SQL Server中解决死锁的新方法介绍
数据库操作的死锁是不可避免的,本文并不打算讨论死锁如何产生,重点在于解决死锁,通过SQL Server 2005, 现在似乎有了一种新的解决办法。
将下面的SQL语句放在两个不同的连接里面,并且在5秒内同时执行,将会发生死锁。
|
SQL Server对付死锁的办法是牺牲掉其中的一个,抛出异常,并且回滚事务。在SQL Server 2000,语句一旦发生异常,T-SQL将不会继续运行,上面被牺牲的连接中, print @#end tran@#语句将不会被运行,所以我们很难在SQL Server 2000的T-SQL中对死锁进行进一步的处理。
现在不同了,SQL Server 2005可以在T-SQL中对异常进行捕获,这样就给我们提供了一条处理死锁的途径:
下面利用的try ... catch来解决死锁。
|
解决
但是现在又面临一个新的问题: 错误被掩盖了,一但问题发生并且超过3次,异常却不会被抛出。SQL Server 2005 有一个RaiseError语句,可以抛出异常,但却不能直接抛出原来的异常,所以需要重新定义发生的错误,现在,解决方案变成了这样:
|
我希望将来SQL Server 2005能够直接抛出原有异常,比如提供一个无参数的RaiseError。
因此方案有点臃肿,但将死锁问题封装到T-SQL中有助于明确职责,
========================================================================
SQL Server2000中死锁经验总结
- 回滚,而回滚会取消事务执行的所有工作。
- 由于死锁时回滚而由应用程序重新提交。
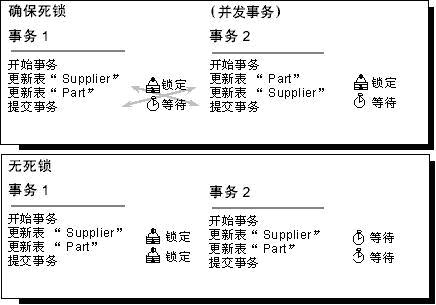
- 按同一顺序访问对象。
- 避免事务中的用户交互。
- 保持事务简短并在一个批处理中。
- 使用低隔离级别。
- 使用绑定连接。
 use mastergocreate procedure sp_who_lockasbegindeclare @spid int,@bl int, @intTransactionCountOnEntry int, @intRowcount int, @intCountProperties int, @intCounter int create table #tmp_lock_who ( id int identity(1,1), spid smallint, bl smallint) IF @@ERROR<>0 RETURN @@ERROR insert into #tmp_lock_who(spid,bl) select 0 ,blocked from (select * from sysprocesses where blocked>0 ) a where not exists(select * from (select * from sysprocesses where blocked>0 ) b where a.blocked=spid) union select spid,blocked from sysprocesses where blocked>0 IF @@ERROR<>0 RETURN @@ERROR -- 找到临时表的记录数 select @intCountProperties = Count(*),@intCounter = 1 from #tmp_lock_who IF @@ERROR<>0 RETURN @@ERROR if @intCountProperties=0 select '现在没有阻塞和死锁信息' as message-- 循环开始while @intCounter <= @intCountPropertiesbegin-- 取第一条记录 select @spid = spid,@bl = bl from #tmp_lock_who where Id = @intCounter begin if @spid =0 select '引起数据库死锁的是: '+ CAST(@bl AS VARCHAR(10)) + '进程号,其执行的SQL语法如下' else select '进程号SPID:'+ CAST(@spid AS VARCHAR(10))+ '被' + '进程号SPID:'+ CAST(@bl AS VARCHAR(10)) +'阻塞,其当前进程执行的SQL语法如下' DBCC INPUTBUFFER (@bl ) end -- 循环指针下移 set @intCounter = @intCounter + 1enddrop table #tmp_lock_whoreturn 0enduse mastergoif exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[p_killspid]') and OBJECTPROPERTY(id, N'IsProcedure') = 1)drop procedure [dbo].[p_killspid]GOcreate proc p_killspid@dbname varchar(200) --要关闭进程的数据库名as declare @sql nvarchar(500) declare @spid nvarchar(20) declare #tb cursor for select spid=cast(spid as varchar(20)) from master..sysprocesses where dbid=db_id(@dbname) open #tb fetch next from #tb into @spid while @@fetch_status=0 begin exec('kill '+@spid) fetch next from #tb into @spid end close #tb deallocate #tbgo--用法 exec p_killspid 'newdbpy'--查看锁信息create table #t(req_spid int,obj_name sysname)declare @s nvarchar(4000) ,@rid int,@dbname sysname,@id int,@objname sysnamedeclare tb cursor