最近开始做毕业设计了,很多想要学的东西都没有时间。前段时间学了点数据结构和算法,说实话,理解起来有些困难,而且偏于底层,离应用有些远,学着也很慢,但我知道,这些都是计算机科学里非常基础的,属于最为核心的知识,和具体的编程语言关系不大,更多的是算法的思想,以及解决问题的思路。《深入理解计算机系统》这本书也买了,但没时间看。Java和Android也都想学,可是精力毕竟有限,放在后面再说吧。
这是最近一段时间的状态!
下面回到正题。
首先,为什么想做这么个东西?这个就涉及到需求了。平常比较喜欢看电影,既然要看电影,自然要筛选出值得看的,最常用的,就是豆瓣电影,里面的分数,个人感觉比较可靠。但每次都要打开浏览器,再去搜索,还要找到豆瓣的页面,实在是觉得有些繁琐。在这样的需求的驱动下,加上自己确实已经拥有了解决问题的能力,自然就会想着去实现它。方式呢?自然是Python。
其他的语言接触的不多,就爬虫这个领域来讲,Python无疑是非常好的选择,它不仅天生自带urllin模块模拟访问,而且有很多第三方库,比如BeautifulSoup等,解析HTML变得异常简单。再说本来就是个小工具,对效率的要求没那么高,没有必要登堂入室,用更复杂的语言。
以前没有接触过GUI,也是边学边做。GUI库用的是wxPython,不是那种拖控件的形式,而是用代码一点点的写,包括position和size都要自己调试,网上的教程并不多,就只用一本书,《wxPython in action》,我是在这个网站上看的,http://www.kancloud.cn/wizardforcel/wxpy-in-action/197387。
其实我学了前几个部分,就把基础控件和事件驱动给看了,其他的,都是感觉用得着的时候再去查,所以理解的也并不是特别的系统。书感觉写的比较一般,个人不适合喜欢,已经打算转到pyQT了,当然,这是后话。
下面看看具体的代码。
遵循模块的思想,对整个程序在功能上进行了划分,分成三个部分:douban.py是整个程序的入口,也是负责窗体的部分,papapa.py负责爬取网站,解析需要的信息,image.py负责对于下载到的图片进行resize。
一、先看douban.py。
#!/usr/bin/env python '''This is a simple tool on seraching something like books, films, etc using douban.com''' # -*- coding:utf-8-*- import wx import os from papapa import * from image import * |
第一行是为了在类Unix系统中,告诉系统执行程序的解释器,而window会自动忽略。
第二行是文档字符串,当模块中的第一句是字符串的时候,这个字符串就成了该模块的文档字符串,并存储在__doc__属性中,可以访问。
第三行是编码,因为爬虫的过程中涉及到中文难的编码,这个还吃过亏,后面会说。
这些都是些习惯,好习惯!
下面的就是导入库,还有另外两个模块,因为另外两个模块都比较简单,就import *了,平常不建议用。
# Frame class Frame(wx.Frame):
def __init__(self, parent, id): wx.Frame.__init__(self, parent, id, title='Douban Searching...', size=(600, 735), pos=(200, 0))
# status bar self.statusBar = self.CreateStatusBar() self.statusBar.SetStatusText("Please enter movie or book's name")
# split window sp = wx.SplitterWindow(self, size=(600, 300), style=wx.SP_3D) self.panel1 = wx.Panel(sp, -1) self.panel1.SetBackgroundColour('White') self.panel2 = wx.Panel(sp, -1) self.panel2.SetBackgroundColour('White') sp.SplitHorizontally(self.panel1, self.panel2, 180)
# self.panel1 self.font = wx.Font(13, wx.SCRIPT, wx.NORMAL, wx.NORMAL) self.static1 = wx.StaticText(self.panel1, -1, 'Please enter name:', pos=(50, 48)) self.static1.SetFont(self.font) self.text = wx.TextCtrl(self.panel1, -1, size=(220, -1), pos=(230, 50), style=wx.TE_PROCESS_ENTER) self.text.SetFocus() self.Bind(wx.EVT_TEXT_ENTER, self.OnJudge, self.text) self.Bind(wx.EVT_TEXT, self.OnPrint, self.text)
self.static2 = wx.StaticText(self.panel1, -1, 'Catagories:', pos=(114, 90)) self.static2.SetFont(self.font) self.radio1 = wx.RadioButton(self.panel1, -1, 'Movie', pos=(230, 95)) self.radio2 = wx.RadioButton(self.panel1, -1, 'Book', pos=(230, 125)) self.radio1.SetValue(1)
self.button = wx.Button(self.panel1, -1, label='Enter', pos=(350, 100), size=(100, 40)) self.button.Bind(wx.EVT_LEFT_DOWN, self.OnJudge)
