摘要:郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

arXiv:2003.01157v2 [cs.NE] 31 Jul 2020
Abstract
节能无地图导航对移动机器人至关重要,因为它们会在主板资源有限的情况下探索未知环境。尽管最近的深度强化学习(DRL)方法已成功地应用于导航,但是其高能耗限制了它们在多种机器人应用中的使用。在这里,我们提出了一种神经形态方法,将SNN的能效与DRL的最优性相结合,并在无地图导航的学习控制策略中对其进行基准测试。我们的混合框架是脉冲确定性策略梯度(SDDPG),由脉冲actor网络(SAN)和深度critic网络组成,其中两个网络使用梯度下降共同训练。共同学习可实现两个网络之间的协同信息交换,从而使它们可以通过共享表征学习来克服彼此的局限性。为了评估我们的方法,我们在英特尔的Loihi神经形态处理器上部署训练后的SAN。当在仿真和真实的复杂环境中进行验证时,我们的Loihi方法每次推断的能耗是Jetson TX2上的DDPG的75倍,并且导航到目标的成功率更高,范围从1%到4.2%,并且取决于前向传播时间步长。这些结果加强了我们正在进行的努力,以设计灵感来自大脑的算法来控制具有神经形态硬件的自主机器人。

I. INTRODUCTION
(省略)
在本文中,我们提出了Spiking DDPG (SDDPG),这是一种节能的神经形态方法,它使用SNN/DNN混合框架学习最优策略1,并在现实环境中的无地图机器人导航中对我们的方法进行了基准测试(图1)。像其深度网络对应一样,SDDPG具有独立的网络来表示策略和动作-价值:脉冲actor网络(SAN)(用于从机器人状态推断动作)和深度critic网络(用于评估actor)。使用梯度下降联合训练了该结构中的两个网络。为了训练SAN,我们引入了STBP的扩展,它使我们能够在Intel Loihi上忠实地部署训练好的SAN。我们通过比较分析评估了我们的方法在仿真和现实复杂环境中相对于DDPG的性能和能效。与Jetson TX2上的DDPG相比,Loihi上的SDDPG每次推断的能耗减少了75倍,同时还成功实现了目标导航。
1 Code: https://github.com/combra-lab/spiking-ddpg-mapless-navigation
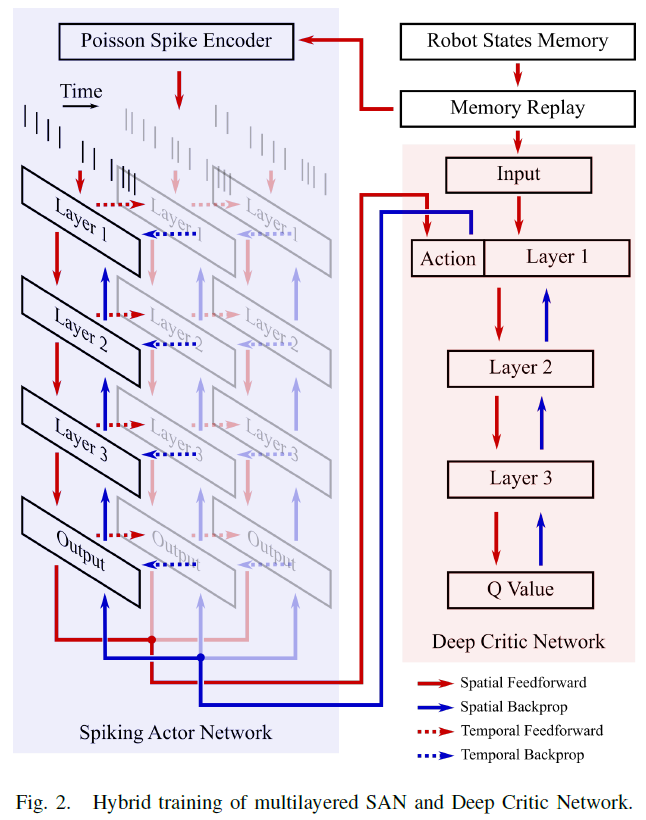
II. METHODS
A. Spiking Deep Deterministic Policy Gradient (SDDPG)
我们提出了SDDPG算法,以学习用于映射给定状态的机器人的最优控制策略s = {Gdis, Gdir, ν, ω, S}对机器人的动作a = {νL, νR},其中Gdis和Gdir是机器人到目标的相对距离和方向;ν和ω为机器人的线速度和角速度;S是从激光测距仪测得的距离;νL和νR是差分驱动移动机器人的左/右车轮速度。
混合框架由脉冲actor网络(SAN)和深度critic网络组成(图2)。在训练期间,SAN生成给定状态s的动作a,然后将其馈送到critic网络以预测关联的动作-价值Q(s, a)。对SAN进行训练,以预测将Q值最大化的动作。反过来,对critic网络进行训练,可以使动作-价值的TD误差最小,如[4]所述。为了更新动作-价值,我们使用了[5]中采用的奖励函数:
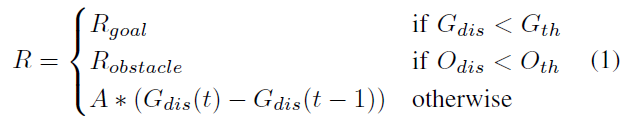
其中Rgoal和Robstacle分别是正/负奖励;Odis是到障碍物的距离;A是放大因子;Gth, Oth是阈值。奖励函数鼓励机器人在探索过程中朝目标移动,从而有助于训练。
为了进行推断,我们在Loihi上部署了训练后的SAN(请参阅II.D),以预测将机器人导航到目标的动作。在接下来的两节中,我们为推断和训练阶段提供数学形式。
B. Spiking Actor Network (SAN)
SAN的构建块是脉冲神经元的LIF模型。具体来说,我们分两个阶段在时间步骤 t 更新了第 i 个神经元的状态。首先,我们将输入脉冲整合到突触电流中,如下所示:
![]()
其中c是突触电流,dc是电流的衰减因子,wij是第 j 个突触前神经元的连接权重,oj是二值变量(0或1),指示第 j 个突触前神经元的脉冲事件。
其次,根据等式(3),我们将突触电流整合到神经元膜电压中。随后,如果膜电压超过阈值,则神经元发出脉冲信号。
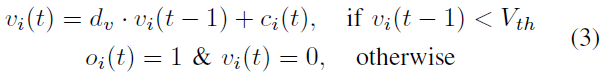
其中v是膜电压,dv是电压的衰减因子,Vth是发放阈值。
LIF神经元形成了一个全连接的多层SAN(图2)。该网络由离散的泊松脉冲驱动,该脉冲对连续状态变量进行编码。这是通过在每个时间步骤上生成一个脉冲来实现的,脉冲概率与当时状态变量的值成正比。经过T个时间步骤后,我们将输出层神经元重新缩放后的平均脉冲计数(动作)解码为机器人的左/右车轮速度(算法1)。