for select distinct req_spid,dbname=db_name(rsc_dbid),rsc_objid from master..syslockinfo where rsc_type in(4,5)open tbfetch next from tb into @rid,@dbname,@idwhile @@fetch_status=0begin set @s='select @objname=name from ['+@dbname+']..sysobjects where id=@id' exec sp_executesql @s,N'@objname sysname out,@id int',@objname out,@id insert into #t values(@rid,@objname) fetch next from tb into @rid,@dbname,@idendclose tbdeallocate tbselect 进程id=a.req_spid ,数据库=db_name(rsc_dbid) ,类型=case rsc_type when 1 then 'NULL 资源(未使用)' when 2 then '数据库' when 3 then '文件' when 4 then '索引' when 5 then '表' when 6 then '页' when 7 then '键' when 8 then '扩展盘区' when 9 then 'RID(行 ID)' when 10 then '应用程序' end ,对象id=rsc_objid ,对象名=b.obj_name ,rsc_indid from master..syslockinfo a left join #t b on a.req_spid=b.req_spidgodrop table #t
use mastergocreate procedure sp_who_lockasbegindeclare @spid int,@bl int, @intTransactionCountOnEntry int, @intRowcount int, @intCountProperties int, @intCounter int create table #tmp_lock_who ( id int identity(1,1), spid smallint, bl smallint) IF @@ERROR<>0 RETURN @@ERROR insert into #tmp_lock_who(spid,bl) select 0 ,blocked from (select * from sysprocesses where blocked>0 ) a where not exists(select * from (select * from sysprocesses where blocked>0 ) b where a.blocked=spid) union select spid,blocked from sysprocesses where blocked>0 IF @@ERROR<>0 RETURN @@ERROR -- 找到临时表的记录数 select @intCountProperties = Count(*),@intCounter = 1 from #tmp_lock_who IF @@ERROR<>0 RETURN @@ERROR if @intCountProperties=0 select '现在没有阻塞和死锁信息' as message-- 循环开始while @intCounter <= @intCountPropertiesbegin-- 取第一条记录 select @spid = spid,@bl = bl from #tmp_lock_who where Id = @intCounter begin if @spid =0 select '引起数据库死锁的是: '+ CAST(@bl AS VARCHAR(10)) + '进程号,其执行的SQL语法如下' else select '进程号SPID:'+ CAST(@spid AS VARCHAR(10))+ '被' + '进程号SPID:'+ CAST(@bl AS VARCHAR(10)) +'阻塞,其当前进程执行的SQL语法如下' DBCC INPUTBUFFER (@bl ) end -- 循环指针下移 set @intCounter = @intCounter + 1enddrop table #tmp_lock_whoreturn 0enduse mastergoif exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[p_killspid]') and OBJECTPROPERTY(id, N'IsProcedure') = 1)drop procedure [dbo].[p_killspid]GOcreate proc p_killspid@dbname varchar(200) --要关闭进程的数据库名as declare @sql nvarchar(500) declare @spid nvarchar(20) declare #tb cursor for select spid=cast(spid as varchar(20)) from master..sysprocesses where dbid=db_id(@dbname) open #tb fetch next from #tb into @spid while @@fetch_status=0 begin exec('kill '+@spid) fetch next from #tb into @spid end close #tb deallocate #tbgo--用法 exec p_killspid 'newdbpy'--查看锁信息create table #t(req_spid int,obj_name sysname)declare @s nvarchar(4000) ,@rid int,@dbname sysname,@id int,@objname sysnamedeclare tb cursor for select distinct