# self.panel2 self.static3 = wx.StaticText(self.panel2, -1, 'Poster:', pos=(50, 10)) self.static3.SetFont(self.font) self.static4 = wx.StaticText(self.panel2, -1, 'Mark:', pos=(300, 10)) self.static4.SetFont(self.font) self.static4.SetForegroundColour('Orange') self.static5 = wx.StaticText(self.panel2, -1, 'Informations:', pos=(50, 250)) self.static5.SetFont(self.font) |
wxPython的思想是,只有一个App对象,但可以有多个Frame对象,这里一个就已经够了。
Frame对象继承自wxPython里的Frame对象,注意构造函数一定要显式的写出wx.Frame的初始化方式,参数也都很容易理解,parent是父对象,id表示唯一的一个索引,title,size和pos都比较直白。
statusBar实现起来非常简单,直接CreateStatusBar()函数构造,SetStatusText()被用来更改statusBar里的字符串。wxPython会很自然的将它放在整个窗体的底层,不需要声明其pos。
split window并不是必要的,但是会让整个窗体的结构更加清晰,而且实现起来并不困难。直接调用wx.SplitterWindow,style是分割线的样式。这里要分割成两个垂直的面板,就分别调用wx.Panel生成panel对象,wx.Panel的参数为(parent, id, pos, size, style, name),id=-1的时候wxPython自动赋予对象一个不冲突的id,panel对象有自己的方法,比如这里的设置背景颜色,SetBackgroundColour。SplitHorizontally(self, window1, window2, sashposition)是垂直分割的关键,参数看着也非常清楚,水平分割就是SplitVertically。
下面来安排panel里的内容。我预想的,panel1负责信息的输入,比如电影,图书的名字,比如类别,比如确定输入的"Enter"键。
而panel2就是负责信息的输出,比如说海报,比如说评分,比如说其他的信息。
默认的字体不合适,可以通过wx.Font()构造自己的字体形式。形参为(pointSize, family, style, weight, underline, face, encoding),很清晰,分别为字体大小、字体、字体样式(比如是否倾斜)、字体粗细等。
静态文本是StaticText,这里的parent属性即为panel,第三个参数为文本的内容,文本的位置和大小,需要自己调节。借用已有的字体对象,可以用SetFont方法很方便的构建。
输入字符框是wx.TextCtrl()方法,参数也比较简单,需要先注意的是,SetFocus方法可以在应用初始的时候自动化的焦点,Bind是用来绑定事件的,第一个参数是事件类型,第二个参数是事件处理函数,第三个是绑定对象。
Wx.RadioButton可以用来构建单选框,SetValue这里是用来设置默认选项的。
整个应用,界面还算简单,核心的其实是事件处理函数!
这里有两个。
def OnJudge(self, event):
self.name = self.text.GetValue().encode('utf-8') if(self.radio1.GetValue()): self.value = 'movie' else: self.value = 'book'
if(self.name==''): dlg = wx.MessageDialog(None, "Input cannot be empty!", 'Tip', wx.YES_NO | wx.ICON_QUESTION) if dlg.ShowModal() == wx.ID_YES: dlg.Destroy() else: self.Post()
def Post(self):
# html analysis html = getHTML(self.name, self.value) data = getData(html, self.value)
self.static6 = wx.StaticText(self.panel2, -1, data['mark'], pos=(400, 60)) self.font1 = wx.Font(25, wx.SCRIPT, wx.NORMAL, wx.BOLD) self.static6.SetFont(self.font1) self.static6.SetForegroundColour('Red') self.static7 = wx.StaticText(self.panel2, -1, data['comment'].decode('utf-8'), pos=(370, 100)) self.static7.SetFont(self.font) self.static7.SetForegroundColour('Red')
# img Resize('D:/poster.jpg') jpg = wx.Image('D:/poster.jpg', wx.BITMAP_TYPE_ANY).ConvertToBitmap() wx.StaticBitmap(self.panel2, -1, jpg, pos= (140, 20))
self.static8 = wx.StaticText(self.panel2, -1, data['info'].decode('utf-8'), pos=(200, 250), style=wx.TE_MULTILINE) self.static8.SetFont(self.font) self.statusBar.SetStatusText('Successfully!')
