.zhihu.com/p/26754280
Arxiv:https://arxiv.org/pdf/1509.02971.pdf

Published as a conference paper at ICLR 2016
ABSTRACT
我们将“深度Q学习”成功的基础思想适应于连续动作域。我们基于可在连续动作空间上运行的确定性策略梯度,提出了一种基于actor-critic的无模型算法。使用相同的学习算法,网络结构和超参数,我们的算法可以鲁棒地解决20多个模拟物理任务,包括经典问题,例如车杆摆动,灵巧操纵,有腿运动和驾车。我们的算法能够找到性能与计划算法相媲美的策略,并且可以完全访问域及其衍生物的动态。我们进一步证明,对于许多任务,该算法可以直接从原始像素输入中学习“端到端”策略。
1 INTRODUCTION
AI领域的主要目标之一是解决未经处理的高维感官输入中的复杂任务。最近,通过将深度学习中的感官处理(Krizhevsky et al., 2012)与RL相结合,取得了显著进展,从而产生了DQN算法(Mnih et al., 2015)。使用许多未经处理的像素作为输入,可以在许多Atari视频游戏上达到人类水平的性能。为此,使用了深度神经网络函数近似来估计动作-价值函数。
但是,尽管DQN解决了高维观测空间的问题,但它只能处理离散低维动作空间。许多令人关注的任务,尤其是物理控制任务,具有连续(实值)高维动作空间。DQN不能直接应用于连续域,因为DQN依赖于找到使动作-价值函数最大化的动作,在连续价值的情况下,每个步骤都需要迭代优化过程。
使深度RL方法(如DQN)适应连续领域的一个明显方法是简单地对动作空间进行离散化。但是,这有很多局限性,最明显的是维数诅咒:动作的数量随自由度的增加呈指数增长。例如,一个自由度为7的系统(如在人的手臂中),若离散度为ai ∈ {-k, 0, k},这导致维度为37 = 2187的动作空间。对于需要精细控制动作的任务,情况甚至更糟,因为它们需要相应地更细化的离散化,从而导致离散动作数量激增。如此大的动作空间很难有效探索,因此在这种情况下成功地训练DQN类型的网络可能很棘手。此外,动作空间的幼稚离散化会不必要地丢弃有关动作域结构的信息,这对于解决许多问题可能是必不可少的。
在这项工作中,我们提出了一种使用深度函数近似的无模型异策的actor-critic算法,该算法可以学习高维连续动作空间中的策略。我们的工作基于DPG算法(Silver et al., 2014) (其本身类似于NFQCA (Hafner&Riedmiller, 2011),类似的想法可以在(Prokhorov et al., 1997)中找到)。但是,正如我们在下面显示的那样,这种针对actor-critic的方法与神经函数近似的幼稚应用对于具有挑战性的问题来说是不稳定的。
在这里,我们结合了actor-critic方法和最近从DQN成功获得的见解(Mnih et al., 2013; 2015)。在DQN之前,通常认为使用大型非线性函数近似学习价值函数既困难又不稳定。由于以下两项创新,DQN能够使用此类函数近似以稳定且鲁棒的方式学习价值函数:1. 使用回放缓存中的样本对网络进行异策训练,以最小化样本之间的相关性;2. 用目标Q网络训练网络,以在时序差分备份期间给出一致的目标。在这项工作中,我们利用了相同的思想以及批归一化(Ioffe&Szegedy, 2015),这是深度学习的最新进展。
