JAVA 8
Spring Boot 2.5.3
kafka_2.13-2.8.0
apache-zookeeper-3.7.0
---
授人以渔:
1、Spring Boot Reference Documentation
This document is also available as Multi-page HTML, Single page HTML and PDF.
有PDF版本哦,下载下来!
有PDF版本哦,下载下来!
目录
本文介绍Kafka的基本使用,包括 新建主题、发送消息、接收&处理消息、消息发送确认、消息消费确认 等。
本文基于 单机版的ZooKeeper、Kafka 进行测试。
kafka是一个分布式消息队列(MQ)中间件,支持 生产者/消费者、发布者/订阅者 模式。
由Apache软件基金会开发的一个开源流处理平台。
依赖 Apache软件基金会 的另一个开源软件:ZooKeeper(致力于开发和维护开源服务器,实现高度可靠的分布式协调)。
关键概念:
broker、producer、consumer-group、consumer,
topic、partition、replica、offset。
---
还有更多关键概念,这些一起构建了 分布式的、高可靠性的、流式处理 的 Kafka。
概念说明:
broker:运行kafka服务器的进程;
producer:生产者,发送消息到topic;
consumer-group:消息消费者的组名,用于将消费者分组;
consumer:消息消费者,归属于某个consumer-group,真正用于接收&处理消息的实体;
一个consumer-group下只有一个 consumer,这个consumer将依次消费 主题下各个partition的消息——要是partition有多个,这个consumer会“比较累”吧;
一个consumer-group下有多个 consumer,系统(?)会协调各个 consumer 匹配 主题下各个partition,要是数量相等——都是N,则可以实现并发处理主题下的消息——一个consumer对应一个partition;
consumer的数量 需要和 主题下的partition数量 协调——前者大于后者是没有必要的,会存在consumer浪费的情况;
topic:消息主题,匹配RabbitMQ中的 交换机,消息发送到主题,再由主题发送到具体的分区(partition);
partition:主题下的分区,可以1~N个,匹配RabbitMQ中的队列,但不需要和主题绑定,创建Topic的时候就建立好,在kafka的数据文件夹下,每个partition都对应一个文件夹;consumer就是从 partition中消费消息的;
replica:partition的副本,可以1~N个,但是,N的数量必须小于 集群中 broker的数量,replica会被均匀地分布到不同的broker中;
offset:partition下的概念,记录partition中消息被消费到那里了,由消费者控制——消费后不更新offset、任意指定offset开始消费(比如,从头开始);和RabbitMQ不同的时,消息被消费后,不会立即被清理,故,可以消费已经被消费过的消息;(疑问:消息会一直保留吗?消息会被清理吗?什么时候清理?策略是什么?TODO)
ZooKeeper、Kafka单机启动&停止:
单机部署
ZooKeeper
配置文件(Config file):
conf/zoo.cfg
启动(start):
./zkServer.sh start
停止(stop):
./zkServer.sh stop
Kafka
配置文件:
server.properties
启动(start):
bin/kafka-server-start.sh config/server.properties
停止(stop):
bin/kafka-server-stop.sh
注,启动前需要修改好配置文件。
注,上面的Kafka启动后,会占用一个Shell,可以使用 nohup CMD & 实现后台启动。
Kafka启动后,可以使用 bin 目录下的 kafka-topics.sh 管理主题。
kafka-topics.sh操作
# help命令
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --help
...省略...
# 展示所有Topic
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --list
__consumer_offsets
topic01
topic02
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$
# 创建主题 1个分区、1个副本——成功
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic082901 --partitions 1 --replication-factor 1 --create
Created topic topic082901.
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --list
__consumer_offsets
topic01
topic02
topic082901
# 创建主题 2个分区、1个副本——成功
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic082902 --partitions 2 --replication-factor 1 --create
Created topic topic082902.
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --list
__consumer_offsets
topic01
topic02
topic082901
topic082902
# 创建主题 1个分区、2个副本——失败!原因是 只有一个 broker——单机版,2个副本没有意义,都在一个服务器上
# 多副本需要 集群环境才可以演示
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic082903 --partitions 1 --replication-factor 2 --create
Error while executing topic command : Replication factor: 2 larger than available brokers: 1.
[2021-08-29 14:26:18,293] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1.
(kafka.admin.TopicCommand$)
# 2个副本的主题没有创建成功
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --list
__consumer_offsets
topic01
topic02
topic082901
topic082902
# 展示 主题的信息
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic082901 --describe
Topic: topic082901 TopicId: xKGttQHbSy-Ywc9Mo4e_2w PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: topic082901 Partition: 0 Leader: 1 Replicas: 1 Isr: 1
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic082902 --describe
Topic: topic082902 TopicId: cEEZFAgCSN2PDkiAArGUTQ PartitionCount: 2 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: topic082902 Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: topic082902 Partition: 1 Leader: 1 Replicas: 1 Isr: 1
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$
# 检查kafka服务器的数据目录
# 多了 3个文件夹,分别对应着各个主题的 分区
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ls -l ~/kafka/logs-1/ | grep topic
drwxrwxr-x 2 ben ben 4096 8月 29 11:45 topic01-0
drwxrwxr-x 2 ben ben 4096 8月 29 11:38 topic02-0
drwxrwxr-x 2 ben ben 4096 8月 29 11:38 topic02-1
drwxrwxr-x 2 ben ben 4096 8月 29 14:25 topic082901-0
drwxrwxr-x 2 ben ben 4096 8月 29 14:25 topic082902-0
drwxrwxr-x 2 ben ben 4096 8月 29 14:25 topic082902-1
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$
# 删除主题
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic082902 --delete
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic082901 --delete
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --list
__consumer_offsets
topic01
topic02
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$
# 删除后查看数据目录:多了3个 末尾是 delete的目录,等待若干分钟,这些文件夹会被清理掉
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ls -l ~/kafka/logs-1/ | grep topic
drwxrwxr-x 2 ben ben 4096 8月 29 11:45 topic01-0
drwxrwxr-x 2 ben ben 4096 8月 29 11:38 topic02-0
drwxrwxr-x 2 ben ben 4096 8月 29 11:38 topic02-1
drwxrwxr-x 2 ben ben 4096 8月 29 14:25 topic082901-0.be9a1e49b81a4b9a8421e52e45281f77-delete
drwxrwxr-x 2 ben ben 4096 8月 29 14:25 topic082902-0.70d6391753e24886a9dcb048db4d5811-delete
drwxrwxr-x 2 ben ben 4096 8月 29 14:25 topic082902-1.b335d0068eba494d8576937ecb7f9bb6-delete
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$Kafka基于ZooKeeper,因此,在Kafka使用过程中,ZooKeeper中的一些节点也会发生变化。
下面是 使用 ZooKeeper 的 zkCli.sh 查看到的一些信息。
zkCli.sh部分操作
ben@ben-VirtualBox:~/apache-zookeeper-3.7.0-bin/bin$ ./zkCli.sh
/usr/bin/java
Connecting to localhost:2181
...省略...