req_spid,dbname=db_name(rsc_dbid),rsc_objid from master..syslockinfo where rsc_type in(4,5)open tbfetch next from tb into @rid,@dbname,@idwhile @@fetch_status=0begin set @s='select @objname=name from ['+@dbname+']..sysobjects where id=@id' exec sp_executesql @s,N'@objname sysname out,@id int',@objname out,@id insert into #t values(@rid,@objname) fetch next from tb into @rid,@dbname,@idendclose tbdeallocate tbselect 进程id=a.req_spid ,数据库=db_name(rsc_dbid) ,类型=case rsc_type when 1 then 'NULL 资源(未使用)' when 2 then '数据库' when 3 then '文件' when 4 then '索引' when 5 then '表' when 6 then '页' when 7 then '键' when 8 then '扩展盘区' when 9 then 'RID(行 ID)' when 10 then '应用程序' end ,对象id=rsc_objid ,对象名=b.obj_name ,rsc_indid from master..syslockinfo a left join #t b on a.req_spid=b.req_spidgodrop table #t设定跟踪1204:
USE MASTER
DBCC TRACEON (1204,-1)
显示当前启用的所有跟踪标记的状态:
DBCC TRACESTATUS(-1)
取消跟踪1204:
DBCC TRACEOFF (1204,-1)
在设定跟踪1204后,会在数据库的日志文件里显示SQL Server数据库死锁时一些信息。但那些信息很难看懂,需要对照SQL Server联机丛书仔细来看。根据PAG锁要找到相关数据库表的方法:
DBCC TRACEON (3604)
DBCC PAGE (db_id,file_id,page_no)
DBCC TRACEOFF (3604)
请参考sqlservercentral.com上更详细的讲解.但又从CSDN学到了一个找到死锁原因的方法。我稍加修改, 去掉了游标操作并增加了一些提示信息,写了一个系统存储过程sp_who_lock.sql。代码如下:
if exists (select * from dbo.sysobjects
where id = object_id(N'[dbo].[sp_who_lock]')
and OBJECTPROPERTY(id, N'IsProcedure') = 1)
drop procedure [dbo].[sp_who_lock]
GO
/********************************************************
// 学习到并改写
// 说明 : 查看数据库里阻塞和死锁情况
********************************************************/
use master
go
create procedure sp_who_lock
as
begin
declare @spid int,@bl int,
@intTransactionCountOnEntry int,
@intRowcount int,
@intCountProperties int,
@intCounter int
create table #tmp_lock_who (
id int identity(1,1),
spid smallint,
bl smallint)
IF @@ERROR<>0 RETURN @@ERROR
insert into #tmp_lock_who(spid,bl) select 0 ,blocked
from (select * from sysprocesses where blocked>0 ) a
where not exists(select * from (select * from sysprocesses
where blocked>0 ) b
where a.blocked=spid)
union select spid,blocked from sysprocesses where blocked>0
IF @@ERROR<>0 RETURN @@ERROR
-- 找到临时表的记录数
select @intCountProperties = Count(*),@intCounter = 1
from #tmp_lock_who
IF @@ERROR<>0 RETURN @@ERROR
if @intCountProperties=0
select '现在没有阻塞和死锁信息' as message
-- 循环开始
while @intCounter <= @intCountProperties
begin
-- 取第一条记录
select @spid = spid,@bl = bl
from #tmp_lock_who where Id = @intCounter
begin
if @spid =0
select '引起数据库死锁的是: '+ CAST(@bl AS VARCHAR(10))
+ '进程号,其执行的SQL语法如下'
else
select '进程号SPID:'+ CAST(@spid AS VARCHAR(10))+ '被'
+ '进程号SPID:'+ CAST(@bl AS VARCHAR(10)) +'阻塞,其当前进程执行的SQL语法如下'
DBCC INPUTBUFFER (@bl )
end
-- 循环指针下移
set @intCounter = @intCounter + 1
end
drop table #tmp_lock_who
return 0
end
需要的时候直接调用:
sp_who_lock
就可以查出引起死锁的进程和SQL语句.
