哈希算法
哈希算法
什么是哈希算法
-
从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法)
-
对输入数据非常敏感,哪怕原始数据只修改了一个Bit,最后得到的哈希值也大不相同
-
散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小
-
哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值。
哈希算法的应用
应用一:安全加密
说到哈希算法的应用,最先想到的应该就是安全加密。最常用于加密的哈希算法是MD5(MD5 Message-Digest Algorithm,MD5消息摘要算法)和SHA(Secure Hash Algorithm,安全散列算法)。
对用于加密的哈希算法来说,有两点格外重要。第一点是很难根据哈希值反向推导出原始数据,第二点是散列冲突的概率要很小。
第一点很好理解,加密的目的就是防止原始数据泄露,所以很难通过哈希值反向推导原始数据,这是一个最基本的要求。所以我着重讲一下第二点。实际上,不管是什么哈希算法,我们只能尽量减少碰撞冲突的概率,理论上是没办法做到完全不冲突的。
没有绝对安全的加密。越复杂、越难破解的加密算法,需要的计算时间也越长。比如SHA-256比SHA-1要更复杂、更安全,相应的计算时间就会比较长。密码学界也一直致力于找到一种快速并且很难被破解的哈希算法。我们在实际的开发过程中,也需要权衡破解难度和计算时间,来决定究竟使用哪种加密算法。
应用二:唯一标识
我们可以给每一个图片取一个唯一标识,或者说信息摘要。比如,我们可以从图片的二进制码串开头取100个字节,从中间取100个字节,从最后再取100个字节,然后将这300个字节放到一块,通过哈希算法(比如MD5),得到一个哈希字符串,用它作为图片的唯一标识。通过这个唯一标识来判定图片是否在图库中,这样就可以减少很多工作量。
如果还想继续提高效率,我们可以把每个图片的唯一标识,和相应的图片文件在图库中的路径信息,都存储在散列表中。当要查看某个图片是不是在图库中的时候,我们先通过哈希算法对这个图片取唯一标识,然后在散列表中查找是否存在这个唯一标识。
应用三:数据校验
我们通过哈希算法,对100个文件块分别取哈希值,并且保存在种子文件中。我们在前面讲过,哈希算法有一个特点,对数据很敏感。只要文件块的内容有一丁点儿的改变,最后计算出的哈希值就会完全不同。所以,当文件块下载完成之后,我们可以通过相同的哈希算法,对下载好的文件块逐一求哈希值,然后跟种子文件中保存的哈希值比对。如果不同,说明这个文件块不完整或者被篡改了,需要再重新从其他宿主机器上下载这个文件块。
应用四:负载均衡
我们知道,负载均衡算法有很多,比如轮询、随机、加权轮询等。那如何才能实现一个会话粘滞(session sticky)的负载均衡算法呢?也就是说,我们需要在同一个客户端上,在一次会话中的所有请求都路由到同一个服务器上。
最直接的方法就是,维护一张映射关系表,这张表的内容是客户端IP地址或者会话ID与服务器编号的映射关系。客户端发出的每次请求,都要先在映射表中查找应该路由到的服务器编号,然后再请求编号对应的服务器。
如果借助哈希算法,这些问题都可以非常完美地解决。我们可以通过哈希算法,对客户端IP地址或者会话ID计算哈希值,将取得的哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由到的服务器编号。 这样,我们就可以把同一个IP过来的所有请求,都路由到同一个后端服务器上。
应用五:数据分片
假如我们有1T的日志文件,这里面记录了用户的搜索关键词,我们想要快速统计出每个关键词被搜索的次数,该怎么做呢?