# 使用 ZooKeeper的ls命令!
[zk: localhost:2181(CONNECTED) 0] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: localhost:2181(CONNECTED) 1]
[zk: localhost:2181(CONNECTED) 1] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 2] ls /brokers/ids
[1]
[zk: localhost:2181(CONNECTED) 3] ls /brokers/seqid
[]
[zk: localhost:2181(CONNECTED) 4] ls /brokers/topics
[__consumer_offsets, topic01, topic02]
[zk: localhost:2181(CONNECTED) 5]
[zk: localhost:2181(CONNECTED) 5] ls /brokers/topics/__consumer_offsets
[partitions]
[zk: localhost:2181(CONNECTED) 6] ls /brokers/topics/__consumer_offsets/partitions
[0, 1, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3,
30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 6, 7,
8, 9]
[zk: localhost:2181(CONNECTED) 7] ls /brokers/topics/__consumer_offsets/partitions/0
[state]
[zk: localhost:2181(CONNECTED) 8] ls /brokers/topics/__consumer_offsets/partitions/0/state
[]
[zk: localhost:2181(CONNECTED) 9]
[zk: localhost:2181(CONNECTED) 9] ls /brokers/topics/topics/topic01
Node does not exist: /brokers/topics/topics/topic01
[zk: localhost:2181(CONNECTED) 10] ls /brokers/topics/topic01
[partitions]
[zk: localhost:2181(CONNECTED) 11] ls /brokers/topics/topic01/partitions
[0]
[zk: localhost:2181(CONNECTED) 12] ls /brokers/topics/topic01/partitions/0
[state]
[zk: localhost:2181(CONNECTED) 13] ls /brokers/topics/topic01/partitions/0/state
[]
[zk: localhost:2181(CONNECTED) 14]
# help可以看到所有命令
[zk: localhost:2181(CONNECTED) 14] help
ZooKeeper -server host:port -client-configuration properties-file cmd args
...生路...关于Kafka在ZooKeeper上建立了哪些节点?各个节点的意义,需要另文介绍。
在自己7月份的一篇文章中有过介绍,本文再深入一些。
依赖包:
Kafka的依赖包
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>spring-kafka包:
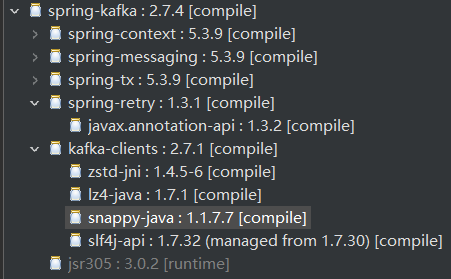
Spring容器中和 Kafka有关的一些Bean:
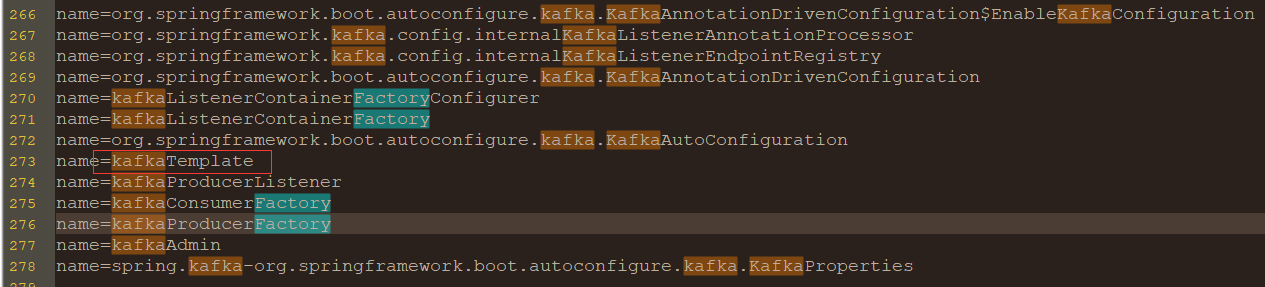
其中的 kafkaTemplate 的 多个 send函数 用来发送消息到主题 或 其下的分区:
# 部分send函数签名
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data)
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data)
public ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, @Nullable V data)
public ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, Long timestamp, K key,
@Nullable V data)
public ListenableFuture<SendResult<K, V>> send(ProducerRecord<K, V> record)
public ListenableFuture<SendResult<K, V>> send(Message<?> message)除了send,还有sendDefault函数,发送消息到默认分区,默认分区是什么?可以用 KafkaTemplate 的 getDefaultTopic() 获取。
另外,还有一些 setXXX函数,用来设置 kafkaTemplate 对象。
配置application.properties:
# Kafka
# mylinux 虚拟机地址:配置hosts文件
spring.kafka.bootstrap-servers=mylinux:9092
# consumer:全局
# 也可以在 @KafkaListener 中指定 单独的 groupId
#spring.kafka.consumer.group-id=myGroupJava文件:
接口 /try3/send 发送消息,1个@KafkaListener——消费者(注意,指定 groupId=tp03,所以,上面的配置文件中的 spring.kafka.consumer.group-id 可以不配置,否则启动不了应用)。
try3-源码1
# Try3Config.java
@Component
@Slf4j
public class Try3Config {
public static final String TOPIC_03 = "topic03";
public static final String TOPIC_03_KEY = "topic03_key";
/**
* 监听器1
* @author ben
* @date 2021-08-29 16:30:46 CST
* @param record
*/
@KafkaListener(topics = {TOPIC_03}, groupId="tp03")
public void listen01(ConsumerRecord<?, ?> record) {
// log.info("try3-消费-a:record={}", record);
log.info("try3-消费-a:topic={}, partition={}, offset={}, key=[{}], value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
}
# Try3Controller.java
@RestController
@RequestMapping(value="/try3")
@Slf4j
public class Try3Controller {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
/**
* 调用接口发送消息
* @author ben
* @date 2021-08-29 16:12:07 CST
* @return
*/
@GetMapping(value="/send")
public Boolean sendMsg() {
IntStream.rangeClosed(0, 9).forEach(i->{
log.info("sendMsg-{}", i);
String msg = String.format("Try3Controller send msg-%d @%s", i, new Date());
kafkaTemplate.send(Try3Config.TOPIC_03, Try3Config.TOPIC_03_KEY, "key-" + msg);
});
return true;
}
}启动应用,Kafka上 自动出现了 topic03:
检查K服务器
ben@ben-VirtualBox:~/kafka_2.13-2.8.0/bin$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --list
__consumer_offsets
topic01
topic02
topic03
