本次,我们接着学习神经网络的知识,这里介绍池化层,和经典的非线性激活函数,并简要的介绍一下 pytorch 中的其它层次,最后我们使用搭建神经网络(并使用以下 torch.nn.Sequential)。
Pooling Layers
本小节,我们介绍一下池化层的相关知识。
池化层的作用
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。也就是池化层赋予了我们网络更快的运算速度和更高的鲁棒性。
而且池化层是我们卷积神经网络中经常用到的层,基本每个网络都会有池化层,池化层也很简单。
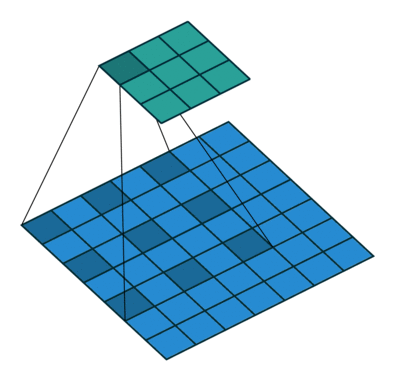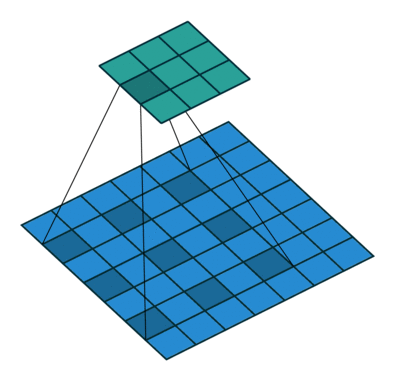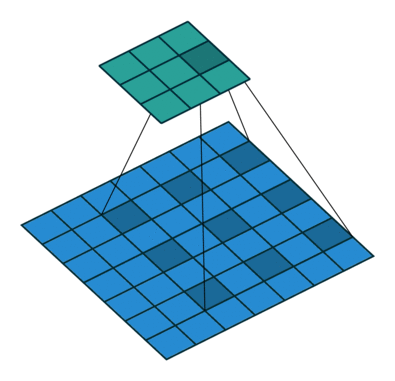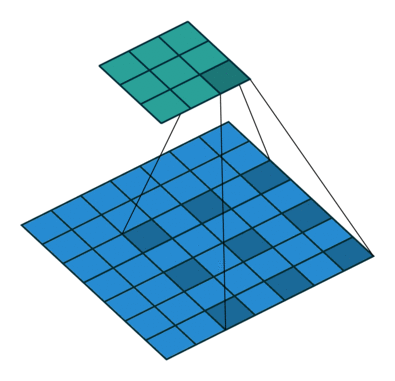
常见的池化层有 max-pooling 和 average-pooling,该两种操作一个是取卷积核中的 最大值,一个是取平均值
Max Pooling是对某个Filter抽取到若干特征值,只取得其中最大的那个Pooling层作为保留值,其他特征值全部抛弃,值最大代表只保留这些特征中最强的,抛弃其他弱的此类特征。
有以下几个优点:
1、保证特征的位置与旋转不变性。对于图像处理这种特性是很好的。至于如何理解图像进行池化(pooling)后的平移不变性?
