摘要:郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

4th Conference on Robot Learning (CoRL 2020), Cambridge MA, USA.
Abstract
移动机器人的节能控制已变得至关重要,因为它们在现实世界中的应用越来越复杂,涉及到高维观察/动作空间,而这些无法用有限的主板资源抵消。一种新兴的非冯 · 诺伊曼智能模型,其中在神经形态处理器上执行SNN,现在被认为是低维控制任务中最新实时机器人控制器的一个节能且鲁棒的替代。现在,这种新的计算范例面临的挑战是扩展规模,使其能够跟上实际应用。为此,SNN需要克服其训练的固有局限性,即其脉冲神经元表征信息的能力有限以及缺乏有效的学习算法。在此,我们提出一个群体编码的脉冲actor网络(PopSAN),该网络与使用深度强化学习(DRL)的深度critic网络一起进行了训练。遍及大脑网络的群体编码方案极大地增强网络的表征能力,并且混合学习将深度网络的训练优势与脉冲网络的节能推断相结合。为了证明我们的方法可用于通用的基于脉冲的RL,我们展示了其与基于策略梯度的DRL方法的广泛集成,包括同策和异策DRL算法。我们在英特尔的Loihi神经形态芯片上部署训练后的PopSAN,并针对主流DRL算法对我们的方法进行基准测试,以实现连续控制。为了在所有方法之间进行公平的比较,我们在OpenAI gym任务中对它们进行验证。与在Jetson TX2上的深度actor网络相比,我们在Loihi上运行的PopSAN每次推断的能耗少140倍,并且达到相当的性能水平。我们的结果证明了神经形态控制器的整体效率,并提出了在能效和鲁棒性都很重要的情况下,混合RL方法可以替代深度学习。
Keywords: Spiking neural networks, Deep reinforcement learning, Energy-efficient continuous control
1 Introduction
具有连续高维观察和动作空间的移动机器人正越来越多地被部署来解决复杂的实际任务。鉴于其有限的主板能量资源,迫切需要设计节能解决方案来对这些自主机器人进行连续控制。基于策略梯度的深度强化学习(DRL)方法已经成功地学习了针对复杂任务的最优控制策略[1, 2]。然而,它们的最优性是以高能耗为代价的,这使其不适用于多种应用[3]。
通过在神经形态处理器上部署SNN,可以提供深度网络的节能替代方案。在这种新兴的神经形态计算范例中,内存和计算紧密集成,神经元执行基于事件的异步计算[4]。越来越多的研究表明,SNN可作为解决许多实际机器人问题的低能耗解决方案[5, 6, 7]。对于机器人控制,SNN方法通常基于奖励调节的局部学习规则[8, 9],这些规则在低维任务中表现良好,但通常在复杂问题中失败,而在缺少全局损失函数的情况下优化变得困难[10]。最近,[11]提出了一种基于策略梯度的算法来训练用于学习随机策略的SNN。但是,该算法在离散动作空间上运行,在高维连续控制问题上的使用非常有限。