$ ./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic03 --describe
Topic: topic03 TopicId: km2zL1MeTKiOWlhCPMx6gw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: topic03 Partition: 0 Leader: 1 Replicas: 1 Isr: 1
应用启动信息(部分):
调用/try3/send 接口,发送消息:发送、接收成功。
注意,offset的变化。
注意,发送第一条消息时,producer还有一个初始化工作,会输出更多producer相关日志。再次发送时,就没有了。(是否需要 预热?)
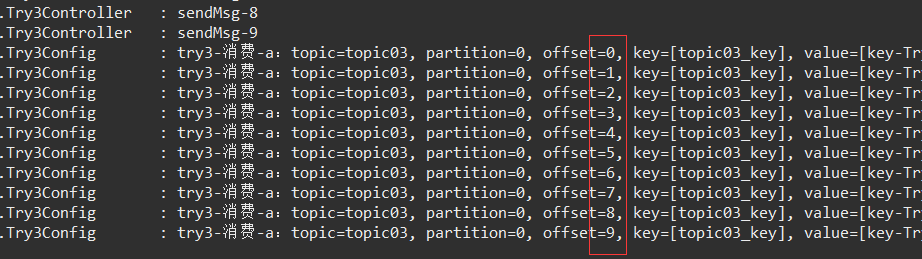
上一章试验了 1个主题1个分区1个消费者组1个消费者 的消息发送接收,本章增加1个消费者——同一个消费者组下。
Java源码:2个@KafkaListener,都在 tp03 消费者组 下
@KafkaListener(topics = {TOPIC_03}, groupId="tp03")
public void listen01(ConsumerRecord<?, ?> record) {
log.info("try3-消费-a:topic={}, partition={}, offset={}, key=[{}], value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
@KafkaListener(topics = {TOPIC_03}, groupId="tp03")
public void listen02(ConsumerRecord<?, ?> record) {
log.info("try3-消费-b:topic={}, partition={}, offset={}, key=[{}], value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}启动时,输出了更多的日志,并提示发生:
# INFO 日志,不是错误
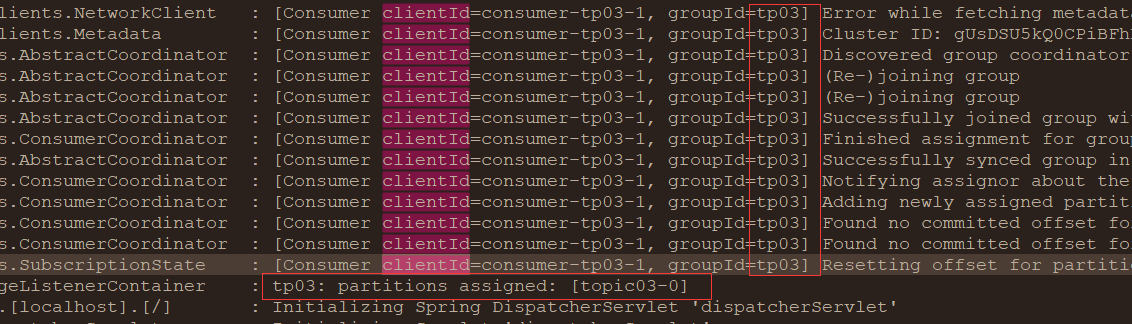
org.apache.kafka.common.errors.RebalanceInProgressException: The group is rebalancing, so a rejoin is needed.Consumer clientId 出现了两个:consumer-tp03-1、consumer-tp03-2。
并显示了 相关日志:
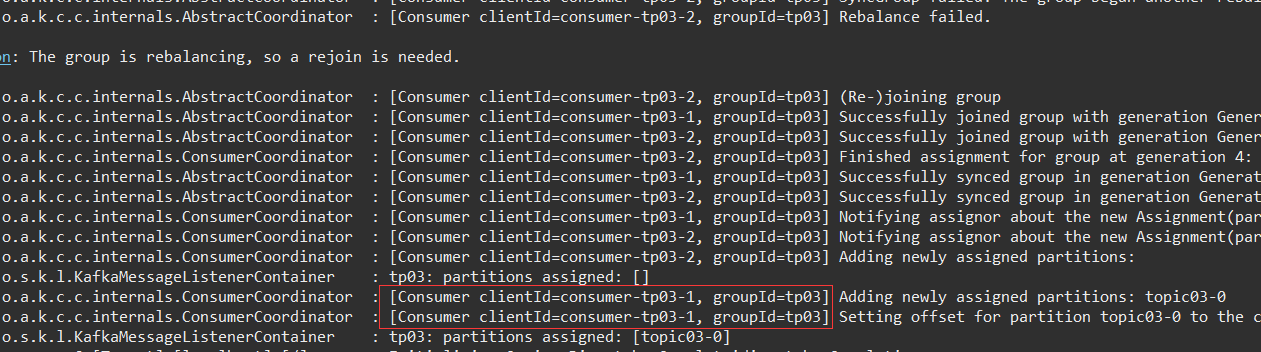
最终,consumer-tp03-1 生效了,用来消费 唯一分区的消息。
这就是 消费者数量 大于 主题的分区数量时的情况。(注意,这两个 监听器 都在同一个应用,要是在不同应用呢?稍后试验)
调用接口发送消息:
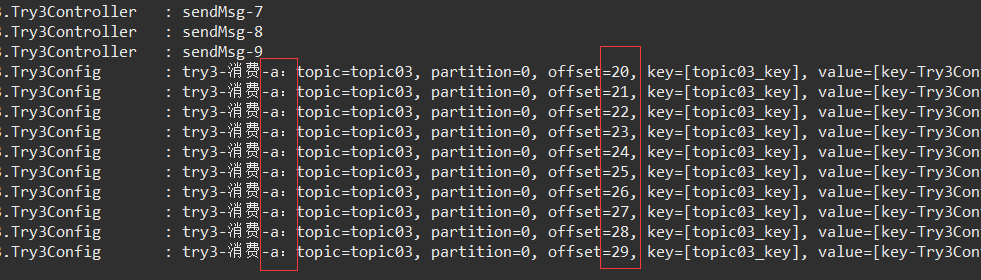
进一步试验1:
使用 另一个端口 启动应用,实现 主题的 消费者 再更加2个,看看会发生什么情况。
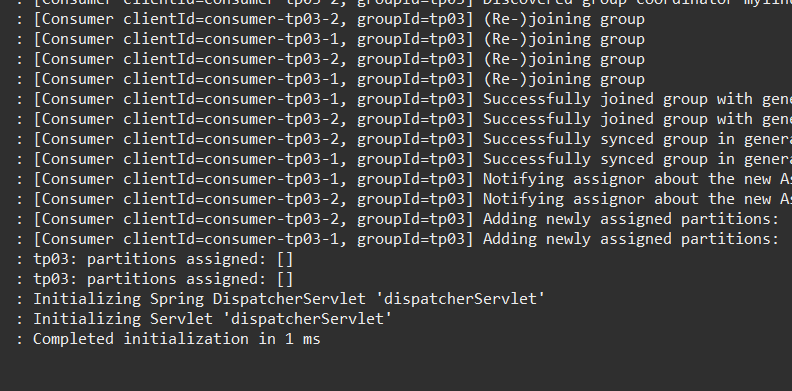
执行结果:
新启动应用的消费者 有加入消费者组,但是,没有分区分配,故,也不会收到消息处理(调用 发送消息 接口后,新应用没有收到)。
检查kafka上 消费者组tp03 的信息:
$ ./kafka-consumer-groups.sh --bootstrap-server mylinux:9092 --describe --group tp03
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
tp03 topic03 0 40 40 0 consumer-tp03-1-0705883f-92ab-47f0-82c3-d7334ad81b4f /192.168.0.112 consumer-tp03-1进一步试验2:
关闭处于消费状态的应用,检查 新启动的应用是否能 作为备用消费者 正确进行消费。
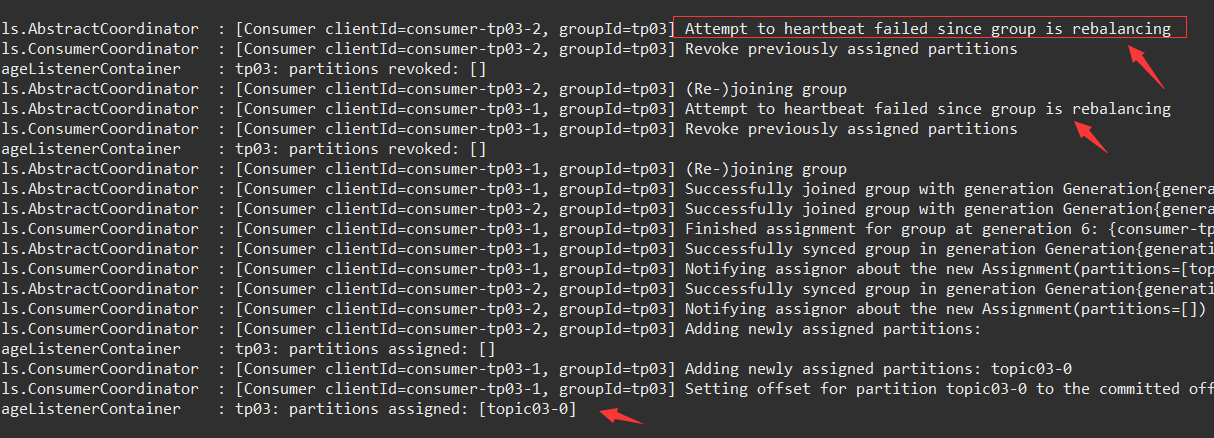
消费者组 下发生了 rebalancing!
此时,调用新应用的接口发送消息(旧端口的应用 被关闭了哦),发送成功,,新端口的应用也收到并正确处理了消息。

消费者组tp03 的信息 也发生了变化:CONSUMER-ID 不同了!