手边没有图,我就抽象一点回答了。假如三个元素(1,5,3)取max就取到5,如果三个元素向右平移一下变成(0,1,5),那取max之后还是5,具备了平移不变性。大概就是这么个理。
2、减少模型参数数量,缓解过拟合问题
3、可以把变长的输入x整理成固定长度的输入。CNN往往最后连接全连接层,在训练过程中,神经元个数需要固定好,但是cnn输入x长度不确定,通过pooling操作,每个filter固定取一个值。有多少个Filter,Pooling就有多少个神经元,这样就可以把全连接层神经元固定住。
pytorch 池化层帮助文档查看
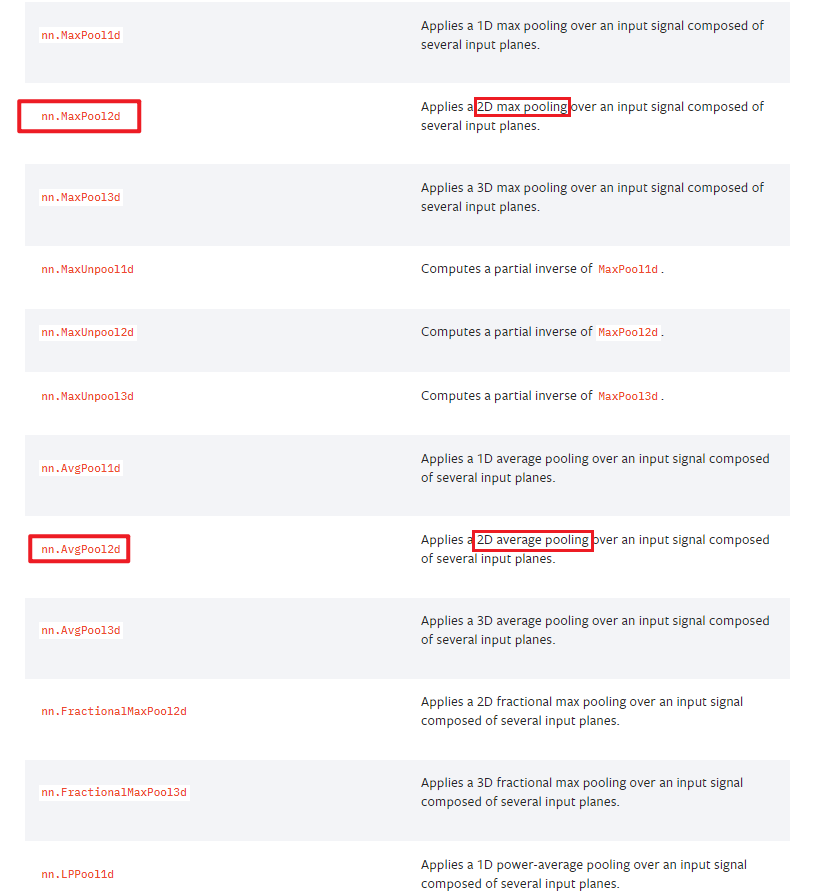
这里,我们详细查看以下 torch.nn.MaxPool2d 为例


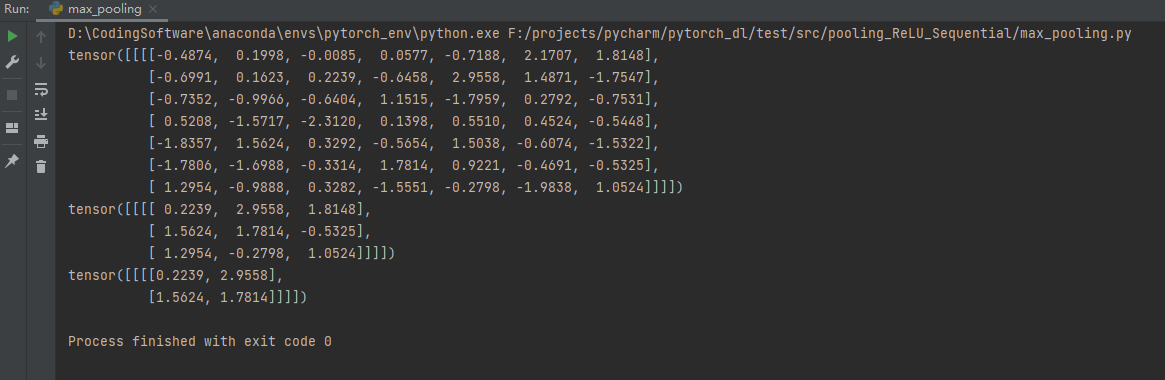
代码实例测试
请注意看,他的帮助文档标注的是可以使 NCHW,也可以是 CHW 两种模式。
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
my_data = torch.randn((1, 1, 7, 7))
ceil_max_pool = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=True)
floor_max_pool = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=False) # stride 默认值是kernel_size
ceil_result = ceil_max_pool(my_data)
floor_result = floor_max_pool(my_data)
print(my_data)
print(ceil_result)
print(floor_result)
运行结果:
下面我们考虑采样一下CIFAR10 这个数据集的图片,并使用 average_pooling 和 max_pooling 试一下。
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from torch.utils.tensorboard import SummaryWriter
