分布式文件系统介绍
分布式文件系统:Hadoop Distributed File System,简称HDFS。
一、HDFS简介
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高 度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
二、HDFS设计目标
·支持海量的数据,硬件错误是常态,因此需要备份。
·一次写多次读(write-once-read-many)的存取模式。
·运行在普通的硬件上面。
·数据块(默认大小是64M)尽量散步到各个节点中。
三、HDFS能做什么?
HDFS适合做什么?
·存储并管理PB级数据。
·处理非结构化数据。
·注重数据处理的吞吐量。
·应用模式为:write-once-read-many存取模式。
HDFS不适合做?
·存储小文件(不建议使用)。
·大量的随机读(不建议使用)。
·需要对文件的修改(不支持)。
四、几个基本概念
4.1 数据块
每个磁盘都有默认的数据块大小,这是磁盘进行数据读写的最小单位。构建与单个磁盘之上的文件系统通过磁盘块来管理该文件系统中的块(大小一般为512 byte)。HDFS中也有块(block)的概念,默认大小为64M,HDFS上的文件被华为为块大小的多个分块(chunk),作为独立的存储单元,但于其他文件系统不同的是,HDFS中小于一个块大小的文件不会占整个块的空间。
为何HDFS中的块设置如此之大?
HDFS的块比磁盘块达,其目的是为了减小寻址开销。如果设置的足够大,磁盘传输数据的时间将明显大于寻址时间,这样一个由多个块组成的文件时间取决于磁盘传输速率。
4.2 namenode和datanode
HDFS主要由namenode和datanode组成, 并以管理者/工作者模式运行,即一个namenode和多个datanode。
Namenode:
namenode管理文件系统的命名空间,它维护者文件系统树及整棵树内所有的文件和目录。这些管理信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。namenode 也记录着每个文件中各个块所在的数据节点信息,但它井不永久保存块的位置信息,因为这些信息会在系统启动时由数据节点重建。
Datanode:
datanode 是文件系统的工作节点。它们根据需要存储井检索数据块(受客户端或namenode 调度),井且定期向namenode 发送它们所存储的块的列表。客户端(c1ient)代表用户通过与namenode 和datanode 交互来访问整个文件系统。
综上:没有namenode ,文件系统将无泣使用。事实上,如果运行namenode 服务的机器毁坏,文件系统上所有的文件将会丢失,因为我们不知道如何根据datanode 的块来重建文件。
五、HDFS架构
1. 一个文件被划分成大小固定的多个文件块,分布的存储在集群中的节点中。

一个文件一台电脑直接读取需要花费很多时间,但是多个电脑同时读取就可以看出速度啦。
2. 同一个文件块在不同的节点中有多个副本。

如果说第一个节点处的文件失效不能工作了,那么hadoop根据你的配置去自动需找其他的副本,这些副本的拷贝是在hadoop的配置文件中进行指定的,副本的个数都是可以配置的。
3. 一个集中的地方保存文件的分块信息。一般保存在/home/hdfs/目录下。

集中的地方就叫做namenode用于保存分块的信息,namenode只有一个,首先我们必须从namenode获得分块信息,上面就是namenode中分块的信息。

上图是datanode的信息,就是讲文件进行分块存储,然后进行并行读取节点信息,相比传统的方式,一般是将硬盘作为一个节点进行存储,而hadoop则是将分布的主机作为节点进行存储。
六、HDFS体系结构
下图为HDFS的体系结构:
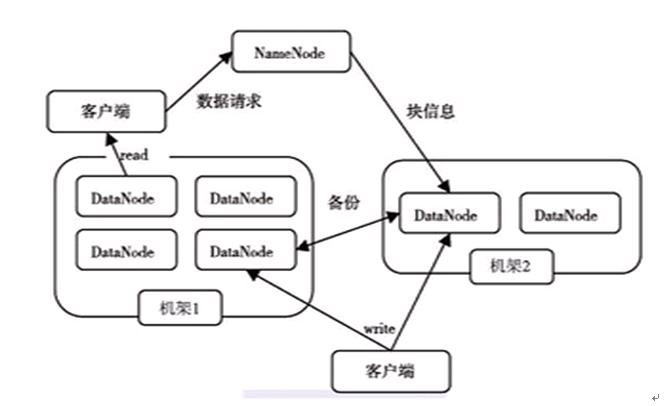
读取数据流程:
- 客户端要访问HDFS中的一个文件。
- 首先从namenode获取组成这个文件的数据库位置列表。
- 根据列表知道存储数据块的datanode。
- 访问datanode获取数据。
- Namenode并不参与数据实际传输。