C. Direct Training of SAN with Back-propagation
我们扩展了STBP,以直接训练我们的SAN以学习最优策略。原始的STBP仅限于包含简化的LIF神经元的训练网络,这些神经元只有一个状态变量(电压)。在此,我们将其扩展为具有两个内部状态变量(电流和电压)的LIF神经元,这些变量在公式(2)和(3)中定义。这样做是为了使我们可以在Loihi上部署训练好的模型,该模型实现了这种两状态神经元模型。
由于定义脉冲的阈值函数是不可微的,因此STBP算法需要伪梯度函数来近似脉冲的梯度。我们选择矩形函数(在公式(4)中定义)作为我们的伪梯度函数,因为它在[17]中显示出最优的经验性能。

其中z是伪梯度,a1是梯度的放大器,a2是传递梯度的阈值窗口。
在SAN的前向传播结束时,将计算出的动作馈送到critic网络的第n层,后者依次生成预测的Q值。对SAN进行训练,以预测受过训练的critc网络生成最大Q值所采取的动作。为此,我们使用梯度下降对SAN进行了训练,以使公式(5)中定义的损失L最小。

critic网络第n层的梯度为:

其中an+1是critic网络第(n + 1)层在通过非线性激活函数(例如ReLU)之前的输出,而![]() 是critic网络第(n +1)层的权重。
是critic网络第(n +1)层的权重。
然后将此梯度反向传播到SAN。为了描述完整的梯度下降,我们将分析分为两种情况:i)最后的前向传播时间步骤t = T,以及ii)所有先前的时间步骤t < T。