data_path = "../../data_cifar10"
data_test = torchvision.datasets.CIFAR10(data_path, train=False, transform=torchvision.transforms.ToTensor(),
download=True)
data_loader = DataLoader(data_test, batch_size=64)
class MyModel(torch.nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.max_pool = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=True)
self.ave_pool = torch.nn.AvgPool2d(kernel_size=3, ceil_mode=True)
def forward(self, img):
return self.max_pool(img), self.ave_pool(img)
writer = SummaryWriter(log_dir="../../logs")
my_model = MyModel()
step = 0
for imgs, targets in data_loader:
writer.add_images("images-original", imgs, step)
imgs_max_pooling, imgs_ave_pooling = my_model(imgs)
writer.add_images("images-max-pooling", imgs_max_pooling, step)
writer.add_images("images-ave-pooling", imgs_ave_pooling, step)
writer.close()
Non-linear Activations
非线性激活的作用
总体来讲,激活函数是用来加入非线性因素的,解决线性模型所不能解决的问题。具体的一些详细的解释,请参考下述链接:
参考资料知乎:神经网络激活函数的作用和原理?有没有形象解释?
Non-linear Activations Doc
介绍完非线性激活的作用之后,我们查看 pytorch 关于非线性激活的 API 和他们的帮助文档。这里,我们主要介绍的是 ReLU 和 Sigmoid 两个常见的激活函数。

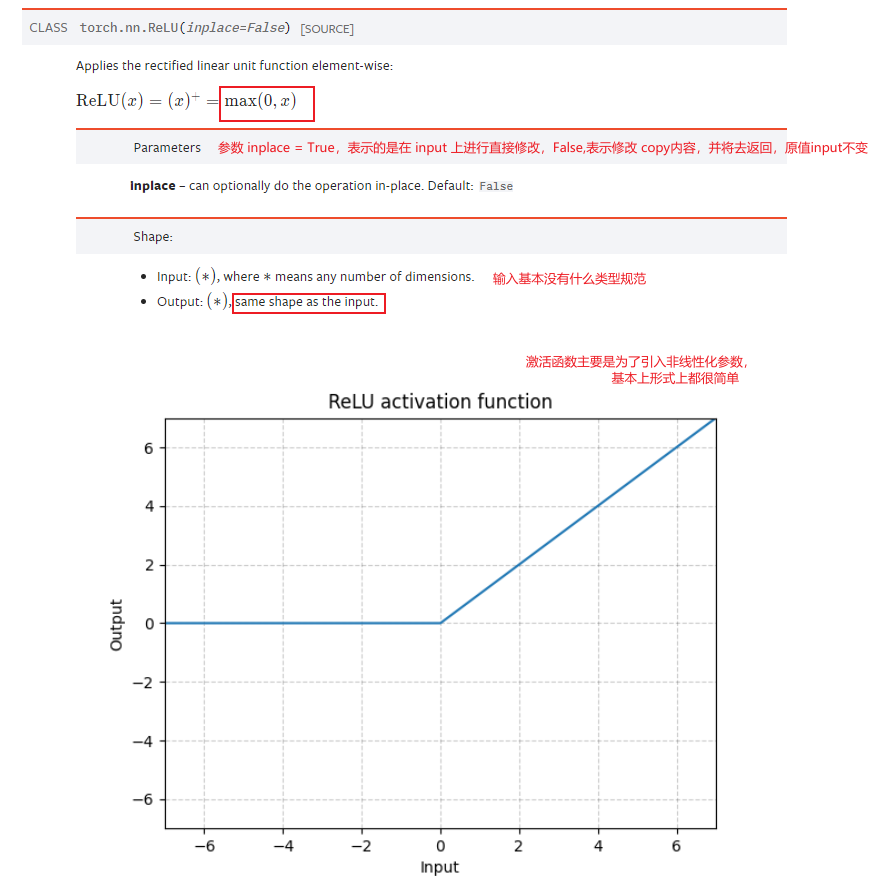
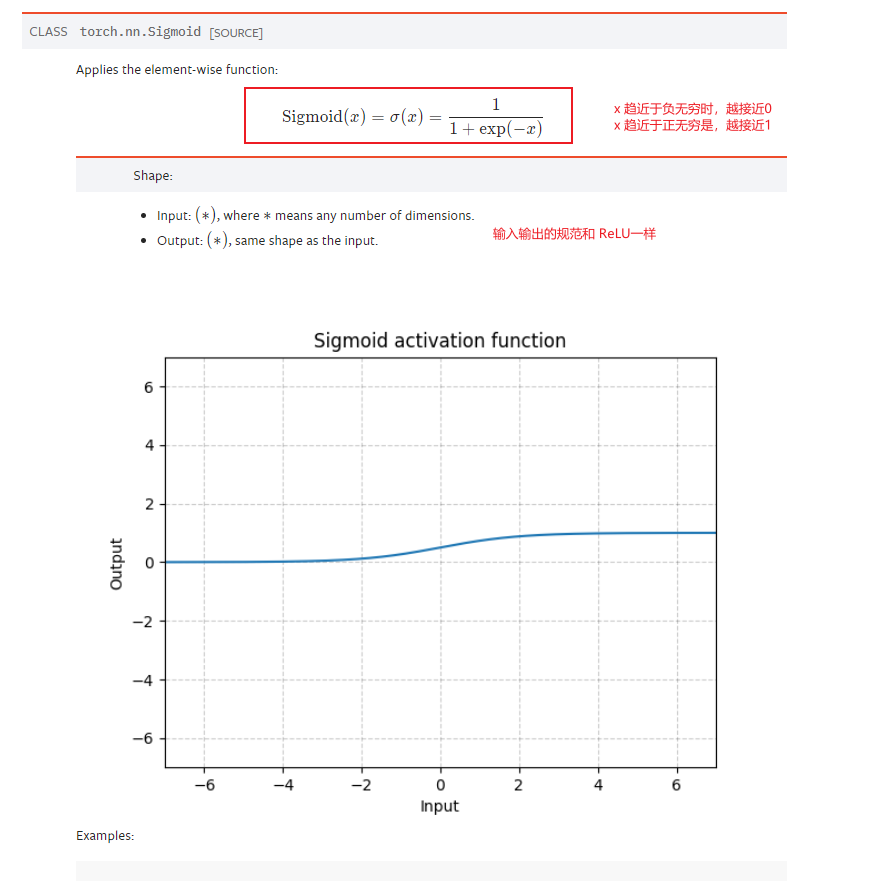
代码示范
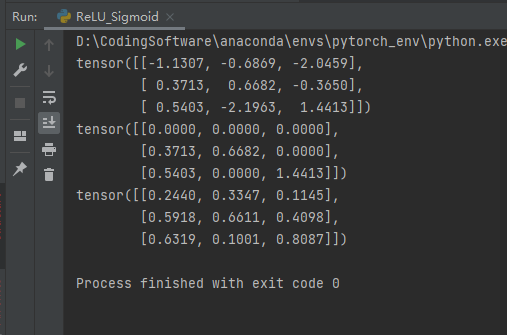
下面我们写一个代码查看一下 ReLU 和 Sigmoid 的效果
import torch.nn as nn
import torch
import torchvision
data = torch.randn((3, 3))
print(data)
my_relu = nn.ReLU()
my_sigmoid = nn.Sigmoid()
print(my_relu(data))
print(my_sigmoid(data))
运行结果如下所示:
神经网络的其它层次介绍
首先我们查阅 torch.nn 的官方帮助文档:

可以看到,他有很多层次 layers 和 功能函数 function,但是我们已经将最最最经常使用的层给介绍过了。下面我建议各位小伙伴们选择几个喜欢的层次,练一练自己的官方文档阅读能力。
我选择我比较喜欢的两个部分,一个是 Normalization Layers 和 Dropout Layers
Normalization Layers


Dropout Layers
下面,我们简单写一个代码来进行测试一下看看,对CIFAR10 数据集首先进行 sigmod 操作,然后直接 Normalization 正则一下。
import torch
import torch.nn as nn
import torchvision
import torch.utils.data
from torch.utils.tensorboard import SummaryWriter
image_path = "../../data_cifar10"
log_path = "../../logs"
writer = SummaryWriter(log_dir=log_path)