$ ./kafka-consumer-groups.sh --bootstrap-server mylinux:9092 --describe --group tp03
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
tp03 topic03 0 50 50 0 consumer-tp03-1-a682c694-8018-43a9-8a1e-02a7d5ece6a5 /192.168.0.112 consumer-tp03-1小结:
同一个组中,消费者数量 要小于 主题的分区数,多了的消费者也不会得到分区并发生消费。
但是,属于不同进程的 消费者 可以实现备用。
前面应用启动后,生成了主题,但这个主题只有1个分区。
下面使用 Kafka命令生成 2个分区 的主题:
./kafka-topics.sh --bootstrap-server mylinux:9092 --topic topic02 --partitions 2 --replication-factor 1 --create疑问:使用Java程序是否可以生成分区呢?发现一个名为 org.apache.kafka.clients.admin.NewTopic 的类,或许可以实现,后面试验下。
1组1消(1个消费者组、1个消费者)
1、发送时 无key
kafkaTemplate.send(Try2Config.TOPIC_02, "no key-" + msg);启动应用:一个监听器 处理 2个分区的数据
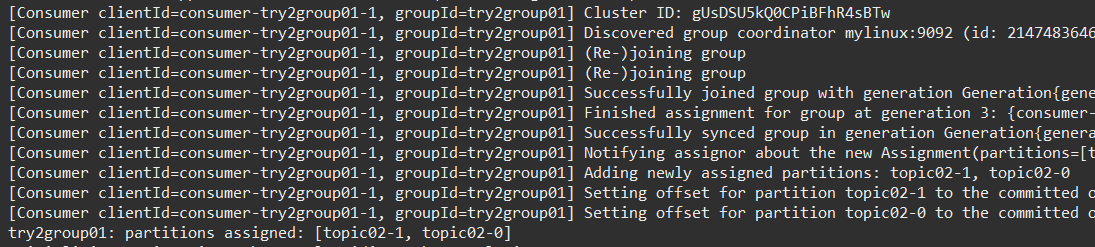
调用接口 /try2/send,结果:
第一次发送,全部到了 分区0,收到并处理:
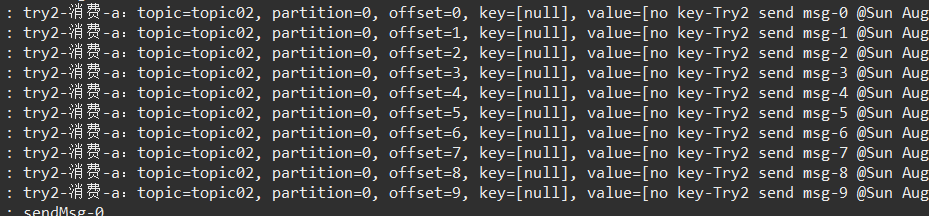
还以为 这种模式下 只会处理一个分区的数据:无key,只转发到某个分区。
那么,再次测试几次发送:
两个分区都有数据来了!
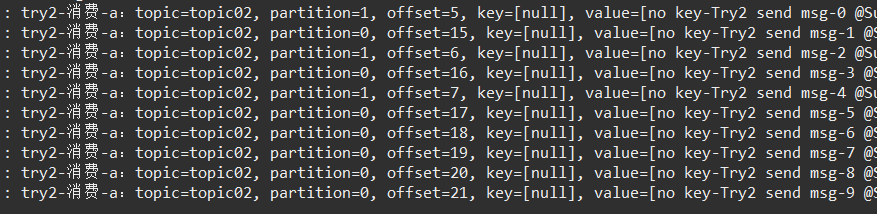
疑问:
主题的消息 在 无key的情况下,是按照什么 策略 转发到不同分区的呢?TODO
2、发送时有1个固定key
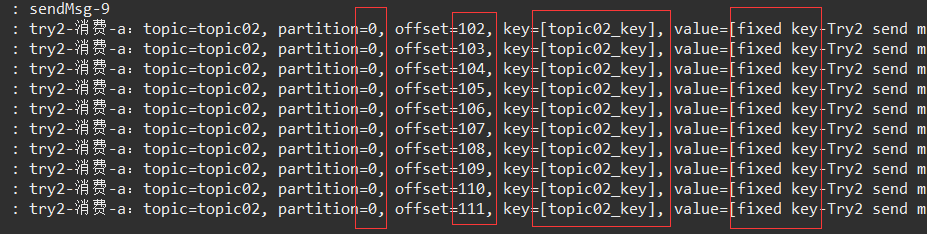
kafkaTemplate.send(Try2Config.TOPIC_02, Try2Config.TOPIC_02_KEY, "fixed key-" + msg);试验结果:
和上面的不同!监听器 只处理了来自 分区0 的消息,连续发送了多次都是如此。
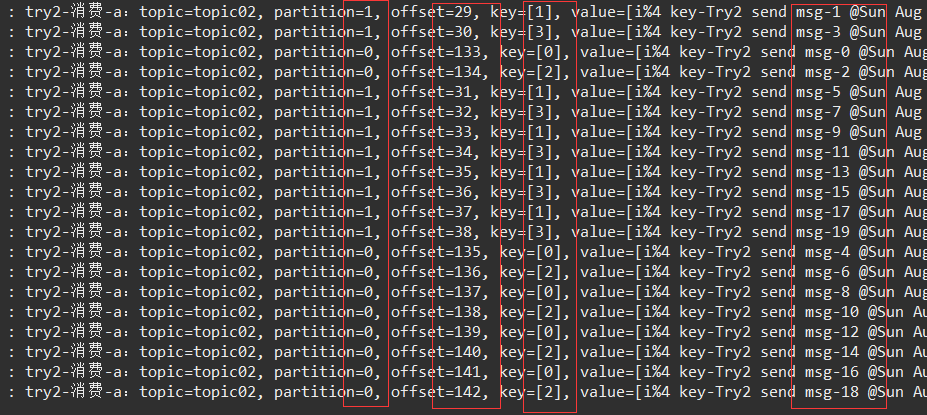
3、key为 i%4,发送20条消息(前面是10条)
// 3.发送消息条数改为 20条,key=i%4
// 注意,第二个参数是 String类型!!