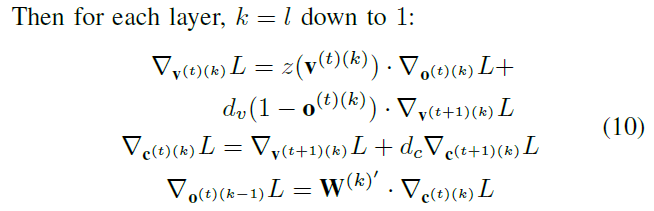
在这种情况下,与情况1相比,电压和电流的梯度具有额外项,反映了从未来时间步骤反向传播的时序梯度。
通过收集所有时间步骤的反向传播梯度(在以上两种情况下进行计算),我们可以计算出每一层k损失相对于网络参数的梯度![]() ,如下所示:
,如下所示:
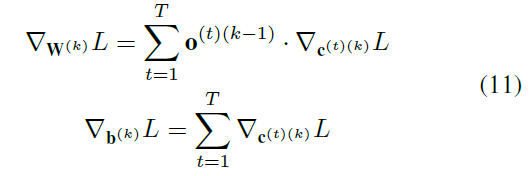
我们每T个时间步骤更新一次网络参数。

D. SAN Realization on Loihi Neuromorphic Processor
III. EXPERIMENTS AND RESULTS
A. Experimental Setup
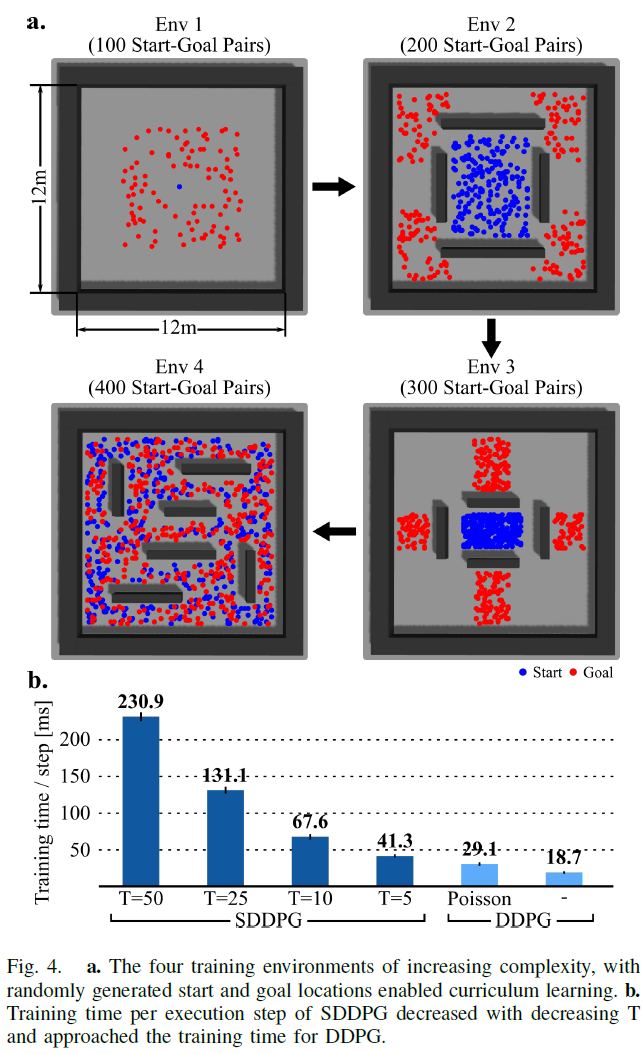
B. Training in Simulator