为了评估我们的方法,我们构造了各种具有挑战性的物理控制问题,这些问题涉及复杂的多关节运动,不稳定且高接触动态以及步态行为。其中包括经典问题,例如车杆摆动问题以及许多新领域。机器人控制的长期挑战是直接从原始感官输入(例如视频)中学习动作策略。因此,我们将固定的视点相机放置在模拟器中,并尝试使用低维观测(例如,关节角度)以及直接从像素中进行所有任务。
我们称为深度DPG (DDPG)的无模型方法可以使用相同的超参数和网络结构,通过低维观察(例如笛卡尔坐标或关节角)来学习所有任务的竞争策略。在许多情况下,我们还能够直接从像素中学习良好的策略,再次使超参数和网络结构保持不变1。
该方法的一个关键特征是它的简单性:它只需要简单的actor-critic结构和学习算法,而很少有“运动部件”,因此易于实现并扩展到更困难的问题和更大的网络。对于物理控制问题,我们将我们的结果与规划器(Tassa et al., 2012)计算的基准进行比较,该基准可以完全访问底层的模拟动态及其派生函数(请参阅补充信息)。有趣的是,在某些情况下,即使从像素中学习时,DDPG有时仍会找到超出规划器性能的策略(规划器始终在底层的低维状态空间上进行规划)。
1 可以在https://goo.gl/J4PIAz上观看一些学到的策略的视频
2 BACKGROUND
我们考虑一个标准的RL设置,该设置包括由智能体在离散时间步骤中与环境E交互。智能体在每个时间步骤 t 收到观察值xt,采取动作at,并收到标量奖励rt。在此处考虑的所有环境中,动作均为实值![]() 。通常,可能会部分观察环境,因此可能需要观察的整个历史记录,动作对st = (x1, a1, ... , at-1, xt)来描述状态。在这里,我们假设环境是完全观察到的,因此st = xt。
。通常,可能会部分观察环境,因此可能需要观察的整个历史记录,动作对st = (x1, a1, ... , at-1, xt)来描述状态。在这里,我们假设环境是完全观察到的,因此st = xt。
智能体的行为由策略π定义,该策略将状态映射到动作上的概率分布π:S → P(A)。环境E也可能是随机的。我们将其建模为具有状态空间S,动作空间![]() ,初始状态分布p(s1),转换动态p(st+1|st, at)和奖励函数r(st, at)的马尔可夫决策过程。
,初始状态分布p(s1),转换动态p(st+1|st, at)和奖励函数r(st, at)的马尔可夫决策过程。
状态回报定义为折扣未来奖励总和![]() (折扣因子γ ∈ [0, 1])。请注意,回报取决于所选择的动作,因此取决于策略π,并且可能是随机的。RL的目标是学习一种策略,该策略可以使初始分布
(折扣因子γ ∈ [0, 1])。请注意,回报取决于所选择的动作,因此取决于策略π,并且可能是随机的。RL的目标是学习一种策略,该策略可以使初始分布![]() 的期望收益最大化。我们将策略π的折扣状态访问分布表示为ρπ。
的期望收益最大化。我们将策略π的折扣状态访问分布表示为ρπ。
动作-价值函数用于许多RL算法中。它描述了在状态st处采取动作at并遵循策略π后的期望回报:
![]()