为了解决SNN在解决高维连续控制问题方面的局限性,一种方法是将SNN的能效与DRL的最优性相结合。为此,一种流行的SNN构造方法是使用权重和阈值平衡将训练后的深度神经网络(DNN)直接转换为SNN [12]。这种方法的主要问题在于,它通常会导致脉冲网络的性能低于相应的DNN,并且还需要大量的推断时间,从而大大增加了能源成本[13]。为了克服这个问题,最近的工作提出了一种混合学习算法,其中使用DRL对具有发放率编码输入的SNN进行训练,以学习针对静态环境中移动机器人的无地图导航的最优控制策略[14]。然而,这种方法在复杂高维任务中受挫,其中控制策略的最优性在很大程度上取决于具有有限表征能力的单个脉冲神经元的编码精度[15]。当使用较小的推断时间步骤以提高能效时,此解决方案的实用性甚至变得更低,因为随着神经元使用其发放率对数据进行编码,这会进一步降低神经元的表征能力。
有趣的是,最近抽象出大脑的拓扑及其计算原理产生了SNN的设计,这些SNN表现出类似人的行为[16]并提高了性能[17]。大脑中与有效计算相关的一个关键属性是使用神经元群体来代表从感觉刺激到输出信号的信息,其中群体中的每个神经元都具有捕获一部分编码信号的感受野[18]。有关群体编码方案的初步研究表明,它能够更好地代表刺激[19],这导致了最近在训练复杂高维监督学习任务的SNN方面取得的成功[20, 21]。群体编码的有效性证明为开发有效的群体编码SNN开辟了前景,这些SNN可以学习高维连续控制任务的最优解决方案。
在本文中,我们提出了一种群体编码脉冲actor网络(PopSAN),该网络使用DRL算法进行训练,以学习针对连续控制问题的节能解决方案1。我们的PopSAN的核心在于,它能够利用可学习的感受野对单个神经元群体中观察空间和动作空间的各个维度进行编码,从而有效地提高了网络的表征能力。由于不同的控制任务需要专门的DRL解决方案[22],因此我们将PopSAN与同策和异策DRL算法集成在一起,尤其是DDPG [23],TD3 [24],SAC [25]和PPO [26],从而证明其适用于各种基于策略梯度的DRL算法。我们将训练好的PopSAN部署在英特尔的Loihi神经形态处理器上,并评估了我们在具有丰富且不稳定动态的OpenAI gym任务中使用的方法,该方法用于对连续控制算法进行基准测试。我们将其方法获得的奖励和能耗与主流DRL算法进行了比较。与Jetson TX2上的深度actor网络相比,我们在Loihi上运行的PopSAN每次推断的能耗减少了140倍,同时还实现了相同水平的性能。这些结果将DRL算法引入了脉冲域,将它们缩放为神经形态解决方案,以增强在能效方面至关重要的学习任务。