C. Baselines for comparison
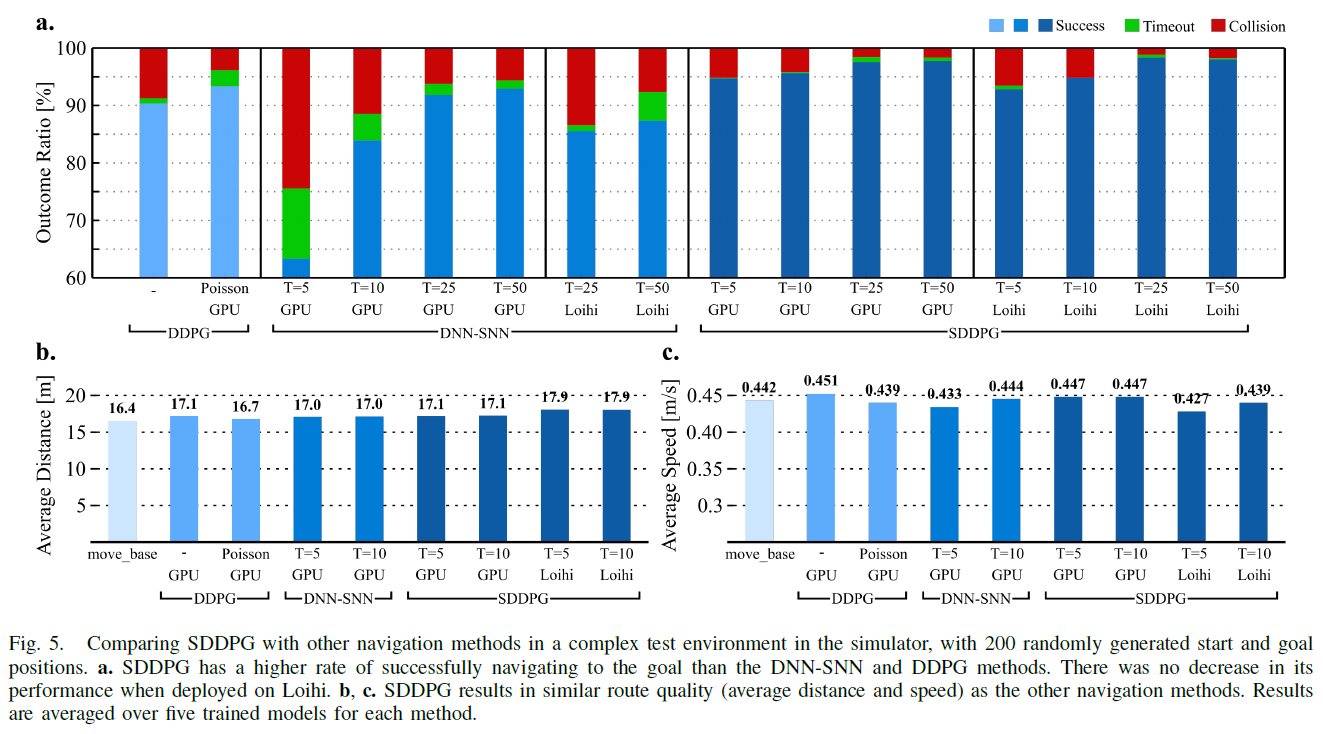
D. Evaluation in Simulator

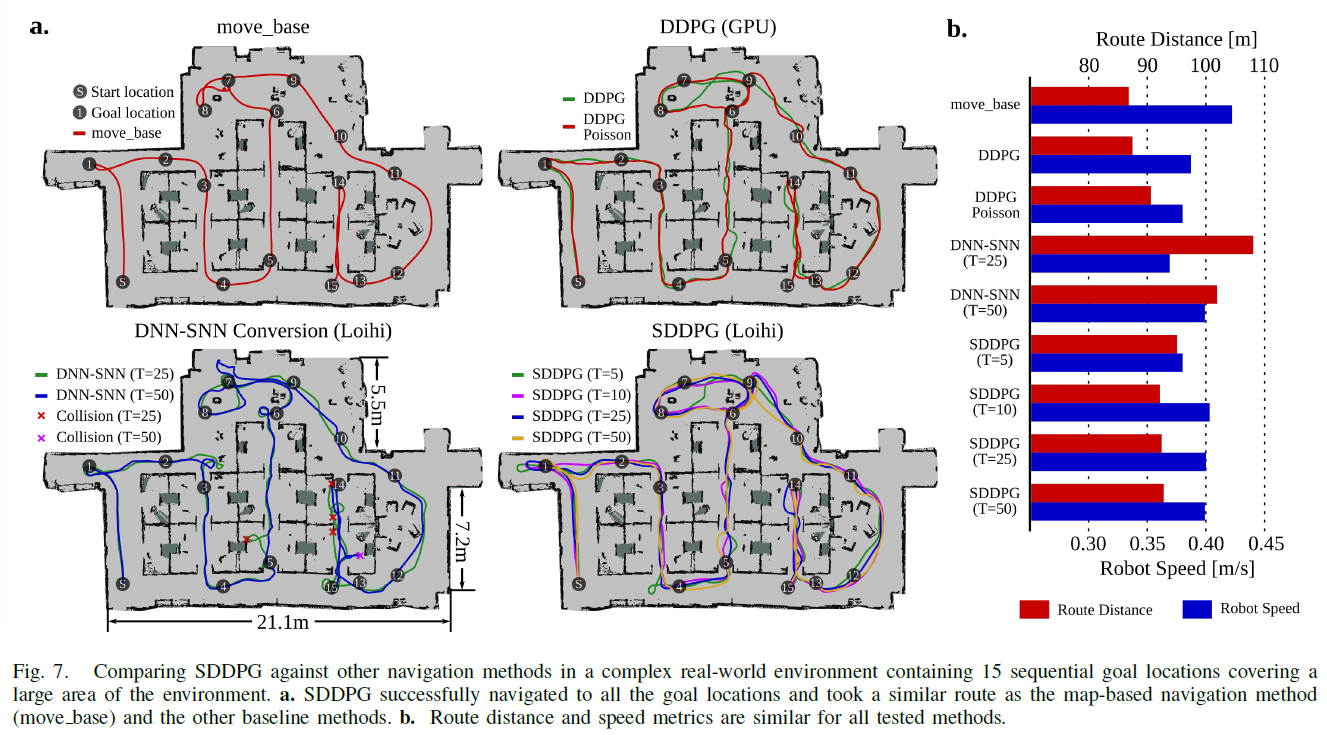
E. Evaluation in Real-world
F. Power Performance Measurement
IV. DISCUSSION AND CONCLUSION
在本文中,我们提出了一种神经形态框架,该框架将SNN的低功耗和高鲁棒性与DNN的表征学习能力相结合,并在无地图导航中进行基准测试。虽然最近在整合这两种架构上的努力集中于分别训练两个网络[16], [25],但我们在此提出了一种将它们相互结合训练的方法。我们的训练方法实现了两个网络之间的协同信息交换,从而使它们可以通过共享表征学习来克服彼此的局限性;当部署在神经形态处理器上时,这为无地图导航提供了一种最优且节能的解决方案。这样的努力可以补充目前允许进行联合推断的神经形态硬件,例如Tianjic芯片[25],并刺激用于节能联合训练的混合神经形态芯片的开发。
我们的方法比在DNN的低功耗边缘设备(TX2)上运行的DDPG的能效高75倍。这种卓越的性能不仅来自SNN提供的异步和基于事件的计算,还来自我们的方法针对较低的T值训练SNN的能力,而性能损失很小。