# 今日头条 # https://www.autohome.com.cn/news/1/#liststart ###### #2 爬取汽车之家新闻 ###### import requests # 向汽车之家发送get请求,获取到页面 ret=requests.get('https://www.autohome.com.cn/news/1/#liststart') # ret.encoding='gb2312' # print(ret.text) # bs4解析(不用re了) # 安装 pip3 install beautifulsoup4 # 使用 from bs4 import BeautifulSoup # 实例化得到对象,传入要解析的文本,解析器 # html.parser内置解析器,速度稍微慢一些,但是不需要装第三方模块 # lxml:速度快一些,但是需要安装 pip3 install lxml soup=BeautifulSoup(ret.text,'html.parser') # soup=BeautifulSaoup(open('a.html','r')) # 可以解析本地文件,不怎么用 # find(找到的第一个) # find_all(找到的所有) # 找页面所有的li标签 li_list=soup.find_all(name='li') for li in li_list: # li是Tag对象 # print(type(li)) # <class 'bs4.element.Tag'> Tag对象 h3=li.find(name='h3') if not h3: continue title=h3.text desc=li.find(name='p').text # 对象支持[]取值,为什么?重写了__getitem__魔法方法 # 面试题:你使用过的魔法方法? img=li.find(name='img')['src']# type:str url=li.find(name='a')['href'] # 图片下载到本地 ret_img=requests.get('https:'+img) img_name=img.rsplit('/',1)[-1] with open(img_name,'wb') as f: for line in ret_img.iter_content(): f.write(line) print(''' 新闻标题:%s 新闻摘要:%s 新闻链接:%s 新闻图片:%s '''%(title,desc,url,img))
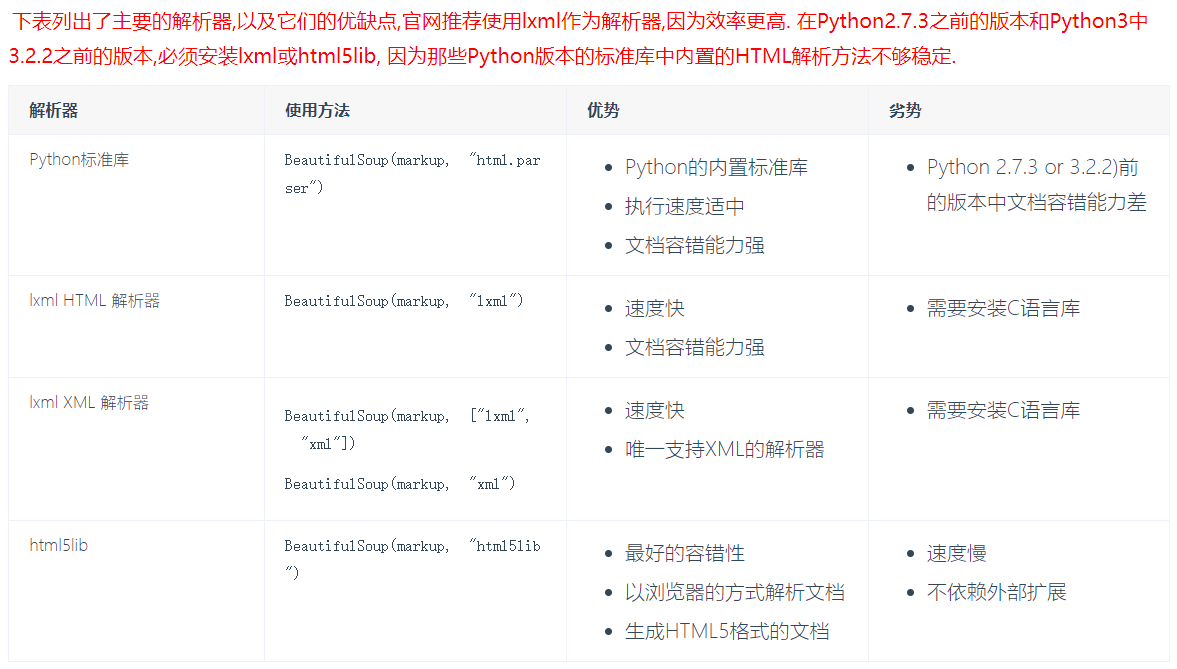
# 1 从html或者xml中提取数据的python库,修改xml # 补充:java,配置文件基本都是xml格式,以后可能会用python修改配置文件(自动化运维平台,devops平台),mycat,自动上线,自动安装软件,配置,查看nginx日志 # 视频,生鲜,crm,鲜果配送,在线教育,cmdb ---》(sugo平台) # 飞猪 (旅游相关) 毒app 兔女郎
遍历文档树
from bs4 import BeautifulSoup html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"id="id_p"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ # pip3 install lxml soup=BeautifulSoup(html_doc,'lxml') # 文档容错能力强,可以容忍没有</html>结尾 # 美化 # print(soup.prettify()) # 遍历文档树 #1、用法(通过.来查找,只能找到第一个) # Tag对象 # head=soup.head # title=head.title # # print(head) # print(title) # p=soup.p # print(p) #2、获取标签的名称 #Tag对象 # p=soup.body # print(type(p)) from bs4.element import Tag # print(p.name) #3、获取标签的属性 # p=soup.p # 方式一 # 获取class属性,可以有多个,拿到列表 # print(p['class']) # print(p['id']) # print(p.get('id')) # 方式二 # print(p.attrs['class']) # print(p.attrs.get('id')) #4、获取标签的内容 # p=soup.p # print(p.text) # 所有层级都拿出来拼到一起 # print(p.string) # 只有一层,才能取出 # print(list(p.strings)) # 把每次都取出来,做成一个生成器 #5、嵌套选择 # title=soup.head.title # print(title) #6、子节点、子孙节点 # p1=soup.p.children # 迭代器 # p2=soup.p.contents # 列表 # print(list(p1)) # print(p2) #7、父节点、祖先节点 # p1=soup.p.parent # 直接父节点 # p2=soup.p.parents # 可能会有重复,比如父父级会列出,但是父级的父级也会列出 # print(p1) # # print(len(list(p2))) # print(list(p2)) #8、兄弟节点 # print(soup.a.next_sibling) #下一个兄弟 # print(soup.a.previous_sibling) #上一个兄弟 # # print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象 # print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象
查找文档树