1 代码位于https://github.com/combra-lab/pop-spiking-deep-rl
2 Methods
2.1 Population-coded Spiking Actor Network (PopSAN) embedded into DRL algorithms
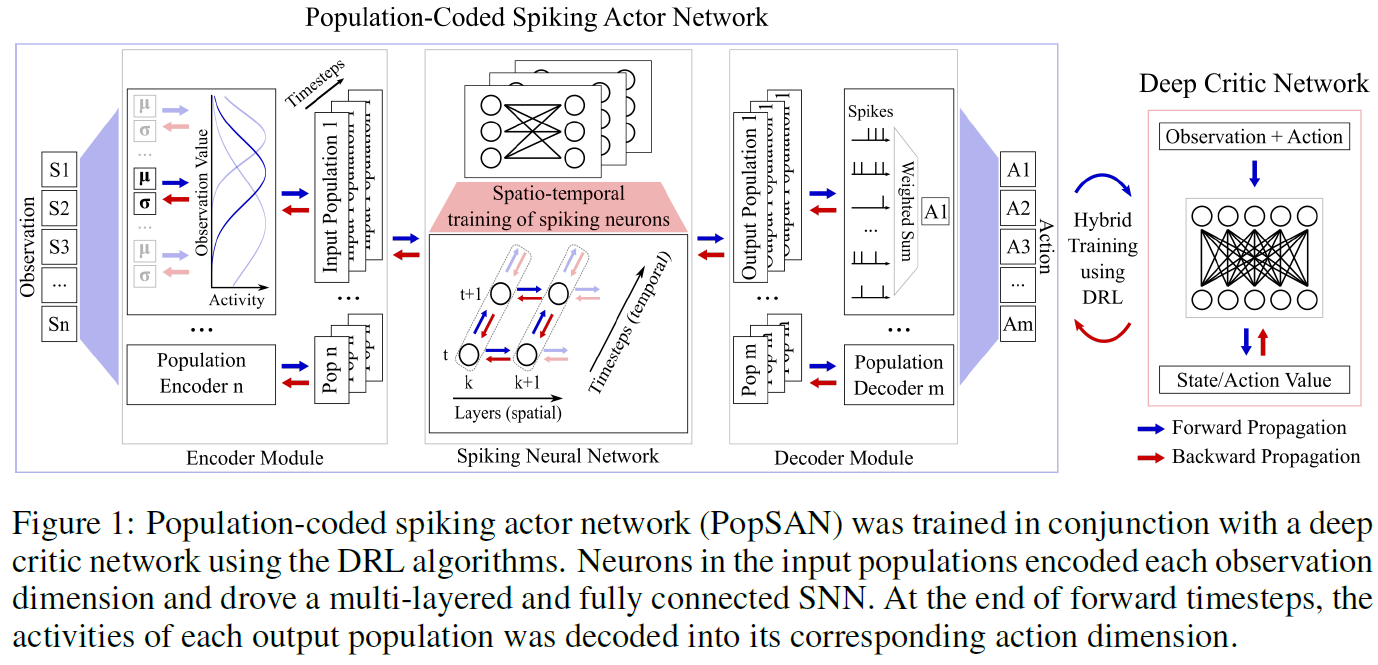
我们提出了一种群体编码的脉冲actor网络(PopSAN),该网络与使用DRL算法的深度critic网络一起训练。在训练期间,根据所选的DRL方法(图S1),PopSAN为给定的观察值s生成一个动作a ∈ RN,深度critic网络预测相关的状态-价值V(s)或动作-价值Q(s, a),进而优化PopSAN。PopSAN中的编码器模块将观察的每个维度编码为单个神经元群体活动。在前向传播过程中,输入群体驱动多层全连接SNN以产生输出群体活动,然后在每T个时间步骤结束时将其解码为相应的动作维度(算法1)。
为了构建SNN,我们使用了脉冲神经元的基于电流的LIF模型。LIF神经元的动态受算法2中所述的两步模型控制:i)将突触前脉冲o整合到电流c中; ii)将电流c积分到膜电压v中;dc和dv是电流和电压衰减因子。随后,如果神经元膜电位超过阈值,则发出脉冲信号。我们使用了硬重置模型,其中膜电位在脉冲发放时会重置为静息电位。假设传播延迟为零,则在相同的推断时间步骤将所得的脉冲传输到突触后神经元。
我们的PopSAN在功能上等效于深度actor网络,并且可以与任何基于actor-critic的DRL算法集成。具体来说,我们将PopSAN与同策和异策DRL算法(即DDPG [23], TD3 [24], SAC [25]和PPO [26])集成在一起,如下所示:对于DDPG和TD3,我们训练PopSAN来预测动作(训练后的critic网络为其生成最大动作-价值)。对于SAC,我们训练PopSAN以预测随机动作分布的均值,并训练一个深度网络来预测其标准差。这是通过最小化从预测分布中采样动作的概率与训练后critic网络生成的预测动作-价值之间的距离来实现的。对于PPO,PopSAN经过训练,以通过优化截断替代损失来预测动作分布的均值。

2.2 Population encoding and decoding in PopSAN
我们将观察和动作空间的每个维度编码为脉冲神经元的各个输入和输出群体的活动。编码器模块将连续观测转换为输入群体中的脉冲,而解码器模块将输出群体活动解码为实值动作。
对于N维观测的第 i 维si,i ∈ {1, ... , N},我们创建了一个神经元群体Ei对其进行编码。为简化符号,将 i 删除,E中的神经元具有高斯感受野(μ, σ)。将μ用s的空间中的均匀分布进行初始化,并将σ预置为足够大以确保在s的整个空间中的非零群体活动。
编码器模块分两个阶段计算群体E的活动:首先将观察值转换为群体中每个神经元的刺激强度AE:
![]()
其次,使用计算出的AE来生成E中神经元的脉冲。有两种可能的方法:i)概率编码,其中在每个时间步骤上以AE定义的概率生成所有神经元的脉冲;ii)确定性编码,其中E中的神经元被仿真为单步软重置IF神经元,而AE则充当神经元的突触前输入。神经元动态受以下公式控制:
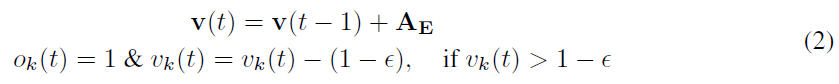
其中k表示E中神经元的索引,并且ε是一个小常数。对于两种类型的编码器,μ和σ都是任务特定的可训练参数。在我们的实验中,我们将两种类型的编码器用于第二阶段。
SNN的输出层由神经元群体组成,其中群体Di代表M维动作的维 i,ai,i ∈ {1, ... , M}。为了简化符号,将 i 删除,解码器模块分两个阶段将输出群体D的活动解码为相应的实值动作:首先,在每T个时间步骤之后,将D中每个神经元的脉冲相加以获得T上的发放率fr。其次,将动作a作为计算出的fr的加权和返回(算法1)。输出群体的感受野是由它们的连接权重形成的,这是在训练中学习的。
PS:
- Encoder:observation_size --> (observation_size * input_population_size) * T
- SNN:输入群体的脉冲分T个时间步骤输入SNN,(observation_size * input_population_size) * T --> (action_size * output_population_size) * T
- Decoder:(action_size * output_population_size) * T --> action_size * output_population_size (by fire rate) --> action_size (by weight and bias)
2.3 PopSAN training
我们使用梯度下降来更新PopSAN参数,其中确切的损失函数取决于所选的DRL算法,如第2.1节所述。损失相对于计算出的动作的梯度![]() 用于训练PopSAN的参数。
用于训练PopSAN的参数。
每个输出群体的参数 i,i ∈ 1, ... , M分别更新如下:
![]()
SNN参数使用[14]中引入的扩展时空反向传播进行更新。我们使用[27]中定义的矩形函数z(v)来近似脉冲的梯度。通过收集从所有时间步骤反向传播的梯度来计算每层k中损失相对于SNN参数的梯度:
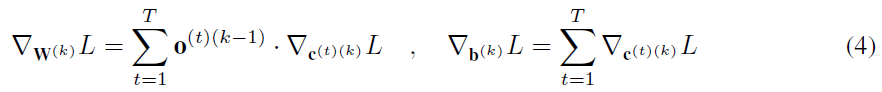
最后,我们为每个输入群体 i,i ∈ 1, ... , N独立更新参数,具体如下:
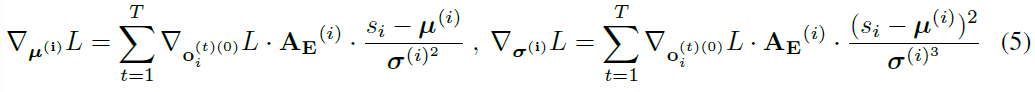
每T个时间步骤,我们更新所有参数。为了对训练过程中的梯度流进行逐步分析,我们将读者引向补充材料的第1节(PS:式(6)难以理解)。
