简介
ZooKeeper是一个分布式应用程序协调服务,主要用于解决分布式集群中应用系统的一致性问题。它能提供类似文件系统的目录节点树方式的数据存储,主要用途是维护和监控所存数据的状态变化,以实现对集群的管理。
ZooKeeper应用场景:
- 统一命名
- 配置管理
- 集群管理
- 共享锁
- 队列管理
基本架构
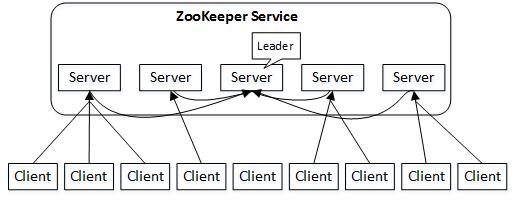
Zookeeper集群中角色介绍:
- Leader:Leader不直接接受client的请求,但接受由其他Follower和Observer转发过来的Client请求,此外,Leader还负责投票的发起和决议,即时更新状态和数据。
- Follower:Follower角色接受客户端请求并返回结果,参与Leader发起的投票和选举,但不具有写操作的权限。
- Observer:Observer角色接受客户端连接,将写操作转给Leader,但Observer不参与投票(即不参加一致性协议的达成),只同步Leader节点的状态,Observer角色是为集群系统扩展而生的。
数据模型(树形结构)
Zookeeper的数据节点称为ZNode,ZNode是Zookeeper中数据的最小单元,每个ZNode都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,称为树。
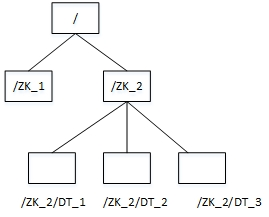
Znode的主要特点如下:
(1) Znode中仅存储与同步相关的数据,因此数据量很小,大概B到KB量级,例如状态信息、配置内容、位置信息等。
(2) 一个Znode维护一个状态结构,包括:版本号、ACL(访问控制列表)变更、时间戳。Znode存储的数据每次发生变化,版本号都会递增,这样客户端就可以基于版本号检索相关数据。
(3) 每个Znode都有一个ACL,用来限定该Znode可以被何种请求访问。 客户端可以在Znode上设置一个观察者(Watcher),如果该Znode上的数据发生变更,ZooKeeper就会通知客户端,从而触发观察者中实现的逻辑的执行。
节点类型
ZooKeeper中节点主要有四种类型:
- 持久节点(PERSISTENT)
- 持久顺序节点( PERSISTENT _SEQUENTIAL)
- 临时节点(EPHEMERAL)
- 临时顺序节点( EPHEMERAL _SEQUENTIAL )
读写流程
写流程
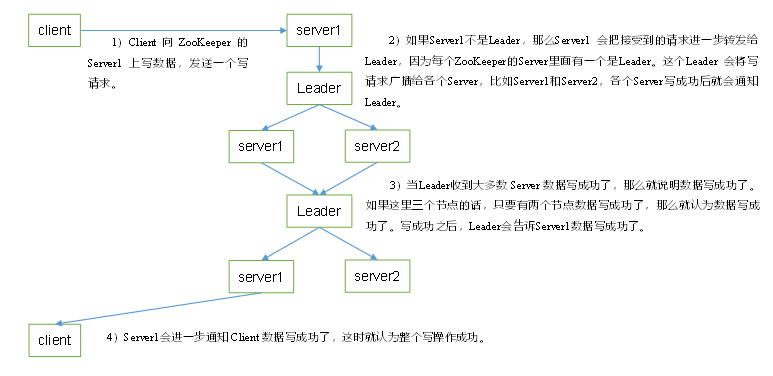
- 客户端连接到集群中某一个节点,发送一个写请求;
- 服务端与客户端所连接的节点,把该写请求转发给leader;
- leader处理写请求,等待follower节点返回;
- 当leader接收到一半以上的节点(包括自己)返回写成功的信息之后,返回给客户端成功写入。
读流程
- 客户端连接到集群中某一节点;
- 读请求,直接返回。