dataset = torchvision.datasets.CIFAR10(root=image_path, train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64, drop_last=False)
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = nn.Sequential(
nn.Sigmoid(),
nn.BatchNorm2d(num_features=3)
)
def forward(self, x):
return self.model(x)
my_model = MyModel()
step = 0
for images, targets in dataloader:
model_images = my_model(images)
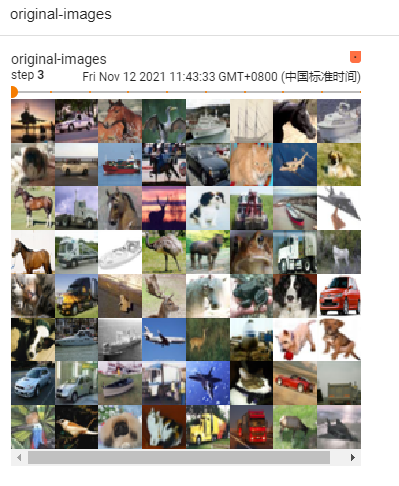
writer.add_images("original-images", images, step)
writer.add_images("sigmoid-norm-images", model_images, step)
step += 1
writer.close()
运行 tensorboard 查看结果

Dropout Layer
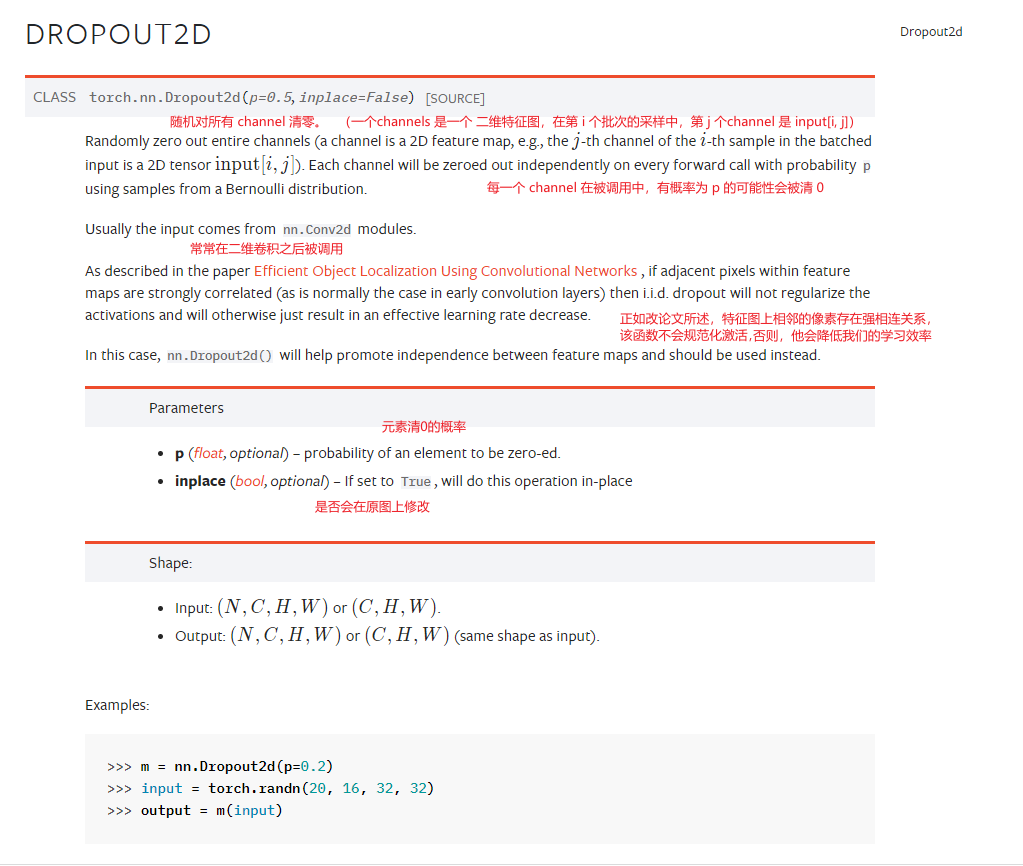
打开 dropout 官方文档,pick了 nn.Dropout2d 进行查阅。
下面,我写一个二维的卷积,续接这个 Dropout Layer 实例一下子:
import torch
import torch.nn as nn
import torchvision
import torch.utils.data
from torch.utils.tensorboard import SummaryWriter
image_path = "../../data_cifar10"
log_path = "../../logs"
writer = SummaryWriter(log_dir=log_path)