2.4 Energy-efficient continuous control with Intel's Loihi neuromorphic chip
我们在英特尔的Loihi神经形态芯片上部署了训练后的PopSAN(图S2)。为此,我们引入了一个交互框架,该框架使Loihi能够实时控制OpenAI gym中的智能体。为了减少通信开销,在托管任务环境的计算机上执行编码的第一阶段(AE的计算),并在嵌入Loihi的低频x86芯片上执行第二阶段(脉冲生成)。同样,解码的第一阶段(fr的计算)在嵌入式芯片上执行,第二阶段(动作计算)在主机上执行。
然后,我们使用逐层重缩放技术将训练后的具有全精度权重的PopSAN映射到低精度Loihi芯片上[14]。最后,我们迫使Loihi上SNN中的每一层在其上一层开始运行的一个时间步骤后开始运行。这样做是因为Loihi上的突触后神经元在其操作的下一个时间步骤中接收到突触前脉冲,而不是在同一时间步骤中接收到它们的GPU。
3 Experiments and Results
我们的实验目标如下:i)通过根据相应的深度actor网络对我们方法的性能进行基准测试,论证PopSAN与同策和异策DRL算法的集成;ii)通过与最新的SNN方法进行比较并检验学习在神经元群体中的作用,证明需要进行群体编码;iii)展示PopSAN在Loihi上部署时在执行节能且实时连续控制方面的优势。我们在具有丰富且不稳定动态的OpenAI gym [28]任务上评估了我们的方法,这些任务通常用于对连续控制算法进行基准测试。为了限制初始化的效果,我们为每种算法训练了10个模型,分别对应于10个随机种子。每个模型都经过100万步的训练,并通过使用actor输出的确定性策略对其进行测试,从而对每1万步进行评估。为了补偿任务中随机性的影响,我们为每次评估计算了10个回合的平均奖励,其中每个回合最多可以持续1000个执行步骤。
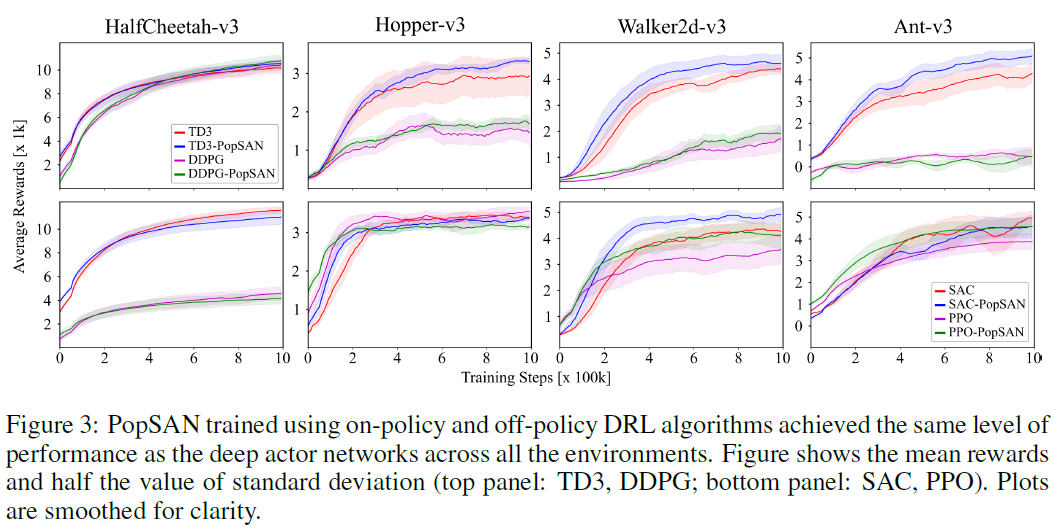
3.1 Benchmarking PopSAN against mainstream DRL algorithms
我们将使用同策和异策DRL算法训练的PopSAN的性能与相应的深度actor网络进行比较。我们的方法在所有DRL算法的所有任务中都达到了与深度actor网络相同的性能水平(图3),表明这两种方法在功能上是等效的。可以在补充材料的第2节中找到用于训练的超参数。
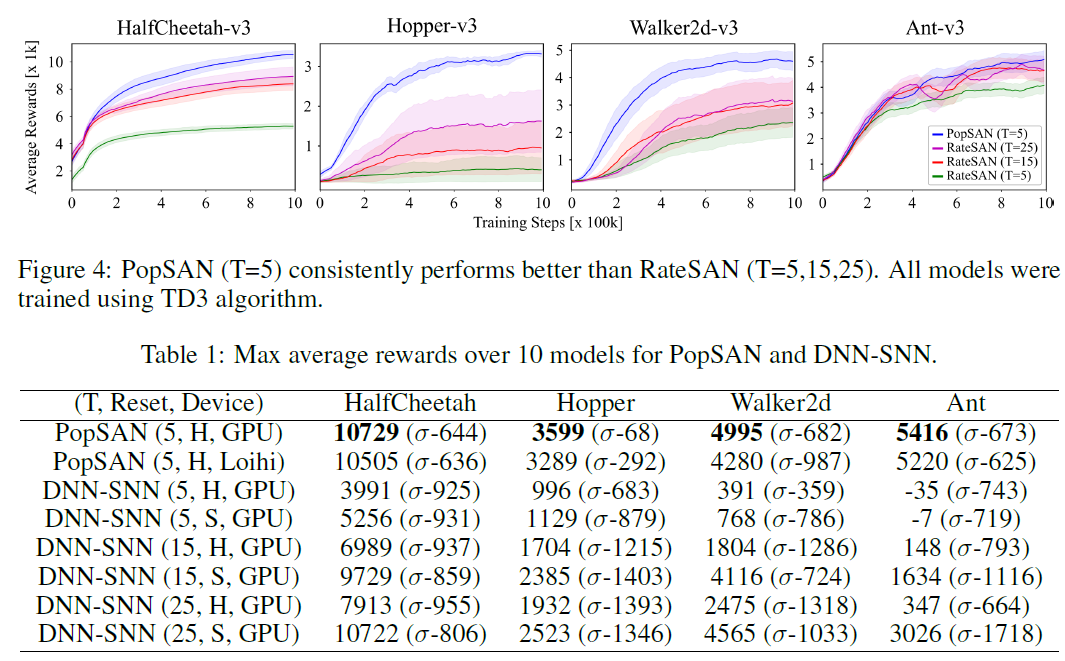
3.2 Benchmarking PopSAN against other SNN design approaches