# 查找文档树(find,find_all),速度比遍历文档树慢 # 两个配合着使用(soup.p.find()) # 五种过滤器: 字符串、正则表达式、列表、True、方法 # 以find为例 #1 字符串查找 引号内是字符串 # p=soup.find(name='p') # p=soup.find(name='body') # print(p) # 查找类名是title的所有标签,class是python的保留关键字,所以无法使用class这个关键字,class_ # ret=soup.find_all(class_='title') # href属性为http://example.com/elsie的标签 # ret=soup.find_all(href='http://example.com/elsie') # 找id为xx的标签 # ret=soup.find_all(id='id_p') # print(ret) #2 正则表达式 # import re # # reg=re.compile('^b') # # ret=soup.find_all(name=reg) # #找id以id开头的标签 # reg=re.compile('^id') # ret=soup.find_all(id=reg) # print(ret) # 3 列表 # or关系 # ret=soup.find_all(name=['body','b']) # ret=soup.find_all(id=['id_p','link1']) # ret=soup.find_all(class_=['id_p','link1']) # and 关系 # ret=soup.find_all(class_='title',name='p') # print(ret) #4 True # 所有有名字的标签 # ret=soup.find_all(name=True) #所有有id的标签 # ret=soup.find_all(id=True) # 所有有herf属性的 # ret=soup.find_all(href=True) # print(ret) # 5 方法 # def has_class_but_no_id(tag): # return tag.has_attr('class') and not tag.has_attr('id') # # print(soup.find_all(has_class_but_no_id)) # 6 其他使用 # ret=soup.find_all(attrs={'class':"title"}) # ret=soup.find_all(attrs={'id':"id_p1",'class':'title'}) # print(ret) # 7 拿到标签,取属性,取text # ret=soup.find_all(attrs={'id':"id_p",'class':'title'}) # print(ret[0].text) # 8 limit(限制条数) # soup.find() 就是find_all limit=1 # ret=soup.find_all(name=True,limit=2) # print(len(ret)) # 9 recursive # recursive=False (只找儿子)不递归查找,只找第一层 # ret=soup.body.find_all(name='p',recursive=False) # print(ret)
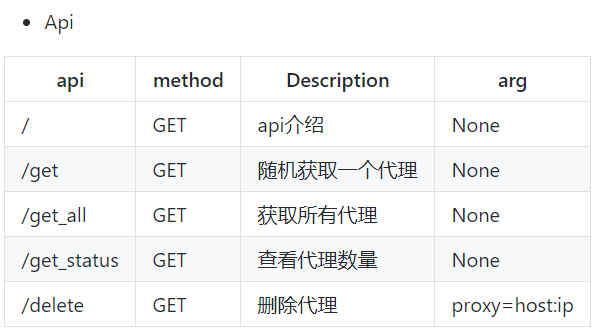
# https://github.com/jhao104/proxy_pool # 收费的:提供给你一个接口,每掉一次这个接口,获得一个代理 # 免费:用爬虫爬取,免费代理,放到我的库中,flask,django搭一个服务(删除代理,自动测试代理可用性),每次发一个请求,获取一个代理 # 带你配置 # 1 下载,解压,用pycharm打开 # 2 安装依赖 pip install -r requirements.txt # 3 配置Config/setting.py: DB_TYPE = getenv('db_type', 'redis').upper() DB_HOST = getenv('db_host', '127.0.0.1') DB_PORT = getenv('db_port', 6379) DB_PASSWORD = getenv('db_password', '') # 配置 API服务 SERVER_API = { "HOST": "127.0.0.1", # 监听ip, 0.0.0.0 监听所有IP "PORT": 5010 # 监听端口 } # 上面配置启动后,代理池访问地址为 http://127.0.0.1:5010 # 4 本地启动redis-server # 5 可以在cli目录下通过ProxyPool.py -python proxyPool.py schedule :调度程序,他会取自动爬取免费代理 -python proxyPool.py webserver:启动api服务,把flask启动起来 # 根据接口即可获得代理 http://127.0.0.1:5010/get/ # 随机获取一个代理 http://127.0.0.1:5010/get_all/ # 获取所有代理
# 1 简单验证码,字母,数字 # 2 高级的,选择,你好,12306选择乒乓球,滑动验证(极验) # 打码平台(自动破解验证码,需要花钱)云打码,超级鹰(12306) http://www.yundama.com/ http://www.chaojiying.com/ # 注册账号,(充钱)把demo下载下来,运行即可
超级鹰测试代码