RL中的许多方法都使用称为Bellman方程的递归关系:
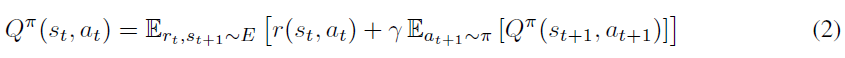
如果目标策略是确定性的,我们可以将其描述为函数μ:S ← A,并避免内在期望:
![]()
期望仅取决于环境。这意味着可以使用从不同的随机行为策略β生成的转换来异策学习Qμ。
Q学习(Watkins&Dayan, 1992)是一种常用的异策算法,它使用贪婪策略![]() 。我们考虑由θQ参数化的函数近似,通过使损失最小化来对其进行优化:
。我们考虑由θQ参数化的函数近似,通过使损失最小化来对其进行优化:
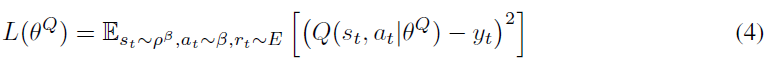
其中
![]()
尽管yt也取决于θQ,但通常会忽略它。
过去,由于理论上的性能保证是不可能的,并且实际上学习趋于不稳定,因此过去常常避免使用大型的非线性函数近似来学习价值或动作-价值函数。最近,(Mnih et al., 2013; 2015)改进了Q学习算法,以便有效地利用大型神经网络作为函数近似。他们的算法能够从像素上学习玩Atari游戏。为了扩展Q学习,他们引入了两个主要更改:使用回放缓存以及用于计算yt的单独目标网络。我们在DDPG中使用它们,并在下一部分中说明它们的实现。

3 ALGORITHM
无法将Q学习直接应用于连续动作空间,因为在连续空间中,寻找贪婪策略需要在每个时间步骤进行at的优化。对于大型无约束的函数近似和非平凡的动作空间,此优化速度太慢,无法实用。取而代之的是,这里我们使用基于DPG算法的actor-critic方法(Silver et al., 2014)。
DPG算法维护参数化的actor函数μ(s|θμ),该actor函数通过确定性地将状态映射到特定动作来指定当前策略。像Q学习一样,使用Bellman方程学习critic Q(s, a)。actor通过将链式规则应用于初始分布J的期望回报对actor参数进行更新:
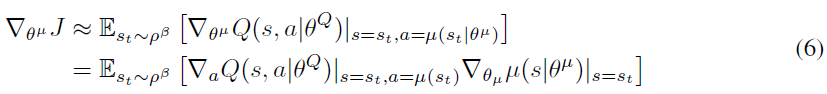
Silver et al. (2014)证明这是策略梯度,即策略性能的梯度2。
与Q学习一样,引入非线性函数近似意味着不再保证收敛。但是,这样的近似器对于在大型状态空间上进行学习和推广显得至关重要。NFQCA (Hafner&Riedmiller, 2011)使用与DPG相同的更新规则,但具有神经网络函数近似器,它使用批处理学习来保持稳定性,这对于大型网络来说是很难解决的。小批量版本的NFQCA不会在每次更新时重置策略(扩展到大型网络将需要重置该策略)与原始DPG等效,我们在此处进行了比较。我们的贡献是,根据DQN的成功经验,对DPG进行修改,使其能够使用神经网络函数近似在大型状态和动作空间中在线学习。我们将算法称为深度DPG (DDPG, 算法1)。
使用神经网络进行RL时的一个挑战是,大多数优化算法都假定样本是独立且均匀分布的。显然,当在环境中通过顺序探索生成样本时,该假设不再成立。此外,为了有效利用硬件优化,必须以小批量学习而不是在线学习。
与DQN中一样,我们使用回放缓存来解决这些问题。回放缓存是有限大小的高速缓存R。根据探索策略从环境中对转换进行采样,并将元组(st, at, rt, st+1)存储在回放缓存中。当回放缓存已满时,将丢弃最早的样本。在每个时间步骤,通过从缓存均匀采样小批量来更新actor和critic。由于DDPG是一种异策算法,因此回放缓存可能很大,从而使该算法可以从一组不相关转换中学习而受益。