我们将我们的方法与以下两个最近提出的将SNN与DRL集成的方法进行比较:i)DNN-to-SNN转换方法(DNN-SNN),其中使用DRL算法训练一个深度actor网络,并使用权重缩放将其转换为SNN [12]。在转换后的SNN中,可以将LIF神经元的脉冲后膜电位设置为静息电位(硬重置;H)或一个保留有关先前脉冲的信息的正电位(软复位;S),这在最近的研究[29]中表现出更好的性能。有关实现的详细信息,我们将读者引向补充材料的第3节。ii)发放率编码输入的SAN (RateSAN),它使用单个神经元表征来编码输入和输出,并使用混合学习算法[14]进行训练。这里报告的实验是使用TD3算法进行的。
即使使用高出5倍的T值进行训练,这两种SNN方法也无法达到我们方法的性能(图4; 表1)。这可能是因为两种SNN方法都具有有限的表征能力。虽然DNN-SNN方法在转换过程中会损失精度,但RateSAN方法在单个神经元的表征能力方面存在固有的局限性。Hopper任务的性能大幅下降(动态高度不稳定)进一步证明了这一点。
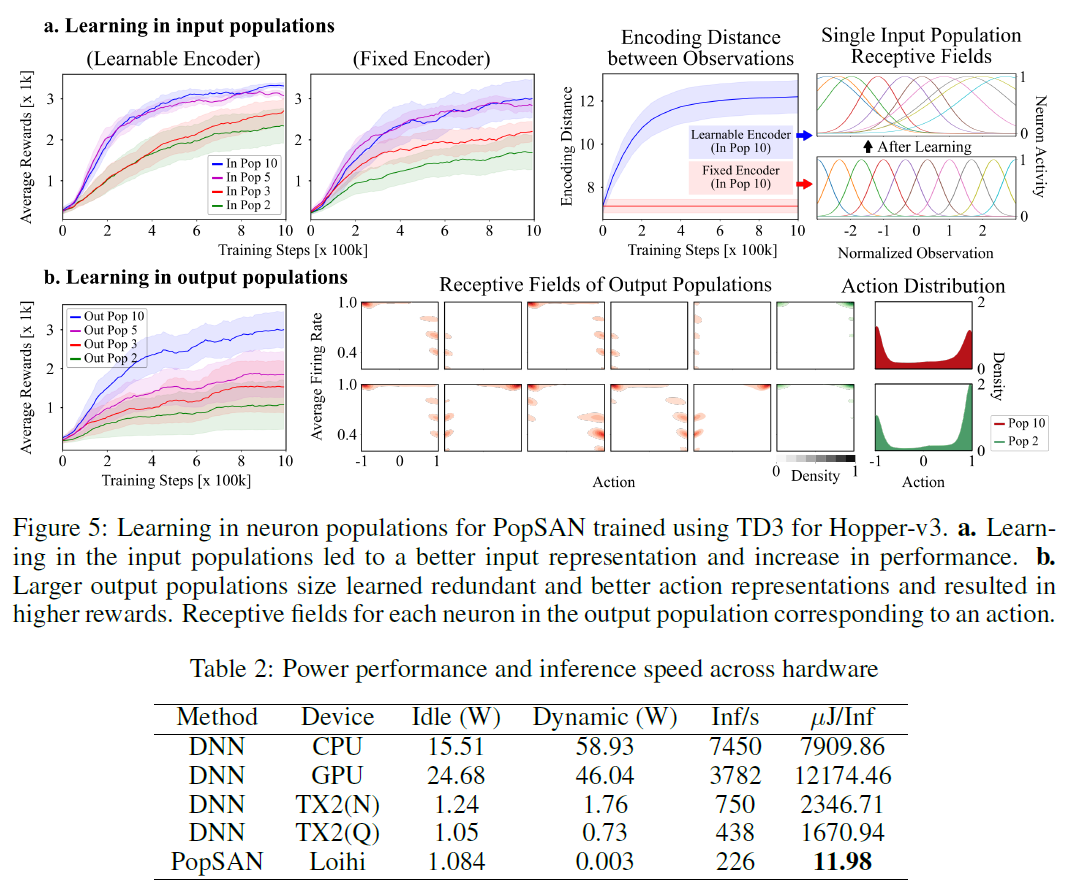
3.3 Learning in neuron populations
为了进一步证明群体编码的必要性,我们评估了输入和输出神经元群体数量对使用TD3训练的PopSAN的性能的影响,并研究了学习如何影响输入和输出神经元群体的表征能力。
首先,我们在每个观察维度上以不同的输入群体数量训练PopSAN:2, 3, 5, 10,同时将输出群体数量固定为10。图5a显示,输入群体数量的减少会损害PopSAN的性能。为了研究编码器中学习的效果,我们使用固定编码器对PopSAN进行训练,其中在训练过程中编码器参数(μ, σ)保持不变。对于所有输入群体数量,可学习的编码器的性能优于固定编码器(图5a)。可学习编码器具有出色性能的可能原因是它能够更好地分离编码中的不同观察结果。为了证明这一假设的正确性,我们针对固定和可学习的编码器计算了不同观测值的脉冲编码之间的平均L2距离。可学习的编码器导致编码增加了不同观察值之间的距离(图5a),从而表明它学到了更好的输入表征。
接下来,我们将每个动作维度的输出群体数量分别设为2, 3, 5, 10来训练PopSAN,同时将输入群体数量固定为10。性能随着输出群体数量的增加而提高(图5b)。为了检查PopSAN学到的动作表征,我们通过使用核密度估计来估计神经元活动的联合概率密度和预测的动作价值,从而计算输出群体神经元的感受野。图5b显示,群体数量较大的PopSAN学到了冗余的动作表征,并且可以覆盖更大范围的动作价值。这表明具有大量输出群体的PopSAN可以学到更好的动作表征。
3.4 Evaluating continuous control on Loihi