import requests from hashlib import md5 class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json() if __name__ == '__main__': chaojiying = Chaojiying_Client('30633XXXX', 'lqzxxx', '903641') # 用户中心>>软件ID 生成一个替换 96001 im = open('a.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要// print(chaojiying.PostPic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
##### # 1 爬取糗事百科,微信自动发送 ##### # https://www.qiushibaike.com/text/ # https://www.qiushibaike.com/text/page/1/ import requests from bs4 import BeautifulSoup ret=requests.get('https://www.qiushibaike.com/text/page/1/') # print(ret.text) ll=[] soup=BeautifulSoup(ret.text,"lxml") article_list=soup.find_all(name='div',id=True,class_='article') for article in article_list: content=article.find(name='div',class_='content').span.text # content=article.find(name='div',class_='content').text # content=article.find(class_='content').text # print(content) # 入库 #我们放到列表中 ll.append(content) print(ll) # 微信自动发消息 # 参考 https://www.cnblogs.com/liuqingzheng/articles/9079192.html # wxpy:实现了web微信的接口 # pip3 install wxpy from wxpy import * # 实例化得到一个对象,微信机器人对象 import random bot=Bot(cache_path=True) @bot.register() # 接收从指定好友发来的消息,发送者即recv_msg.sender为指定好友,此处为回复所有发来消息的好友 def recv_send_msg(recv_msg): print('收到的消息:',recv_msg.text) # recv_msg.text取得文本 return random.choice(ll) embed() # 会生成wxpy.pkl的pkl文件,该文件是序列化文件,把所有好友签名信息的数据持久化到文件中,可反序列化读出

爬取(拉钩职位, cnblogs新闻, 红楼梦小说写入txt, 肯德基餐厅信息)
## 6 爬取拉钩职位 ## 7 爬取cnblogs新闻 ## 8 爬取红楼梦小说写入txt ``` http://www.shicimingju.com/book/hongloumeng.html ``` ## 9 爬取糗事百科段子,自动通过微信发给女朋友(老板) ## 10 肯德基餐厅信息 http://www.kfc.com.cn/kfccda/storelist/index.aspx
# 1 爬拉钩职位信息 # import requests # # headers = { # 'Accept-Language': "zh-CN,zh;q=0.9", # 'Host': 'www.lagou.com', # 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36", # 'Referer': "https://www.lagou.com/jobs/list_python?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=", # 'Cookie': "_ga=GA1.2.1497342262.1582512706; user_trace_token=20200224105145-cc6cf3ff-ce98-45e4-987a-b86e8c600c0a; LGUID=20200224105145-b49fd29f-44e3-4e76-99b1-81d214d196c6; _gid=GA1.2.1855310676.1586229731; JSESSIONID=ABAAAECAAFDAAEH3E452981BE6E4D71C27858CD16B95E47; WEBTJ-ID=20200407223352-171550fd3077e1-099a2b39121da1-396f7f07-1764000-171550fd309d5c; X_MIDDLE_TOKEN=4541125f78b04f020d1ab29fee30c15f; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221709905d08a239-0d00b368bd6473-39697407-1764000-1709905d08b9bd%22%2C%22%24device_id%22%3A%221709905d08a239-0d00b368bd6473-39697407-1764000-1709905d08b9bd%22%2C%22props%22%3A%7B%22%24os%22%3A%22MacOS%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2280.0.3987.149%22%2C%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; index_location_city=%E4%B8%8A%E6%B5%B7; PRE_UTM=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