但是,DNN-SNN转换方法不是这种情况,该方法需要5倍以上的时间步长和4.5倍的能量才能达到与SDDPG相同的性能水平(T = 5)。能效的提高可以使我们的方法能够有效地导航家庭,工业,医疗或救灾应用中车载资源有限的移动服务机器人。通过将我们的方法与低成本的无地图定位方法(例如基于主动信标的定位方法)相结合,并且利用模拟忆阻神经形态处理器,能效会比其数字对应高几个数量级,可以实现能源成本的进一步降低。尽管大多数SNN优势的演示都集中在能量收益上,但是却以降低性能为代价[9], [11], [12],但这也许是第一次,一种节能方法也能显示出更高的准确性,至少在经过测试的机器人导航任务中比当前技术水平要好。准确性的提高部分归因于我们的混合训练方法,该方法帮助克服了SNN在表示高精度值方面的局限性,从而带来了更好的优化。此外,SNN在时空域中固有地对其输入进行了带噪的表征,这也可能有助于逃避"不良"的局部最小值。这些出色的SDDPG结果表明,强化学习是一种训练范例,其中节能型SNN也可能实现其对计算鲁棒性和多功能性的承诺。
总体而言,这项工作支持了我们为开发实时节能型机器人导航解决方案所做的持续努力。我们的无地图解决方案可以补充当前基于地图的方法,以便在易于获取地图的应用中生成更可靠的控制策略。此外,我们的通用混合框架可用于解决各种任务,为全自动移动机器人铺平了道路。