我们来分析一下。这个问题有两个难点,第一个是搜索日志很大,没办法放到一台机器的内存中。第二个难点是,如果只用一台机器来处理这么巨大的数据,处理时间会很长。
针对这两个难点,我们可以先对数据进行分片,然后采用多台机器处理的方法,来提高处理速度。具体的思路是这样的:为了提高处理的速度,我们用n台机器并行处理。我们从搜索记录的日志文件中,依次读出每个搜索关键词,并且通过哈希函数计算哈希值,然后再跟n取模,最终得到的值,就是应该被分配到的机器编号。
这样,哈希值相同的搜索关键词就被分配到了同一个机器上。也就是说,同一个搜索关键词会被分配到同一个机器上。每个机器会分别计算关键词出现的次数,最后合并起来就是最终的结果。
实际上,这里的处理过程也是MapReduce的基本设计思想,针对这种海量数据的处理问题,我们都可以采用多机分布式处理。借助这种分片的思路,可以突破单机内存、CPU等资源的限制。。
应用六:分布式存储
在数据增加需要扩充机器时:原来的数据是通过与10来取模的。比如13这个数据,存储在编号为3这台机器上。但是新加了一台机器中,我们对数据按照11取模,原来13这个数据就被分配到2号这台机器上了。
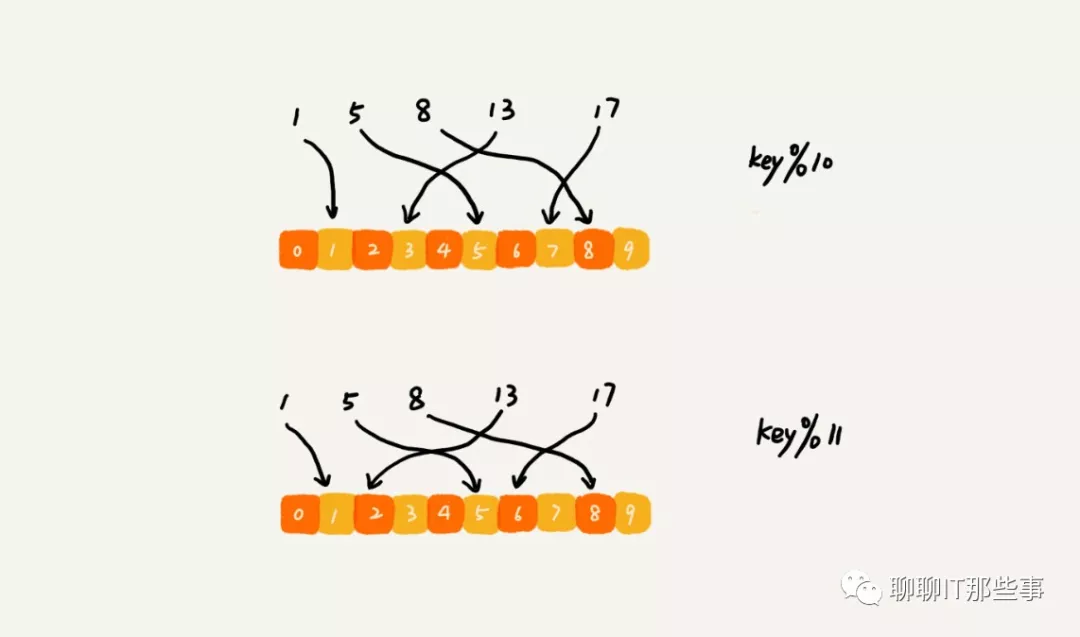
因此,所有的数据都要重新计算哈希值,然后重新搬移到正确的机器上。这样就相当于,缓存中的数据一下子就都失效了。所有的数据请求都会穿透缓存,直接去请求数据库。这样就可能发生雪崩效应,压垮数据库。
所以,我们需要一种方法,使得在新加入一个机器后,并不需要做大量的数据搬移。这时候,一致性哈希算法就要登场了。
假设我们有k个机器,数据的哈希值的范围是[0, MAX]。我们将整个范围划分成m个小区间(m远大于k),每个机器负责m/k个小区间。当有新机器加入的时候,我们就将某几个小区间的数据,从原来的机器中搬移到新的机器中。这样,既不用全部重新哈希、搬移数据,也保持了各个机器上数据数量的均衡。