kafkaTemplate.send(Try2Config.TOPIC_02, "" + i%4, "i%4 key-" + msg);试验结果:
发送了20条消息,分别均匀地转发到了 两个分区,监听器也处理了所有20消息。
不过,20条消息 没有按照 发送顺序处理,但是,同一个分区内 是 按照发送顺序处理了,0、2、4、..……,1、3、5……
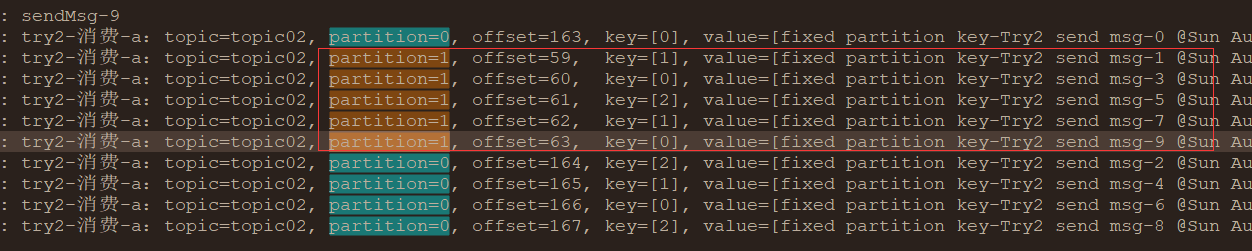
4、指定分区编号(从0开始,本试验只有0、1)发送
// 4、指定分区发送
// 第三个参数为 key = "" + i%3
kafkaTemplate.send(Try2Config.TOPIC_02, i%Try2Config.TOPIC_02_P_NUMBER, "" + i%3, "fixed partition key-" + msg);试验结果:
消息按照 指定的分区号 发送到了 不同的分区,消费者也对不同分区的消息进行了消费。
确定性地分配到不同分区的方式,而不像 按照key 转发时,存在不确定性。
发送时指定分区号,这需要提前知道 主题有多少分区,否则,指定的分区号大于分区数会怎样呢?程序卡住,最后超时发生异常!
// 错误:指定的 分区号 大于 分区数!
kafkaTemplate.send(Try2Config.TOPIC_02, i%3, "" + i%3, "fixed partition key-" + msg);如下所示:
Exception thrown when sending a message with key='2' and payload='fixed partition key-...' to topic topic02 and partition 2:
org.apache.kafka.common.errors.TimeoutException: Topic topic02 not present in metadata after 60000 ms.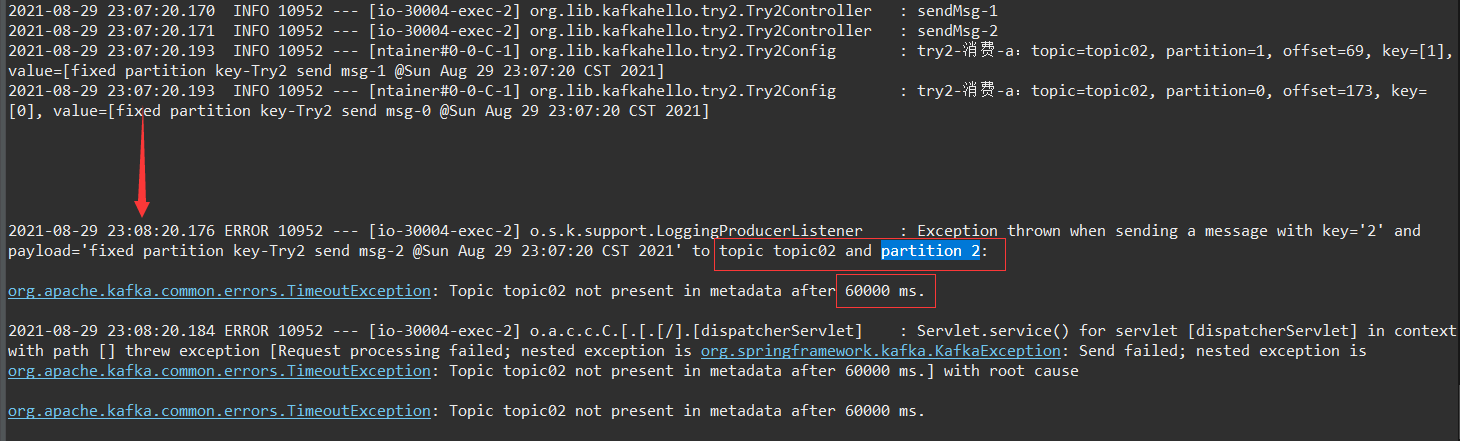
疑问:
这个发送超时时间怎么 更改 呢?Spring boot、kafka的文档中、KafkaTemplate、DefaultKafkaProducerFactory 中都没有找到 发送超时 的设置方法。TODO
注,还有一个普通的 send函数——指定了 timestamp,就不做试验了。
小结:
通过上面的试验,知道了 不同方式发送的消息 会怎么分配到不同的分区了。
| send(String topic, @Nullable V data) | key=null | 不均匀地发送到 各个分区 |
| send(String topic, K key, @Nullable V data) | key=固定值 | 只会发送到一个分区 |
| send(String topic, K key, @Nullable V data) | key=随机值 |
会均匀地发送到各个分区, 当然,随机值的数量要多于分区数量 |
| send(String topic, Integer partition, K key, @Nullable V data) | 指定分区数 |
当然是发送到指定分区。 异常: 指定分区号 大于 分区数,会超时、异常,发送消息失败。 |
| send(String topic, Integer partition, Long timestamp, K key, @Nullable V data) |
指定分区数 |
同上一个(本文未验证)。 这里的 timestamp 应该有其它用处,比如,消息去重等 |
1组2消
发送方式采用:不指定分区号,随机key——大于等于分区数2,,确保两个分区都有消息(均衡)。来自博客园

每个消费者都分配给了一个分区。
发送消息:
kafkaTemplate.send(Try2Config.TOPIC_02, "" + i%4, "i%4 key-" + msg);1组2消代码
@Component
@Slf4j
public class Try2Config {
/**
* 主题02:topic02,拥有2个分区
*/
public static final String TOPIC_02 = "topic02";
/**
* 主题topic02分区数:2
*/
public static final int TOPIC_02_P_NUMBER = 2;
/**
* 主题02-KEY:topic02_key
*/
public static final String TOPIC_02_KEY = "topic02_key";
public static final String TRY2_GROUP_ID_01 = "try2group01";
public static final String TRY2_GROUP_ID_02 = "try2group02";
@KafkaListener(topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_01)
public void listenTopic1(ConsumerRecord<?, ?> record) {
log.info("try2-消费-A:topic={}, partition={}, offset={}, key=[{}], timestamp={}, value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.timestamp(), record.value());
}
@KafkaListener(topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_01)
public void listenTopic2(ConsumerRecord<?, ?> record) {
log.info("try2-消费-B:topic={}, partition={}, offset={}, key=[{}], timestamp={}, value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.timestamp(), record.value());
}
}试验结果:两个消费者,分别处理了 指定分区的消息。来自博客园

1组3消
增加一个监听器:
// 消费者3:超过分区数量了
@KafkaListener(topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_01)
public void listenTopic3(ConsumerRecord<?, ?> record) {
log.info("try2-消费-C:topic={}, partition={}, offset={}, key=[{}], timestamp={}, value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.timestamp(), record.value());