; LGSID=20200408152358-9c69660c-a345-498a-8034-10252ffe3e1b; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DtVZflBXEaVsOXF%5FjFHCfFYOeqdRD4HXjo5Hn4EMTkmG%26ck%3D9551.3.94.252.155.241.150.180%26shh%3Dwww.baidu.com%26sht%3Dbaiduhome%5Fpg%26wd%3D%26eqid%3Df1483e950008cf70000000045e8d7c0b; TG-TRACK-CODE=index_search; _gat=1; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1586229731,1586270033,1586330638,1586332101; SEARCH_ID=42fc072280a0477c92659467a1ad8b00; X_HTTP_TOKEN=dde9d3565777ba88401233685139c3c6eb8d6e4588; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1586332105; LGRID=20200408154824-69c24f2c-ed0d-40aa-acbc-1df8cfac23d1", # 'Accept': "application/json, text/javascript, */*; q=0.01", # 'X-Anit-Forge-Code': "0", # 'X-Anit-Forge-Token': None, # 'X-Requested-With': 'XMLHttpRequest' # # } # form_data = { # 'first': 'false', # 'pn': 1, # 'kd': 'python' # } # ret=requests.post('https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false', # headers=headers,data=form_data) # print(ret.text) # 2 爬cnblogs新闻 # import requests # from bs4 import BeautifulSoup # ret=requests.get('https://www.cnblogs.com/sitehome/p/3') # soup=BeautifulSoup(ret.text,'lxml') # # article_list=soup.find_all(class_='post_item') # for article in article_list: # title=article.find(class_='titlelnk').text # href=article.find(class_='titlelnk')['href'] # desc=article.find(class_='post_item_summary').text # author=article.find(class_='lightblue').text # print(''' # 文章标题:%s # 文章地址:%s # 文章摘要:%s # 文章作者:%s # '''%(title,href,desc,author)) # 爬红楼梦小说 # import requests # from bs4 import BeautifulSoup # ret=requests.get('http://www.shicimingju.com/book/hongloumeng.html') # soup=BeautifulSoup(ret.text,'lxml') # # li_list=soup.find(class_='book-mulu').find_all(name='li') # with open("红楼.txt",'w') as f: # for li in li_list: # title=li.find(name='a').text # url=li.find(name='a')['href'] # # print(title) # f.write(title+' ') # ret_detail=requests.get('http://www.shicimingju.com'+url) # soup2=BeautifulSoup(ret_detail.text,'lxml') # content=soup2.find(class_='chapter_content').text # f.write(content+' ') # print(title,"写入") # 微信机器人 # from wxpy import * # from pyecharts import Pie # import webbrowser # bot=Bot(cache_path=True) #注意手机确认登录 # # friends=bot.friends() # #拿到所有朋友对象,放到列表里 # attr=['男朋友','女朋友','未知性别'] # value=[0,0,0] # for friend in friends: # if friend.sex == 1: # 等于1代表男性 # value[0]+=1 # elif friend.sex == 2: #等于2代表女性 # value[1]+=1 # else: # value[2]+=1 # # # pie = Pie("朋友男女比例") # pie.add("", attr, value, is_label_show=True) # #图表名称str,属性名称list,属性所对应的值list,is_label_show是否现在标签 # pie.render('sex.html')#生成html页面 # # 打开浏览器 # webbrowser.open("sex.html") # from wxpy import * # bot=Bot(cache_path=True) # # @bot.register() # def recv_send_msg(recv_msg): # print('收到的消息:',recv_msg.text) # recv_msg.text取得文本 # return '好的' # # # 进入Python命令行,让程序保持运行 # embed() # 爬糗事百科 # import requests # from bs4 import BeautifulSoup # ret=requests.get('https://www.qiushibaike.com/text/page/2/') # # print(ret.text) # # soup=BeautifulSoup(ret.text,'lxml') # # article_list=soup.find_all(class_='article') # # print(article_list) # for article in article_list: # content=article.find(class_='content').text # print(content) # print('-------') # 爬肯德基门店 # import requests # # header = { # 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' # } # data = { # 'cname': '', # 'pid': 20, # 'keyword': '浦东', # 'pageIndex': 1, # 'pageSize': 10 # } # ret = requests.post('http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword', data=data, headers=header) # print(ret.text)
爬取博客园写入mysql
import requests import pymysql from bs4 import BeautifulSoup conn=pymysql.Connect(host='127.0.0.1', user='root', password="123",database="article") cursor=conn.cursor() ret=requests.get('https://www.cnblogs.com/sitehome/p/3') soup=BeautifulSoup(ret.text,'lxml') article_list=soup.find_all(class_='post_item') for article in article_list: title=article.find(class_='titlelnk').text href=article.find(class_='titlelnk')['href'] desc=article.find(class_='post_item_summary').text author=article.find(class_='lightblue').text print(''' 文章标题:%s 文章地址:%s 文章摘要:%s 文章作者:%s '''%(title,href,desc,author)) # desc为关键字,需要加`` sql="insert into at (title,arthor,url,`desc`) values ('%s','%s','%s','%s')"%(title,author,href,desc) cursor.execute(sql) conn.commit() cursor.close() conn.close()
总结:
# 1 requests+beautifulsoup4,汽车之家(find(name="li")) -汽车资讯类的搜索引擎 # 2 bs4的简单使用:在html/xml中查找元素的模块(查找,修改) # 3 遍历文档树 . 只能找到一个(速度快) # 4 获取属性(Tag对象.attrs['href'])(Tag对象['href']) # 5 text,string,strings # 6 获取标签名字,子孙,父亲,兄弟 # 7 查找文档树:find和find_all (limit) # 8 5种过滤器:字符串,列表,true,正则,方法 -find_all(name="字符串",href="字符串",id='',class_="字符串") -find_all(attrs={'name':'字符串'}) # 9 糗事百科,拉钩,cnblogs文章 # 10 反扒:头信息,ua,referer,当前时间 time.time(), -请求体中设置加密的东西:xxx:(id+时间戳+xxx)加密算法加密 js:加密算法 -杏树林:app+(前后端分离,后端写一堆接口:json格式) -抓包工具 # 11 自动化运维平台项目: 资产收集, 监控类, 一条命令自动安装:3,4 mysql5.7(ansiable),修改mysql配置文件
类来调用对象的绑定方法,这个方法就是一个普通函数
psutil模块介绍
psutil是一个跨平台库(http://pythonhosted.org/psutil/)能够轻松实现获取系统运行的进程和系统利用率(包括CPU、内存、磁盘、网络等)信息。它主要用来做系统监控,性能分析,进程管理。它实现了同等命令行工具提供的功能,如ps、top、lsof、netstat、ifconfig、who、df、kill、free、nice、ionice、iostat、iotop、uptime、pidof、tty、taskset、pmap等。目前支持32位和64位的Linux、Windows、OS X、FreeBSD和Sun Solaris等操作系统.