为了验证PopSAN在执行节能且实时连续控制方面的适用性,我们将其部署在Loihi上。与在全精度GPU上使用PopSAN相比,我们在Loihi上所采用的方法在获得的奖励方面表现出较高的性能(表1),仅略有减少。然后,我们使用 i)CPU (E5-1600),GPU (Tesla K40),嵌入式AI芯片(Jetson TX2-节能(Q)和高性能(N)模式))上的深度actor网络,以及ii)Loihi (Nahuku 8)上的PopSAN,计算HalfCheetah-v3的连续控制的推断速度和能耗。我们将每次推断的能源成本计算为动态功率与每秒执行的推断次数之比。我们在Loihi上使用的PopSAN的能效比DNN-Jetson TX2的低功耗处理器上的深度actor网络高140倍(表2),并且推断速度高,可以实现实时控制。
4 Discussion and Conclusion
在本文中,我们介绍了群体编码的SNN (PopSAN),其性能与深度网络相同,但能源效率却高出两个数量级。当我们将PopSAN与同策和异策的DRL方法集成在一起时,性能上的相似性是一致的。这证明了其适用于各种基于策略梯度的DRL算法,突出了其在解决包括连续控制在内的多项RL任务中的应用。
群体编码方案增强了网络的表征能力,并导致对观察和动作的更好编码。这使PopSAN与深度网络一起训练,能够以更少的推断时间有效地学习复杂高维连续控制任务。尽管大多数有关SNN的现有工作主要集中于网络设计和训练[20, 27],但我们的工作表明,使用正确的归纳先验对网络输入和输出进行适当的可学习编码可以导致性能的大幅提高。
在Loihi上运行的PopSAN在连续控制任务上的能效比在嵌入式省电AI芯片TX2上运行的深度actor网络高140倍。在主板资源有限的现实世界中的移动机器人应用(如救灾和行星探索)中,这一结果变得尤为重要。这样的应用通常依赖于多模态感测以获得鲁棒性[30],并需要高维动作来提高灵活性[1]。DRL方法通过使用大型网络(如深度CNN)来克服输入和输出的高维问题[2]。但是,使用这种大型网络会大大增加控制的能源成本[3]。另一方面,对于这种应用,我们提出的方法可能会大大降低能源成本,同时通过采用基于事件的传感器[31]和忆阻性神经形态处理器[32],有望进一步提高能源效率,这比它们的数字对应要高效得多。
我们在此表明,PopSAN可以成功地与同策和异策的DRL算法集成在一起,从而突显了它在需要特殊DRL解决方案的各种任务中的适用性[22]。这在现实世界的RL应用中尤为重要,在该应用中,多种因素(例如算法的样本效率,环境的随机性,奖励函数的目标以及安全性约束)决定哪种DRL算法最适合给定任务[33]。总体而言,当能源效率和鲁棒性都很重要时,我们提出的基于脉冲的解决方案可以成为深度学习的强大替代方案,用于现实世界中的RL应用。
Supplemental Materials: Deep Reinforcement Learning with Population-Coded Spiking Neural Network for Continuous Control