在许多环境中,用神经网络直接实现Q学习(等式4)证明是不稳定的。由于被更新的网络Q(s, a|Q)也用于计算目标价值(等式5),所以Q更新易于发散。我们的解决方案类似于(Mnih et al., 2013)中使用的目标网络,但针对actor-critic进行了修改,并使用“软”目标更新,而不是直接复制权重。我们分别创建actor和critic网络的副本Q'(s, a|θQ')和μ'(s|θμ'),用于计算目标价值。然后,通过使它们缓慢跟踪学到的网络来更新这些目标网络的权重:θ' ← τθ + (1 - τ)θ'(![]() )。这意味着目标价值受约束而变化缓慢,从而极大地改进了学习的稳定性。这种简单的变化使学习动作-价值函数的相对不稳定的问题更接近于监督学习的情况,对于该问题存在鲁棒的解决方案。我们发现,目标μ'和Q'都必须具有稳定的目标yi,以便始终如一地训练critic而不会产生发散。由于目标网络会延迟价值估计的传播,因此这可能会延缓学习。但是,在实践中,我们发现学习的稳定性远远超过了这一点。
)。这意味着目标价值受约束而变化缓慢,从而极大地改进了学习的稳定性。这种简单的变化使学习动作-价值函数的相对不稳定的问题更接近于监督学习的情况,对于该问题存在鲁棒的解决方案。我们发现,目标μ'和Q'都必须具有稳定的目标yi,以便始终如一地训练critic而不会产生发散。由于目标网络会延迟价值估计的传播,因此这可能会延缓学习。但是,在实践中,我们发现学习的稳定性远远超过了这一点。
从低维特征向量观测中学习时,观测的不同组成部分可能具有不同的物理单位(例如,位置与速度),并且范围可能会随环境而变化。这可能会使网络难以有效学习,并且可能使得难以找到具有不同状态价值规模的环境中普遍存在的超参数。
解决此问题的一种方法是手动缩放特征,以使它们在环境和单位之间处于相似范围内。我们通过适应深度学习的最新技术来解决此问题,该技术称为批归一化(Ioffe&Szegedy, 2015)。该技术将小批量样本中的每个维度归一化以具有单位均值和方差。此外,它保持均值和方差的移动平均,以在测试期间(在我们的情况下,在探索或评估期间)用于归一化。在深度网络中,通过确保每一层都接收到白化的输入,它用于使训练期间的协方差漂移最小化。在低维情况下,我们在动作输入之前对状态输入,μ网络的所有层以及Q网络的所有层进行了批归一化(补充材料中提供了网络的详细信息)。通过批归一化,我们能够有效地学习使用不同类型单位的许多不同任务,而无需手动确保单位在设定范围内。
在连续动作空间中学习的主要挑战是探索。诸如DDPG之类的异策算法的优势在于,我们可以独立于学习算法来处理探索问题。通过将从噪声过程N采样的噪声添加到我们的actor策略中,我们构建了一个探索策略μ':
![]()
可以选择N以适合环境。如补充材料中所述,我们使用了Ornstein-Uhlenbeck过程(Uhlenbeck&Ornstein, 1930)来生成时间相关的探索,以解决惯性物理控制问题中的探索效率(自相关噪声的类似用法在(Wawrzyński, 2015))。