}启动应用:来自博客园
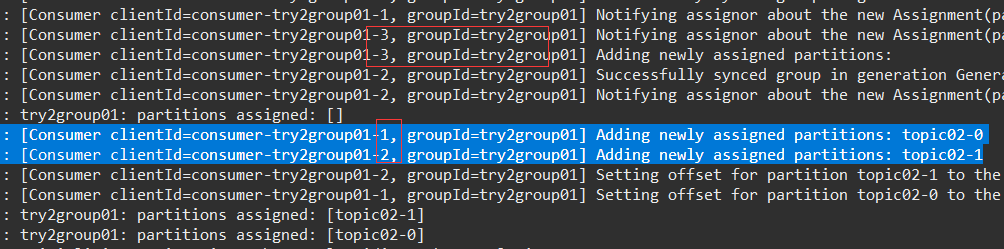
发送消息,试验结果:

两个分区的消息都得到了处理。
但是,try2group01-1、try2group01-2 指定了分区,为何 消费的是 try2-消费-C 呢?难道 这个 try2group01-N 和 日志里面的 A、B、C不匹配?
给 @KafkaListener 增加 id属性:
@KafkaListener(id="listenerA", topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_01)
@KafkaListener(id="listenerB", topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_01)
@KafkaListener(id="listenerC", topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_01)再次测试:
![]()
果然,listenerA 对应的是 consumer-try2group01-3!
2组2X2消
两个消费者组,各有两个消费者:来自博客园
2组2消监听者
// groupId = TRY2_GROUP_ID_01
// 消费者1
@KafkaListener(id="listenerA", topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_01)
public void listenTopic1(ConsumerRecord<?, ?> record) {
log.info("try2-消费-A:topic={}, partition={}, offset={}, key=[{}], timestamp={}, value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.timestamp(), record.value());
}
// groupId = TRY2_GROUP_ID_01
// 消费者2
@KafkaListener(id="listenerB", topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_01)
public void listenTopic2(ConsumerRecord<?, ?> record) {
log.info("try2-消费-B:topic={}, partition={}, offset={}, key=[{}], timestamp={}, value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.timestamp(), record.value());
}
// ---------------------
// groupId = TRY2_GROUP_ID_02
// 消费者4
@KafkaListener(id="g2listenerH", topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_02)
public void listenTopic4(ConsumerRecord<?, ?> record) {
log.info("try2-消费-H:topic={}, partition={}, offset={}, key=[{}], timestamp={}, value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.timestamp(), record.value());
}
// groupId = TRY2_GROUP_ID_02
// 消费者5
@KafkaListener(id="g2listenerJ", topics = {TOPIC_02}, groupId = TRY2_GROUP_ID_02)
public void listenTopic5(ConsumerRecord<?, ?> record) {
log.info("try2-消费-I:topic={}, partition={}, offset={}, key=[{}], timestamp={}, value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.timestamp(), record.value());
}启动应用:ListenerA、B、H、J 都分别指派给了 主题的两个分区。
注意:TRY2_GROUP_ID_02 的两个消费者的ID 是以 g2 开头的,但是,日志里面的线程名中 却没有 g2!TODO
![]()
发送消息,消费结果:

小结:
两个消费者组 都消费了 所有消息。来自博客园
注意:上面的 @KafkaListener 指定消费的 topic 使用的是 主题全名,其另一个属性 topicPattern 应该是可以用来 根据 某种模式来配置 监听的主题的。
源码里面:the topic pattern or expression (SpEL)。TODO
SpELl:
SpEL(Spring Expression Language),即Spring表达式语言,是比JSP的EL更强大的一种表达式语言。来自博客园
不甚了解,后续再DIG。
注意:@KafkaListener 的 topicPartitions属性 的使用!TODO
注意:同一个应用中,@KafkaListener 的 id不能重复,否则,启动异常。
注意:@KafkaListener 除了上面的用在方法上,还可用在类上——@Target({ ElementType.TYPE, ElementType.METHOD, ElementType.ANNOTATION_TYPE }),未用过。
注意:除了 @KafkaListener ,还有一个包含它的 @KafkaListeners,未用过。
主题:topic01,1个分区
消费者:1个
调用send函数,发送了消息,但是,消息是否发送成功了呢?网络、服务器故障等,都可能导致消息丢失,而 发送方却没有对 发送是否成功进行检查。来自博客园
send函数时有返回值的:
ListenableFuture<SendResult<K, V>>
// 继承了 Future接口
public interface ListenableFuture<T> extends Future<T> {
}Future接口 的 函数 get() 可以获取 返回消息 SendResult对象,然后,进行判断(同步方式)。
ListenableFuture<SendResult<String, Object>> sendRetFuture = kafkaTemplate.send(Try1Config.TOPIC_01, msg);
// 1、发送同步确认
// 发生异常时,不终止,继续执行下一个发送
// 发送消息确认:发送失败时怎么处理?停止继续发送、延迟后再发送?
