Python是个功能很强大,也很齐全的语言,这在我当初学的时候是不了解的。想想半年前学习python的初衷,无非是是因为ArcGIS提供了python脚本的编译环境,当我知道ArcToolbox里那些功能强大的工具,有一部分竟然就是用所谓python写出来的,自然也就想着去尝试,简化那些冗杂的工作,这也是我喜欢编程的一个原因。
不过说实话,python断断续续的学到现在,也没写出什么脚本工具,但怎么也说不能算没有一点收获:起码学会了一门语言呢。虽然离当初的目标有些偏离,但是学习本身,是没什么坏处的,因为你总会意外的收获到其他的东西。
Python是开源的,所以除了官方的库之外,有很多第三方的库,可以做很多事情,像科学计算,机器学习,搭建网站的框架,还有,当然了,就是爬虫,想想就很有意思。目前也是刚接触,numpy是跟着一本书学,爬虫的话,就是在网上找资料,参照着别人的案例。
今天写的第一个,就是参照虫师老师的一篇博客http://www.cnblogs.com/fnng/p/3576154.html。这个例子,说的是如何从一个网页中,将所有的图片下载到本地,并编号,在看代码之前完全是没有一点概念的,看完之后就感觉,整个过程并不复杂,python提供了功能相当强大的urllib库,代码也很简单。
|
# python读取网页的库 import urllib # 正则表达式有关模块 import re |
这里说一说正则表达式,正则表达式(Regular Expression)是很复杂的,不只有python有,像Java, C#都有,说白了就是编写一定的规则来匹配字符串,掌握基础的就已经够用,复杂的以后还得慢慢学,这里还是推荐廖雪峰老师的个人网站http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386832260566c26442c671fa489ebc6fe85badda25cd000,上手不困难
|
def getHTML(url): # 类似于文件的打开 page = urllib.urlopen(url) # 类似于文件的读取 html = page.read() return html |
考虑到之后的使用的方便,这里将这个方法进行了封装,写成一个函数,代码很简单,和文件的读取很类似。
这个其实是整个个爬虫过程最复杂的一部分。因为网站的内容相差很大,想要提取的信息也是不一样的,所以没有一个万能的正则表达式,得就事论事。
接下来就具体分析一个网页,html+css+Javascript接下来还得继续学习。
比如说这个网站http://tieba.baidu.com/p/4571038933?see_lz=1里面有很多图片,在Chrome里按住F12查看源代码,会发现,这里面所有的图片都链接到一个网址,并且格式如下:

我们所需要的,就是提取src=""里面的链接。
代码如下:
|
def getImag(html): # 这里是通过compile将字符串编译成一个正则对象 # re.S表示多行匹配,比较常用 pattern = re.compile('<img class="BDE_Image".*?"(.*?)"', re.S) # re.findall以列表形式返回匹配到的子串,也常见match(从头匹配),search(任意匹配) imags = re.findall(pattern, html) |
这个函数正则表达式部分已经写完,但只完成了一半,接下来就是根据提取到的链接,来下载文件并保存到本地
|
# t负责给文件编号 t = 1 for img in imags: # 使用urltrieve从链接中获取文件 urllib.urlretrieve(img, 'D:LearnCodepythonpachongphoto\%s.jpg' % t) t += 1 |
|
url = 'http://tieba.baidu.com/p/4571038933?see_lz=1' html = getHTML(url) getImag(html) |
就可以在文件夹中等着接收文件吧
的确是很有成就感。
在这个网站中,我发现了更为有趣的用法http://www.nowamagic.net/academy/detail/1302861
参阅帮助文档,可以发现urlretrieve有个回调函数

具体可以这样来用,写一个回调函数Reporthook()
|
def Reporthook(a, b, c): # a:已经下载的数据块,b:数据块的大小,远程文件的大小 per = 100 * a * b / c if per > 100: per = 100 print '%.2f%%' % per |
然后在urlretrieve()的里面增加一个名为Reporthook的参数即可
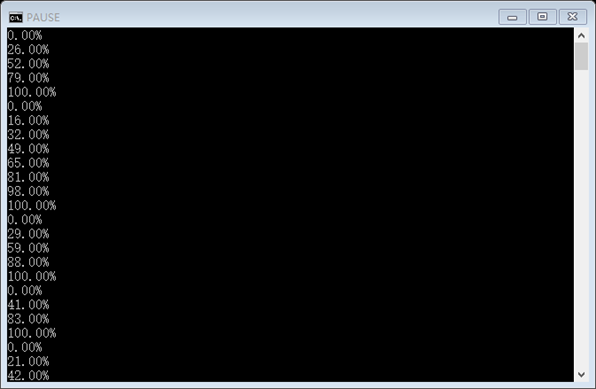
相当有意思!!!!!
总结:
1、关于爬虫,没有找到有关的书籍。但是,但是,网络上的资源其实是相当丰富的,尤其是很多技术博客,作者写的都相当的详细,参照着学,收获是很大的,以上我写的都是在网上找到的。见贤思齐焉,遇到不会的,就去学习好了。
2、python官方文档,讲的虽然不详细,但简明扼要,都是核心的东西,多看看,会发现很多的盲点,就像这个例子里的回调函数,很多人估计在学爬虫的时候都没有使用过。
3、爬虫会接触到很多网页前端的内容,接下里要想爬的更好,就得学html+css+javascript,甚至是分布式