郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Published in D. Zaharie, D. Petcu, V. Negru, T. Jebelean, G. Ciobanu, A. Cicortas¸ A. Abraham and M. Paprzycki (eds.), Proceedings of the Seventh International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC 2005), pp. 299–306. IEEE Computer Society, 2005.
Abstract
本文提出了一种新的用于脉冲神经网络的强化学习机制。该算法是针对随机IF神经元网络而推导的,但是它也可以应用于通用脉冲神经网络。通过依赖于突触前和突触后神经元发放的突触变化来实现学习,并通过全局强化信号进行调节。该算法的有效性已在一个生物学启发的实验中得到了验证,该实验模拟蠕虫来寻找食物。我们的模型恢复了一种在动物中实验观察到的神经可塑性形式,将一个符号的脉冲时序依赖性突触变化与由突触前脉冲确定的相反符号的非缔合性突触变化结合起来。该模型还预测,脉冲时序依赖的突触变化的时间常数等于神经元的膜时间常数,这与大脑中的实验观察结果一致。这项研究还导致发现了一种生物学合理的强化学习机制,该机制可以通过调节带有全局奖励信号的脉冲时序依赖可塑性(STDP)起作用。
1 Introduction
脉冲神经网络(Maas and Bishop, 1999; Gerstner and Kistler, 2002)被认为是第三代神经网络(Maas, 1997a)。结果表明,它们比上一代网络(具有McCullogh-Pitts神经元或具有连续的sigmoidal激活函数)的神经元具有更高的计算能力(Maas, 1997b)。但是,研究脉冲神经网络的主要兴趣是它们与生物神经网络的相似之处。这样可以在设计神经模型时从实验神经科学中汲取灵感,并利用从模型的仿真和理论分析中获得的知识更好地了解大脑的活动。
用于脉冲神经网络的强化学习算法尤其重要,尤其是在体现计算神经科学的情况下,其中由脉冲神经网络控制的智能体通过与环境交互进行学习。理想情况下,智能体应该通过无监督学习或强化学习来发展自己的内部环境表征,而不要进行监督学习,以最大程度地减少由人类程序员引起的偏差(Florian, 2003)。
现有的用于脉冲神经网络的强化学习算法通过将不规则脉冲的波动与奖励信号相关联来工作,该网络由发放泊松脉冲序列的神经元组成的网络(Xie and Seung, 2004)。该算法高度依赖于神经元的泊松特性,并且在使用常用的神经模型(例如IF神经元)时需要在神经元中注入噪声。因此很难与这些神经模型结合使用。同样,该学习模型假定神经元通过调节其发放率对输入进行瞬时响应。这部分地忽略了神经膜电位的记忆,而神经膜电位的记忆是脉冲神经模型的重要特征。可以用于脉冲神经网络的另一种强化学习算法是通过增强随机突触传递来实现的(Seung, 2003)。
在此,我们提出了一种新的强化学习算法用于脉冲神经网络。该算法是针对概率(随机)IF神经元网络的解析推导,并在概率和确定性神经元网络上进行了测试。我们提出的学习规则是突触局部的,假设强化信号扩散到网络中:突触的变化依赖于强化和突触前后神经元的活动。
在第2节中,我们首先介绍算法的推导。接下来我们将讨论该算法与其他类似算法的关系(第3节),以及它与神经科学的相关性(第4节)。在第5节中,我们描述了验证该方法学习能力的实验。最后一节是结论。
2 Derivation of the algorithm
2.1 Analytical derivation
我们提出的算法是作为OLPOMDP强化学习算法的应用(Baxter et al., 1999, 2001)而推导的,该算法是GPOMDP算法的在线变体(Bartlett and Baxter, 1999a; Baxter and Bartlett, 2001)。GPOMDP假定智能体与环境的交互是部分可观察的马尔可夫决策过程,并且智能体根据概率策略μ来选择动作,该概率策略μ取决于几个真实参数的向量θ。GPOMDP是通过最大化智能体所获得的奖励的长期均值进行分析得出的。已经获得了与OLPODMP收敛到局部最大值有关的结果(Bartlett and Baxter, 2000a; Marbach and Tsitsiklis, 1999, 2000)。
我们考虑一个在离散时间内演化的神经网络。在每个时间步骤 t 处,神经元 i 要么以概率σi(t)发放(fi(t) = 1),要么不以概率1 - σi(t)发放(fi(t) = 0)。神经元通过具有功效wij(t)的可塑突触连接,其中 i 是突触后神经元的索引。功效可以是正的或负的(分别对应于兴奋性突触和抑制性突触)。全局奖励信号r(t)被广播到所有突触。
通过将每个神经元 i 视为独立智能体,将神经元的发放/非发放概率作为相应智能体的策略μi,传入突触的权重wij作为向量θi来参数化智能体的策略,并如果将突触前神经元的发放状态fj表示为对智能体可用的环境的观察,我们可以将OLPODMP应用于神经网络。结果是以下可塑性规则更新了突触,从而优化了网络所获得奖励的长期均值:
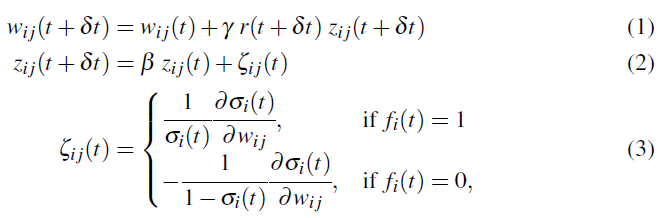
其中δt是一个时间步骤的持续时间,学习率γ是一个小的常数参数,z是资格迹,并且ζ是由上一个时间步骤中的活动导致的z的变化的符号。折扣因子β是一个参数,可以取0到1之间的值,也可以写成β = exp(-δt / τz),其中τz是z的指数衰减的时间常数。
到目前为止,我们还遵循了在(Bartlett and Baxter, 1999b, 2000b)中进行的推导。但是,与这些研究涉及无记忆的二值随机单元的网络不同,从现在开始,我们将在这里考虑随机LIF神经元的网络,这些网络在离散的时间内根据以下条件演化:
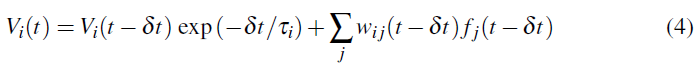
(省略)
2.2 Generalization to other neural models
3 Relationship and comparison to other reinforcement learning algorithms for spiking neural networks
4 Relevance to neuroscience: Reinforcement learning and spike-timing-dependent plasticity (STDP)
5 Experiments and results
5.1 Experimental design
5.2 Experiment 1: Training a network of probabilistic integrate-and-fire neurons
5.3 Experiment 2: Training a network of Izhikevich neurons
5.4 Experiment 3: Reinforcement learning through modulated STDP
5.5 Results
6 Conclusion