def OnPrint(self, event): self.statusBar.SetStatusText("Please enter movie or book's name") |
本来一个函数就可以,分割成两个模块,功能更清晰。
Judge函数用来分流,将movie和book两个类型分开。输入框里的字符是中文,需要重新encode,否则就会出现乱码,这在Python中经常出现。
Post函数负责将输入得到的信息进行处理,然后输出在界面上。这个过程,就交给另外一个papapa.py模块。
# -*- coding: utf-8 -*- import urllib import re
def getHTML(name, category): url = 'https://' + category + '.douban.com/subject_search?search_text=' + name page = urllib.urlopen(url) html = page.read() return html
def getData(html, category): if(category=='movie'): reg = r'<a class="nbg".*?>.*?<img src="(.*?)".+?<p class="pl">(.+?)</p>.+?<span class="rating_nums">(.+?)</span>.+?class="pl">(.+?)</span>' elif(category=='book'): reg = r'<a class="nbg".*?>.*?<img.*?src="(.*?)".+?<div class="pub">(.+?)</div>.+?<span class="rating_nums">(.+?)</span>.+?class="pl">(.+?)</span>' reData = re.compile(reg, re.S) data = re.search(reData, html) final = {} final['imgUrl'] = data.group(1) if(category=='movie'): final['imgUrl'] = final['imgUrl'].replace('ipst', 'lpst') elif(category=='book'): final['imgUrl'] = final['imgUrl'].replace('mpic', 'lpic') urllib.urlretrieve(final['imgUrl'], 'D:/poster.jpg') final['info'] = data.group(2).replace('/', ' ').strip() final['mark'] = data.group(3) final['comment'] = data.group(4).strip() return final |
getHTML是获得HTML,用Python内建的urllib来执行,open是打开网站,read出来的就是HTML。
getData是核心的处理函数,用来解析HTML里需要的有用的信息。这个需要查看豆瓣网站的源代码,总结出普遍的模式,然后写成正则表达式,这是最难的部分。正则表达有很多要说的,这里就不展开了。继续往下看。
这里我将所有的信息都存储在一个字典中,然后返回字典。
海报图片有大小两种格式,仔细观察后发现仅有一部分字符串的差异,替代即可。对于获得的字符串稍微进行一下格式处理,如strip(), replace(), 即可。
图片部分就是进行了一次Resize。
import Image import math import os import sys
def Resize(name): infile = name outfile = name im = Image.open(infile) (x, y) = im.size x_s = 130 y_s = 200 out = im.resize((x_s, y_s), Image.ANTIALIAS) out.save(outfile) |
剩下的部分就是格式化的了,不赘述。
# Application class App(wx.App):
def OnInit(self): self.frame = Frame(parent=None, id=-1) self.frame.Show() self.SetTopWindow(self.frame) return True
def OnExit(self): # delete poster filename = 'D:/poster.jpg' if(os.path.exists(filename)): os.remove(filename) return True
if __name__ == '__main__': app = App() app.MainLoop() |
稍微调试,觉得没问题,就可以打包了。
以前没有打包过程序,用了一下,想不到很简单。我是用的pyinstaller,可以参照http://www.cnblogs.com/dacainiao/p/5918845.html。
这里只说两句,想打包成单独可执行文件,也就是exe的,加-F命令,想要去掉控制台的,加-w参数。
界面如下。
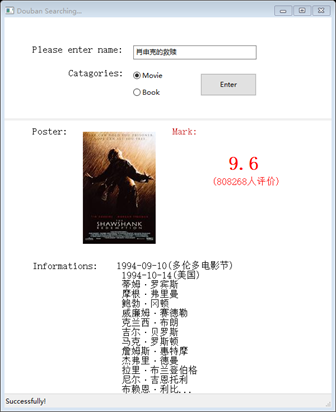
总结:以前没有接触过GUI,感觉很有意思,但是wxPython的文档个人觉得有些混乱,下面打算试着用PyQt。这个小软件还有些小Bug,代码里也能看到,输出的无论是图片还是文本,都只是覆盖了前面的部分,并没有清除。下一步要修复这个。
代码在这里:https://github.com/Lucifer25/Douban_Search_Mark。(备注:douban.exe下载即可用,360或许会报毒,忽略即可)