2在实践中,就像在策略梯度实现中通常所做的那样,我们忽略了状态访问分布ρβ中的折扣。
4 RESULTS
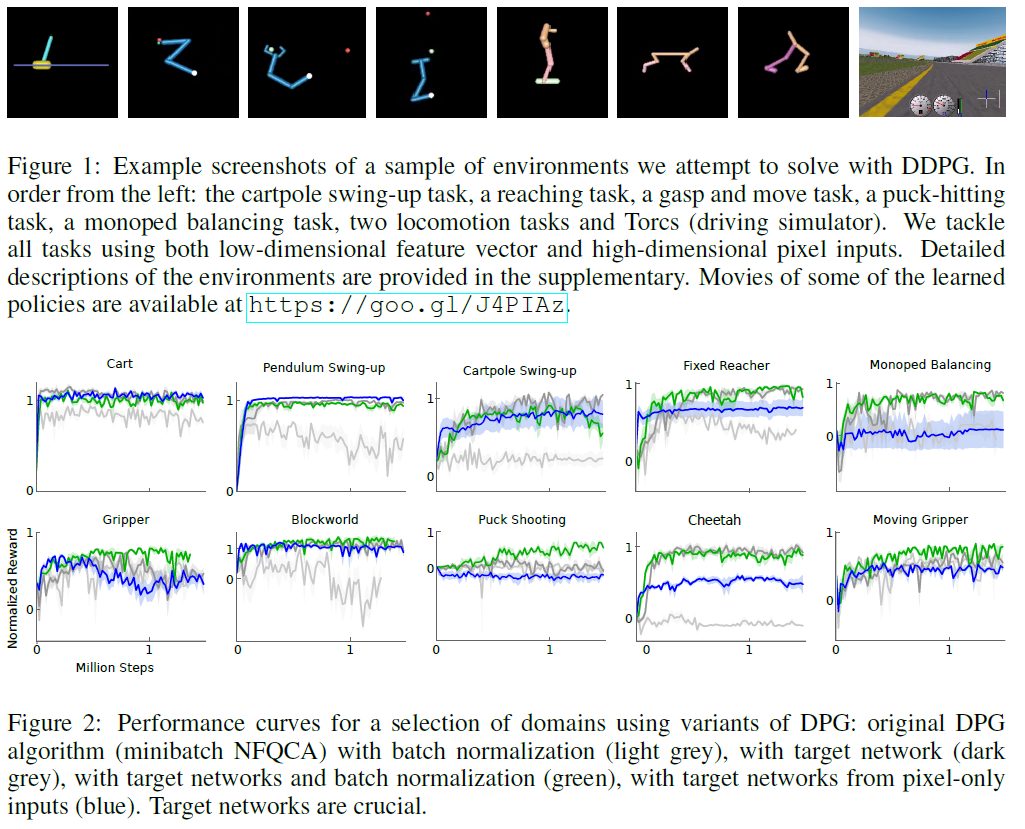
我们构建了难度不同的模拟物理环境来测试我们的算法。这包括经典RL环境,例如cartpole,以及困难的高维任务(例如gripper),涉及接触的任务(例如冰球击打(canada))和运动任务(例如cheetah)(Wawrzyński, 2009)。在除cheetah以外的所有领域中,动作都是施加在致动关节上的扭矩。这些环境使用MuJoCo进行了模拟(Todorov et al., 2012)。图1显示了任务中使用的某些环境的渲染图(补充内容包含环境的详细信息,你可以在https://goo.gl/J4PIAz上查看一些学到的策略)。
在所有任务中,我们都使用低维状态描述(例如关节角度和位置)和环境的高维渲染进行了实验。如在DQN中一样(Mnih et al., 2013; 2015),为了使这些问题在高维环境中几乎完全可见,我们使用动作重复。对于智能体的每个时间步骤,我们将仿真分为三个时间步骤,重复智能体的动作并每次渲染。因此,报告给智能体的观察结果包含9个特征图(3个渲染中每个的RGB),这使智能体可以使用帧之间的差异来推断速度。将帧下采样为64x64像素,并将8位RGB值转换为[0, 1]。有关我们的网络结构和超参数的详细信息,请参见补充信息。
我们在训练过程中定期测试该策略,而不会产生噪音。图2显示了所选环境的性能曲线。 我们还会报告删除了算法组成部分(即目标网络或批归一化)的结果。为了在所有任务上都能表现出色,这两个方面都是必需的。尤其是,在许多环境中,如没有DPG的原始工作那样,没有目标网络的学习就非常困难。
令人惊讶的是,在一些更简单的任务中,从像素学习策略与使用低维状态描述符学习一样快。这可能是由于重复动作使问题变得更简单。卷积层也可能提供状态空间的容易分离的表征,这对于较高的层来说可以快速学习。
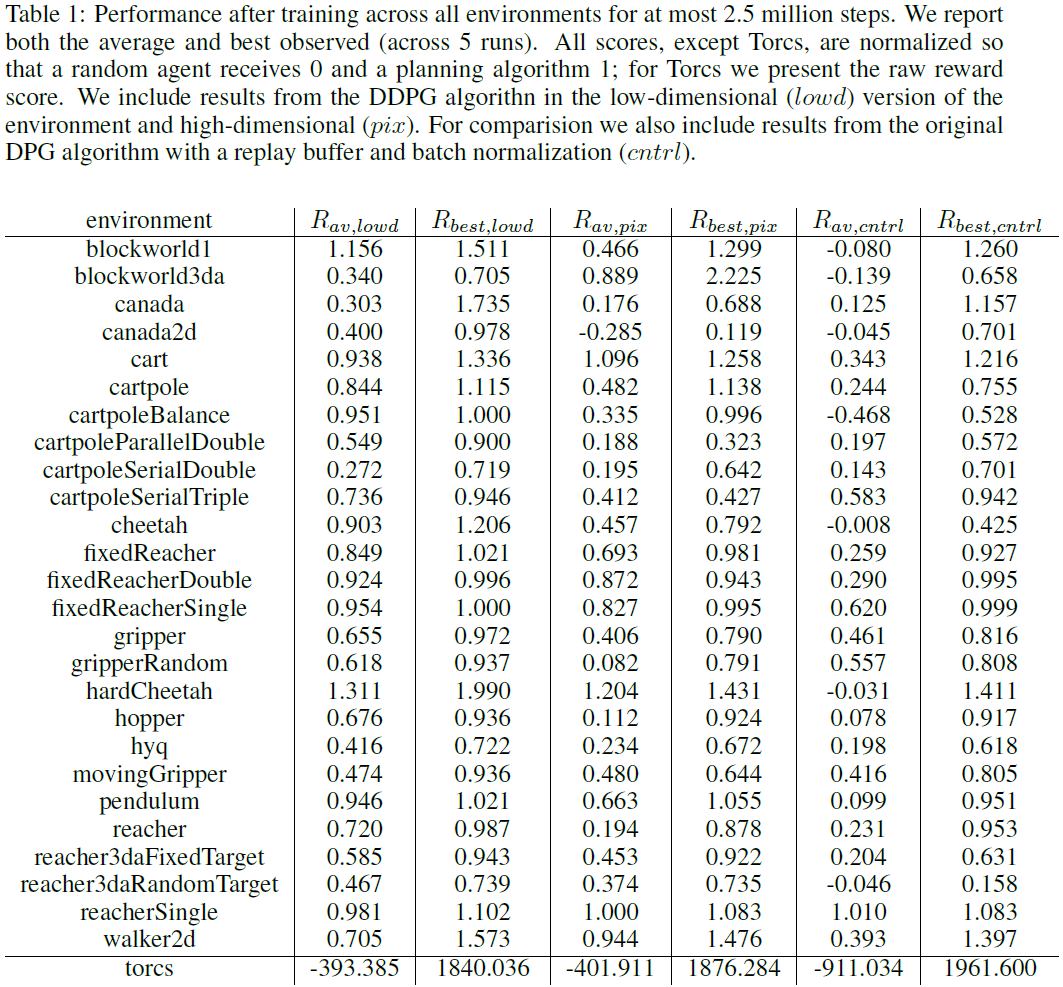
表1总结了DDPG在所有环境中的性能(结果是5个副本的均值)。我们使用两个基准对分数进行归一化。第一个基准是来自幼稚策略的平均回报,该策略从有效动作空间的均匀分布中采样动作。第二个基准是iLQG (Todorov&Li, 2005),它是一种基于规划的求解器,可以完全访问基础物理模型及其派生类。我们对分数进行归一化,使得幼稚策略的平均分数为0,iLQG的平均分数为1。DDPG能够在许多任务上学习良好的策略,并且在许多情况下,某些副本学习的策略优于 即使直接从像素学习时,iLQG所发现的那些策略。
学习准确的价值估计可能具有挑战性。例如,Q学习容易高估价值(Hasselt, 2010)。我们通过将训练后Q估计的价值与测试回合中看到的真实回报进行比较,从经验上检验了DDPG的估计。图3显示,在简单的任务中,DDPG可以准确估计回报,而不会产生系统性偏差。对于较困难的任务,Q估计会更糟,但是DDPG仍然可以学习良好的策略。
为了演示我们方法的通用性,我们还提供了Torcs,这是一款赛车游戏,其动作为加速,制动和转向。Torcs以前曾在其他策略学习方法中用作测试平台(KoutnÍk et al., 2014b)。我们对物理任务使用了相同的网络结构和学习算法超参数,但由于涉及的时间尺度非常不同,因此改变了探索的噪声过程。在低维和像素方面,一些副本能够学习合理的策略,尽管其他副本无法学习明智的策略,但它们能够完成轨道周围的电路。