1 PopSAN training using backpropagation


2 Hyperparameters for training regular DRL and PopSAN
在此,我们描述了深度actor网络和PopSAN的实现细节和超参数配置。我们的实验基于OpenAI Spinning Up1,OpenAI Baselines2和Stable Baselines3的开源代码库。除非明确说明,否则PopSAN训练使用与深度actor网络相同的超参数。所有方法的超参数配置如下:



1 https://github.com/openai/spinningup
2 https://github.com/openai/baselines
3 https://github.com/hill-a/stable-baselines
3 DNN to SNN conversion method
DNN-to-SNN的转换(DNN-SNN)方法使用权重缩放和网格搜索将训练后的DNN转换为SNN,如下所示:首先,使用选定的DRL算法训练深度actor网络。为了克服转换后的SNN的有限表征并进行公平比较,它使用的DNN与PopSAN具有相同的结构。其次,将训练后的DNN的参数直接以适当的缩放因子用于SNN。由于脉冲神经元的发放率限制在[0, 1]范围内,因此每个DNN层的最大激活都需要重新缩放为1,以使SNN能够表示DNN激活的整个范围。为此,DNN-SNN方法将每一层的偏差缩放因子设置为等于训练期间计算出的当前层的最大输出,而权重缩放因子则设置为上一层和当前层的最大输出的比率。最后,为了提高转换后的SNN的性能,网络权重和偏差在随机采样的回合上进一步按0.1-1.0内的因子(使用网格搜索确定)进行了重新缩放。我们选择在10个回合的评估中平均奖励最高的因子。
4 Power measurement details
对于测试期间记录的观察结果,我们测量了平均功耗和推断速度。功耗和推断速度是通过对10次运行的测量值取均值而得出的,每次运行包括在测试过程中记录的超过10万次观察的推断。对于功率测量,我们使用了软件工具来探测每个设备的板载传感器:用于CPU的powerstat,用于GPU的nvidia-smi,用于TX2的sysfs和用于Loihi的能量探测器。为了准确测量Loihi上PopSAN的功耗,我们同时在Nahuku芯片组上部署了8个网络。然后,通过平均部署网络的数量来计算功耗。
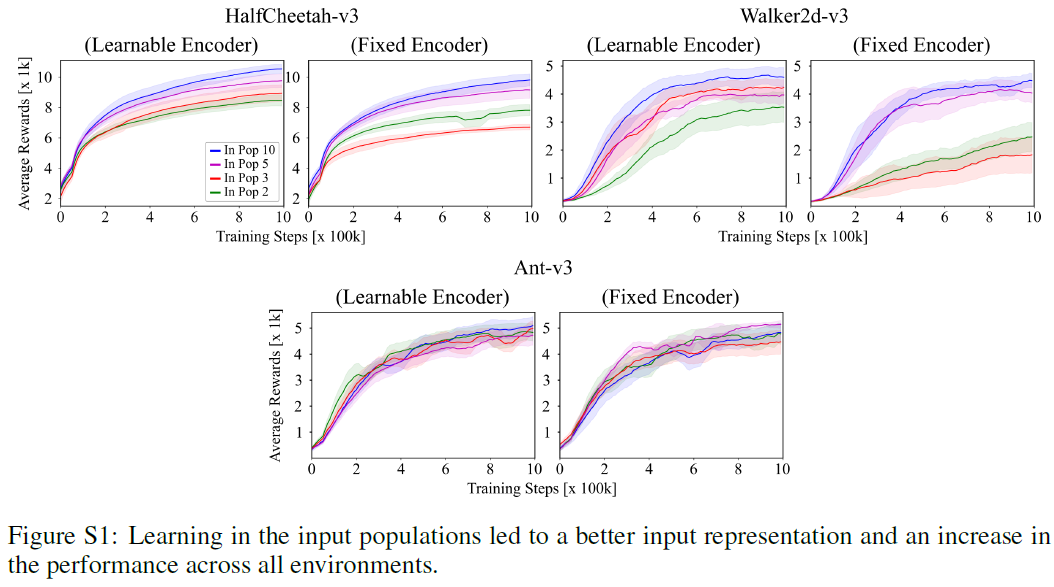
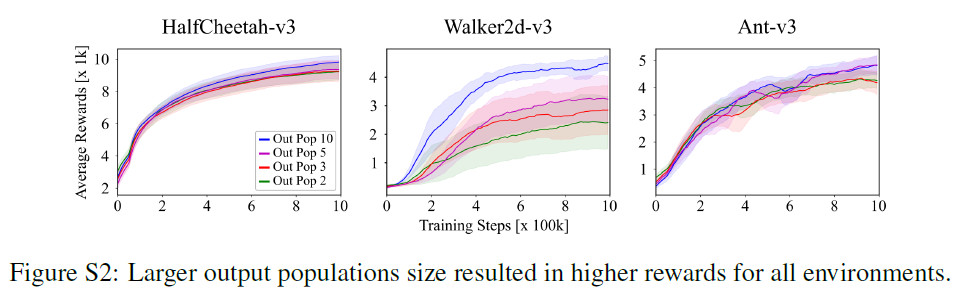
5 Additional ablation studies for neuron populations
图S1和S2显示了使用不同的输入和输出群体数量训练的PopSAN的结果:对于正文中未涵盖的所有其他环境,分别为2, 3, 5, 10。