SQL Server自带的系统存储过程sp_who和sp_lock也可以用来查找阻塞和死锁, 但没有这里介绍的方法好用。如果想知道其它tracenum参数的含义,请看http://www.sqlservercentral.com/文章
我们还可以设置锁的超时时间(单位是毫秒), 来缩短死锁可能影响的时间范围:
例如:
use master
seelct @@lock_timeout
set lock_timeout 900000
-- 15分钟
seelct @@lock_timeout
其实所有的死锁最深层的原因就是一个:资源竞争
表现一:
一个用户A 访问表A(锁住了表A),然后又访问表B
另一个用户B 访问表B(锁住了表B),然后企图访问表A
这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B,才能继续,好了他老人家就只好老老实实在这等了
同样用户B要等用户A释放表A才能继续这就死锁了
解决方法:
这种死锁是由于你的程序的BUG产生的,除了调整你的程序的逻辑别无他法
仔细分析你程序的逻辑,
1:尽量避免同时锁定两个资源
2: 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源.
表现二:
用户A读一条纪录,然后修改该条纪录
这是用户B修改该条纪录
这里用户A的事务里锁的性质由共享锁企图上升到独占锁(for update),而用户B里的独占锁由于A有共享锁存在所以必须等A释
放掉共享锁,而A由于B的独占锁而无法上升的独占锁也就不可能释放共享锁,于是出现了死锁。
这种死锁比较隐蔽,但其实在稍大点的项目中经常发生。
解决方法:
让用户A的事务(即先读后写类型的操作),在select 时就是用Update lock
语法如下:
select * from table1 with(updlock) where ....
如何将数据库中被锁表解锁
作者:佚名 文章来源:未知 点击数:106 更新时间:2005-12-25
我们在操作数据库的时候,有时候会由于操作不当引起数据库表被锁定,这么我们经常不知所措,不知怎么给这些表解锁,在pl/sql Developer工具的的菜单“tools”里面的“sessions”可以查询现在存在的会话,但是我们很难找到那个会话被锁定了,想找到所以被锁的会话就更难了,下面这叫查询语句可以查询出所以被锁的会话。如下:
SELECT sn.username, m.SID,sn.SERIAL#, m.TYPE,
DECODE (m.lmode,
0, 'None',
1, 'Null',
2, 'Row Share',
3, 'Row Excl.',
4, 'Share',
5, 'S/Row Excl.',
6, 'Exclusive',
lmode, LTRIM (TO_CHAR (lmode, '990'))
) lmode,
DECODE (m.request,
0, 'None',
1, 'Null',
2, 'Row Share',
3, 'Row Excl.',
4, 'Share',
5, 'S/Row Excl.',
6, 'Exclusive',
request, LTRIM (TO_CHAR (m.request, '990'))
) request,
m.id1, m.id2
FROM v$session sn, v$lock m
WHERE (sn.SID = m.SID AND m.request != 0) --存在锁请求,即被阻塞
OR ( sn.SID = m.SID --不存在锁请求,但是锁定的对象被其他会话请求锁定
AND m.request = 0
AND lmode != 4
AND (id1, id2) IN (
SELECT s.id1, s.id2
FROM v$lock s
WHERE request != 0 AND s.id1 = m.id1
AND s.id2 = m.id2)
)
ORDER BY id1, id2, m.request;
通过以上查询知道了sid和 SERIAL#就可以开杀了
alter system kill session 'sid,SERIAL#';