5 RELATED WORK
最初的DPG论文使用图块编码和线性函数近似评估toy问题算法。它证明了异策DPG相对于同策和异策随机actor-critic的数据效率优势。它还解决了一项更具挑战性的任务,即多关节章鱼臂必须用肢体的任何部位击中目标。但是,该论文没有像我们在这里展示的那样将方法扩展到大型高维观察空间。
人们通常认为,标准策略搜索方法(如本工作中探索的方法)过于脆弱,无法扩展到棘手的问题(Levine et al., 2015)。人们认为标准策略搜索很困难,因为它同时处理复杂的环境动态和复杂的策略。实际上,过去使用actor-critic和策略优化方法进行的大多数工作都难以扩展到更具挑战性的问题上(Deisenroth et al., 2013)。通常,这是由于学习的不稳定性所致,其中问题的进展或者被后续的学习更新所破坏,或者学习太慢而无法实施。
无模型策略搜索的最新工作表明,它可能不像以前想象的那样脆弱。Wawrzyński (2009); Wawrzyński&Tanwani (2013)在actor-critic框架中使用回放缓存训练了随机策略。与我们的工作同时,Balduzzi&Ghifary (2015)通过“偏向器”网络扩展了DPG算法,该网络显式学习![]() 。但是,它们仅在两个低维域上训练。Heess et al. (2015)引入了SVG(0),它也使用Q-critic,但学习了随机策略。DPG可被视为SVG(0)的确定性限制。我们在此描述的用于扩展DPG的技术也可以通过使用重参数化技巧来应用于随机策略(Heess et al., 2015; Schulman et al., 2015a)。
。但是,它们仅在两个低维域上训练。Heess et al. (2015)引入了SVG(0),它也使用Q-critic,但学习了随机策略。DPG可被视为SVG(0)的确定性限制。我们在此描述的用于扩展DPG的技术也可以通过使用重参数化技巧来应用于随机策略(Heess et al., 2015; Schulman et al., 2015a)。
另一种方法是信任域策略优化(TRPO)(Schulman et al., 2015b),直接构建随机神经网络策略,而无需将问题分解为最优控制和监督阶段。通过对策略参数进行精心选择的更新,限制更新以防止新策略与现有策略相差太远,此方法可产生近乎单调的改进。这种方法不需要学习动作-价值函数,并且(可能因此)似乎大大降低了数据效率。
为了应对actor-critic方法的挑战,最近使用指导策略搜索(GPS)算法的工作(例如,(Levine et al., 2015))将问题分解为三个相对容易解决的阶段:首先,它使用全状态观测,以创建围绕一个或多个名义轨迹的动态的局部线性近似,然后使用最优控制沿着这些轨迹找到局部线性最优策略;最后,它使用监督学习来训练复杂的非线性策略(例如深度神经网络),以重现优化轨迹的状态到动作映射。