dataset = torchvision.datasets.CIFAR10(root=image_path, train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64, drop_last=False)
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Dropout(p=0.2, inplace=False)
)
def forward(self, x):
return self.model(x)
my_model = MyModel()
step = 0
for images, targets in dataloader:
model_images = my_model(images)
writer.add_images("read-original-images", images, step)
writer.add_images("Con2d-Dropout-images", model_images, step)
step += 1
writer.close()
tensorboard 查看图片


搭建CIFAR 10 model
这里,我们将神经网络的基本结果说的差不过了,下面我们尝试建立一下一个简单的神经网络
在搭建一个神经网络之前,我们先介绍一下之前没有用过的两个函数。
- nn.Flatten()
- nn.linear()
nn.Flatten() 函数
该函数理解较为简单,帮助文档写的也是非常的简洁。
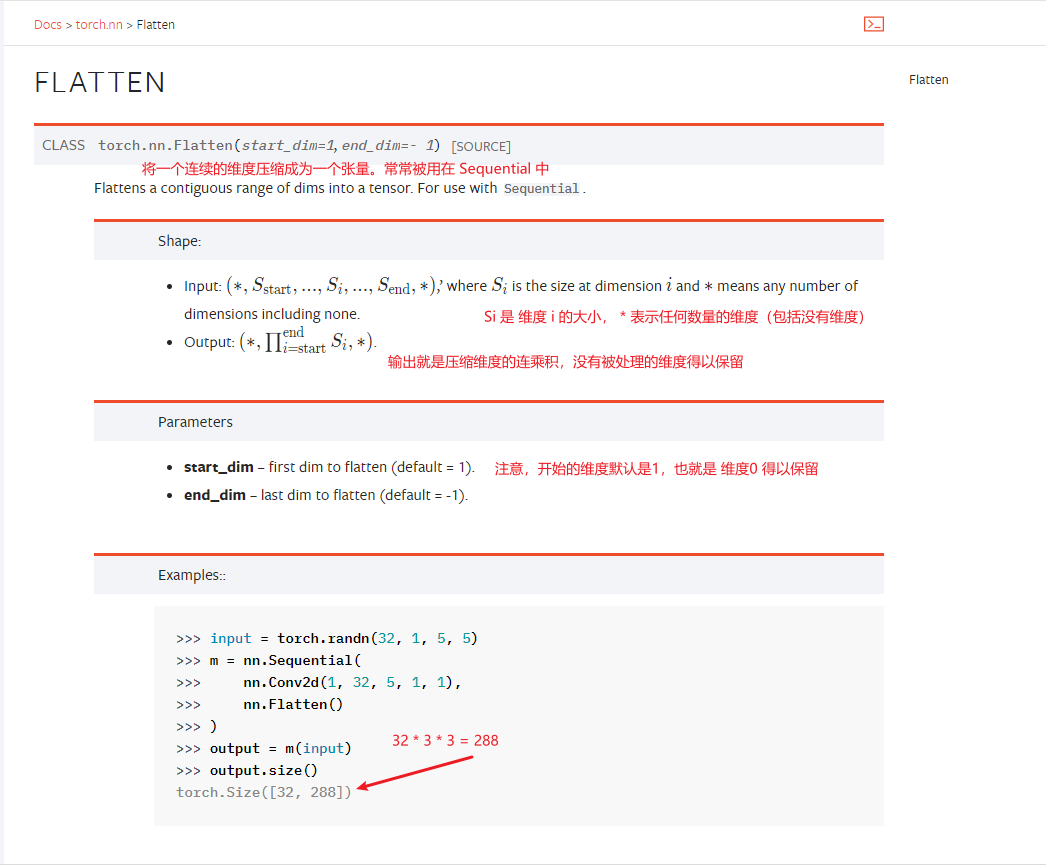
nn.linear()函数
挺简单的一个线性变换函数:

CIFAR 10 Model 网络的构建
首先查看网络的样子:
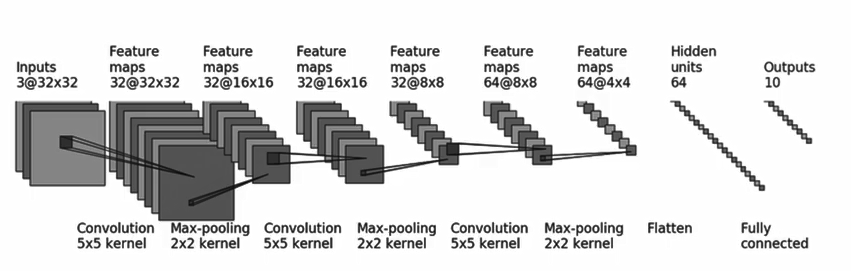
然后根据网络之前的形态变换,将其转换成代码即可,主要看他们的 inchannel, outchannel,kernel 等等的信息。
写出来的网络代码:
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
images_path = "../../data_cifar10"
logs_path = "../../logs"
dataset = torchvision.datasets.CIFAR10(root=images_path, train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset=dataset, batch_size=64, drop_last=False)
class MyModel(torch.nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = torch.nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, padding=0),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, padding=0),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, padding=0),
nn.Flatten(start_dim=1, end_dim=-1), # 将它展平之后, dimension0 是 batch,后面的特征需要改变
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
return self.model(x)
step = 0
my_model = MyModel()
tmp = torch.randn((1, 3, 32, 32))
# tmp2 = my_model(tmp)
writer = SummaryWriter(log_dir=logs_path)
# for images, targets in dataloader:
# images_proceed = my_model(images)
# writer.add_images("original", images, step)
# writer.add_images("proceed", images_proceed, step) # 没办法的当图片写进入,应为规格不符要求
# step += 1
writer.add_graph(my_model, input_to_model=tmp)
writer.close()
下面是看起来很有意思的运算图 graph