boolean sendErr = false;
try {
SendResult<String, Object> sendRet = sendRetFuture.get();
RecordMetadata rmd = sendRet.getRecordMetadata();
if (rmd != null) {
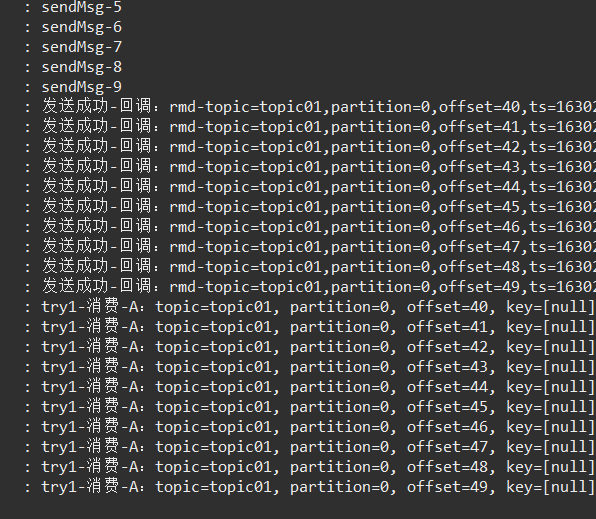
log.info("发送成功:rmd-topic={},partition={},offset={},ts={}",
rmd.topic(), rmd.partition(), rmd.offset(), rmd.timestamp());
} else {
log.error("发送失败:topic={}, msg={}", Try1Config.TOPIC_01, msg);
}
} catch (InterruptedException | ExecutionException e) {
log.error("发生异常:发送失败,e={}", e);
sendErr = true;
}
if (sendErr) {
// 发生异常,休眠30秒
// 发送时,断掉服务器的网络,或停掉kafka,这里的30秒就有操作空间了
try {
TimeUnit.SECONDS.sleep(30);
} catch (InterruptedException e) {
log.error("发生异常:sleep-30secs, e={}", e);
}
}
// 2、发送异步确认
// sendRetFuture.addCallback(new ListenableFutureCallback<SendResult<String,Object>>() {发送成功时,可以通过 get到的 SendResult对象 获取 消息在服务器上的信息:

发送失败时,get到的 SendResult对象 为null。
注,
应用启动后,把kafka关掉,想测试 发送失败 的,但是,应用一直打印服务器连接的错误日志,没有测试出 发送失败 的情况,并 捕获异常。来自博客园
那么,怎么测试发送失败的情况呢?TODO
除了上面的同步方式,还有一种异步确认方式:
send函数的返回值 ListenableFuture 可以添加回调函数。
ListenableFuture<SendResult<String, Object>> sendRetFuture = kafkaTemplate.send(Try1Config.TOPIC_01, msg);
// 1、发送同步确认
// ...省略...
// 2、发送异步确认
sendRetFuture.addCallback(new ListenableFutureCallback<SendResult<String,Object>>() {
@Override
public void onSuccess(SendResult<String,Object> result) {
RecordMetadata rmd = result.getRecordMetadata();
log.info("发送成功-回调:rmd-topic={},partition={},offset={},ts={}",
rmd.topic(), rmd.partition(), rmd.offset(), rmd.timestamp());
}
@Override
public void onFailure(Throwable ex) {
log.info("发送失败-回调:ex={}", ex);
}
});结果:
主题:topic01,1个分区
消费者:1个
前面的试验,消费消息后都自动确认了,offset也在逐个增加。来自博客园
怎么实现手动确认?
全局配置:
## 全局 手动确认
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.listener.ack-mode=MANUAL确认消息,需要参数 Acknowledgment ack,消费者示例如下:来自博客园
@KafkaListener(id="listenerA",topics = {TOPIC_01}, groupId = TOPIC_01_G01)
public void listener01(ConsumerRecord<?, ?> record, Acknowledgment ack) {
log.info("try1-消费-A:topic={}, partition={}, offset={}, key=[{}], value=[{}]",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
// 消息确认
// 配置手动确认后,若不执行下面的语句,启动后还会消费
ack.acknowledge();
}发送消息,消费消息。执行了 ack.acknowledge() 后,消息被消费&确认了。

意外情况:
配置了全局消费者手动确认消息,但是,却没有执行 消息确认,此时,分区的offset是不会改变的,消费没有确认被消费成功。
再次启动应用,消息会被再次消费。
要是已消费了100万条,但是,没有执行确认,下次启动应用时,这100万条要被重复消费,属于 异常!
注释掉上面的 ack.acknowledge() 可以进行验证。
org.springframework.kafka.support.Acknowledgment 是一个接口,除了 acknowledge() 函数,还有nack(...)——拒绝确认消费:来自博客园

上面是 全局消费手动确认 配置,那么,单独配置一个消费者组、一个消费者手动确认要怎么做呢?
》》》全文完《《《
后记:
花费了太多精时了。
对kafka也了解的更深入了。
可是,还有更多细节需要晓得的。
要知道,本文还没有涉及 KafkaTemplate的定制、Factory的定制,即便是 @KafkaListener 注解也并非全都清楚。
况且,只是单机版的kafka,集群版的会有什么特别的“坑”呢?
还有,Kafka架构、原理、动态扩容(增加分区、减少分区),还曾看过一篇大厂迁移kafka消息到新的系统的。
对了,发送消息时,可以 主动重复消费的。来自博客园
……
先这样吧,技术毕竟是一点一滴积累起来的嘛,
一天肯定是不行的,搞技术需要日积月累的努力。
4、