这种方法具有许多优势,包括数据效率,并且已成功地应用于使用视觉的各种现实世界中的机器人操纵任务。在这些任务中,GPS使用与我们类似的卷积策略网络,但有两个值得注意的例外:1. 它使用空间softmax将视觉特征的维数减少为每个特征图的单个(x, y)坐标,以及2. 它还在网络的第一个全连接层上接收有关机械手配置的直接低维状态信息。两者都可能提高算法的功能和数据效率,并且可以在DDPG框架中轻松利用。
PILCO (Deisenroth&Rasmussen, 2011)使用高斯过程来学习动态的非参数化概率模型。使用此学到的模型,PILCO可以计算分析策略梯度,并在许多控制问题中实现令人印象深刻的数据效率。然而,由于对计算的高需求,PILCO“对于解决高维问题不切实际”(Wahlström et al., 2015)。似乎深度函数近似是将RL扩展到大型高维域的最有前途的方法。
Wahlström et al. (2015)使用深度动态模型网络以及模型预测控制来解决像素输入的钟摆摆动任务。他们训练了一个可微的前向模型,并将目标状态编码到学到的潜在空间中。他们对学到的模型进行模型预测控制,以找到达到目标的策略。但是,此方法仅适用于目标状态可以向算法证明的域。
最近,进化方法已被用于使用压缩权重参数化(Koutník et al., 2014a)或无监督学习(Koutník et al., 2014b)来从像素中学习Torcs的竞争策略,以减小进化权重的维数。尚不清楚这些方法能否很好地推广到其他问题。
6 CONCLUSION
这项工作结合了深度学习和RL的最新进展中的见识,从而产生了一种算法,即使使用原始像素进行观察,该算法也可以通过连续的动作空间有效地解决跨多个领域的难题。与大多数RL算法一样,使用非线性函数近似会使收敛保证无效。但是,我们的实验结果表明,稳定的学习无需在环境之间进行任何修改。
有趣的是,与DQN学习在Atari域中找到解决方案所使用的经验步骤相比,我们所有的实验所使用的经验步骤少得多。我们研究的几乎所有问题都在250万步的经验之内得以解决(并且通常要少得多),这比DQN的Atari解决方案所需的步数减少了20倍。这表明,给定更多的仿真时间,DDPG可能会解决比此处考虑的还要困难的问题。
我们的方法仍然存在一些局限性。最明显的是,与大多数无模型强化方法一样,DDPG需要大量的训练集来找到解决方案。但是,我们认为,强大的无模型方法可能是大型系统的重要组成部分,可能会克服这些局限性(Glascher et al., 2010)。
Supplementary Information: Continuous control with deep reinforcement learning
7 EXPERIMENT DETAILS
我们使用Adam (Kingma&Ba, 2014)来学习神经网络参数,actor和critic的学习率分别为10-4和10-3。对于Q,我们使用L2权重衰减为10-2,并且使用折扣因子γ = 0.99。对于软目标更新,我们使用τ = 0.001。神经网络对所有隐含层使用校正后的非线性(Glorot et al., 2011)。actor的最终输出层是tanh层,用于绑定动作。低维网络具有2个隐含层,分别具有400和300个单位(约13万个参数)。直到Q的第二个隐含层才包括动作。从像素中学习时,我们使用了3个卷积层(无池化),每层有32个滤波。然后是两个全连接层,每个层有200个单元(约43万个参数)。actor和critic的最终层权重和偏差都是根据均匀分布[-3 x 10-3, 3 x 10-3]和[-3 x 10-4, 3 x 10-4]初始化的,分别用于低维和像素情况。这是为了确保策略和价值估计的初始输出接近零。其他层从均匀分布![]() 初始化,其中 f 是层的fan-in。直到全连接层才包括动作。我们针对低维度问题训练了小批量(64),对像素问题训练了小批量(16)。我们使用的回放缓存大小为106。
初始化,其中 f 是层的fan-in。直到全连接层才包括动作。我们针对低维度问题训练了小批量(64),对像素问题训练了小批量(16)。我们使用的回放缓存大小为106。
对于探索噪声过程,我们使用时间相关的噪声,以便在具有动量的物理环境中进行良好的探索。我们使用了Ornstein-Uhlenbeck过程(Uhlenbeck&Ornstein, 1930),其中θ = 0.15和σ = 0.2。Ornstein-Uhlenbeck过程对带有摩擦的布朗粒子的速度进行建模,从而得出以0为中心的时间相关值。
8 PLANNING ALGORITHM
我们的规划器被实现为模型预测控制器(Tassa et al., 2012):在每个时间步骤上,我们从系统的真实状态开始运行轨迹优化的单个迭代(使用iLQG, (Todorov&Li, 2005))。每条轨迹优化规划在250ms至600ms之间的时间范围内进行规划,并且随着世界仿真的发展,这种规划范围将逐渐消失,就像模型预测控制一样。
iLQG迭代从先前策略的初始rollout开始,该策略决定了名义轨迹。我们使用重复的模拟动态样本来估计动态在轨迹的每个步骤周围的线性扩展,以及成本函数的二次扩展。我们使用这个局部线性二次模型序列来沿名义轨迹在时间上向后积分价值函数。这种反向传播导致对动作序列的推定修改,这将降低总成本。我们通过整合动态前向(前向传播),在动作序列的空间中对该方向执行无导数线搜索,并选择最优轨迹。我们存储此动作序列,以热启动下一个iLQG迭代,并在仿真器中执行第一个动作。这将导致一个新状态,该状态将在轨迹优化的下一次迭代中用作初始状态。
9 ENVIRONMENT DETAILS
9.1 TORCS ENVIRONMENT
对于Torcs环境,我们使用了奖励函数,该函数在每一步中为沿轨道方向投影的汽车速度提供正奖励,对于碰撞的惩罚为-1。如果在500帧后没有沿着轨道前进,则回合将终止。
9.2 MUJOCO ENVIRONMENTS
对于物理控制任务,我们使用了奖励函数,可在每个步骤提供反馈。在所有任务中,奖励都包含很小的动作成本。对于具有静态目标状态的所有任务(例如钟摆摆动和到达)我们会根据到目标状态的距离提供平滑变化的奖励,在某些情况下,如果目标状态的半径较小,则会提供额外的正奖励。
对于抓握和操纵任务,我们使用了奖励,该奖励的术语鼓励向有效载荷的方向运动,第二成分鼓励将有效载荷向目标的方向运动。在运动任务中,我们奖励前进动作并惩罚严峻的冲击,以鼓励平稳步态而不是跳跃(Schulman et al., 2015b)。此外,对于跌倒,我们使用了负奖励和提前终止,而跌倒是由高度和躯干角度的简单阈值确定的(对于walker2d情况)。
表2列出了问题的范围,以下是所有物理环境的摘要。




