今天我们来聊聊“链表(Linked list)”这个数据结构。学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应⽤场景,那就是LRU缓存淘汰算法。
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常用的CPU缓存、数据库缓存、浏览器缓存等等。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:
- 先进先出策略FIFO(First In,First Out)、
- 最少使用策略LFU(Least Frequently Used)、
- 最近最少使用策略LRU(Least Recently Used)。
这些策略你不用死记,我打个比方你很容易就明白了。假如说,你买了很多本技术书,但有⼀天你发现,这些书太多了,太占书房空间了,
你要做个大扫除,扔掉那些书籍。那这个时候,你会选择扔掉哪些书呢?对应一下,你的选择标准是不是和上面的三种策略神似呢?
好了,回到正题,我们今天的开篇问题就是:如何⽤链表来实现LRU缓存淘汰策略呢? 带着这个问题,我们开始今天的内容
1、表和数组的区别
1、底层的存储结构看

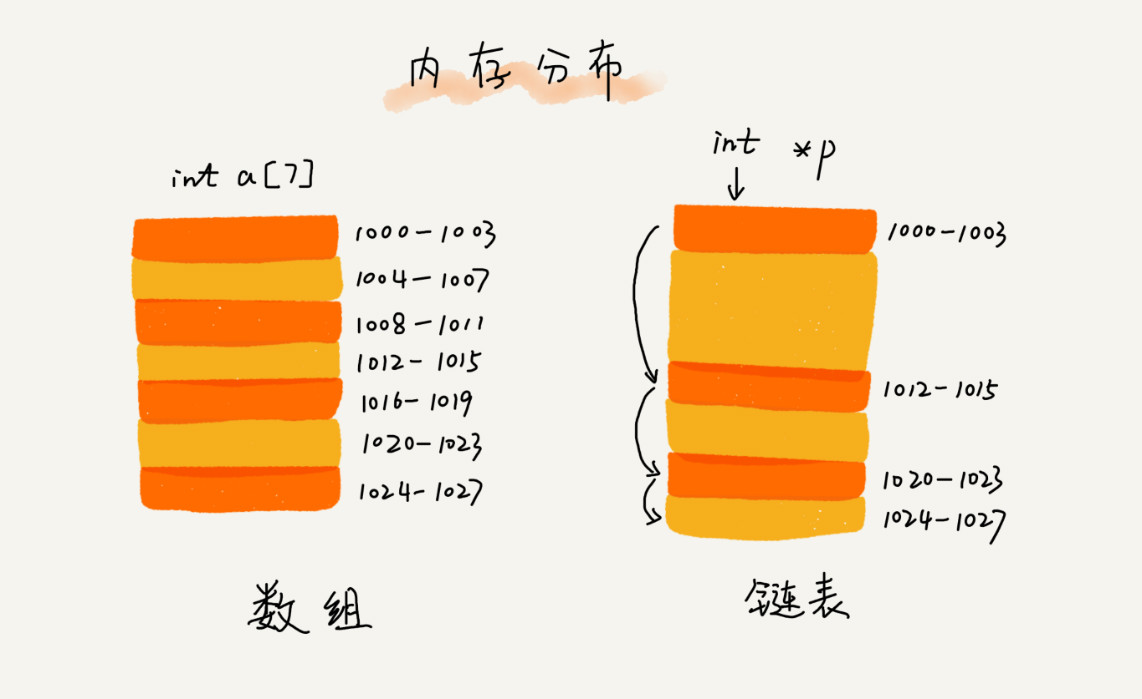
2、如果散列表中有10个数据

二、常见的链表结构
1、基本概念

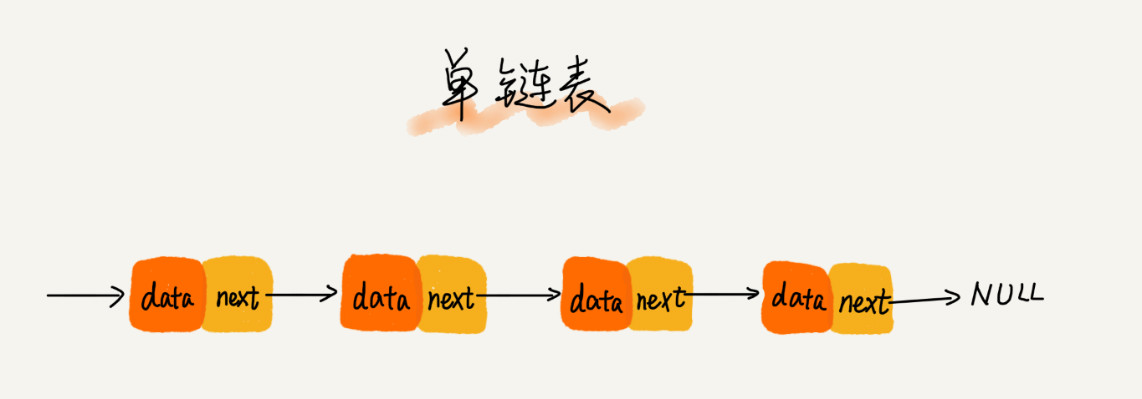
2、单链表
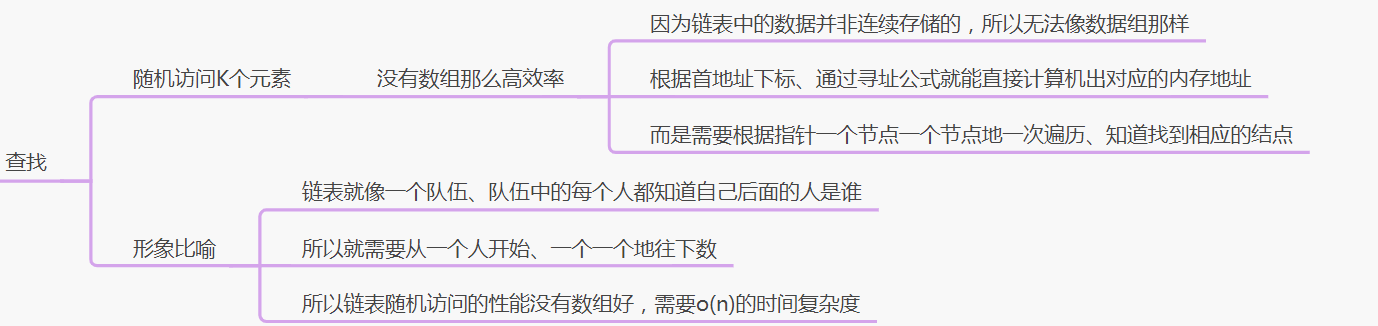
1、查找
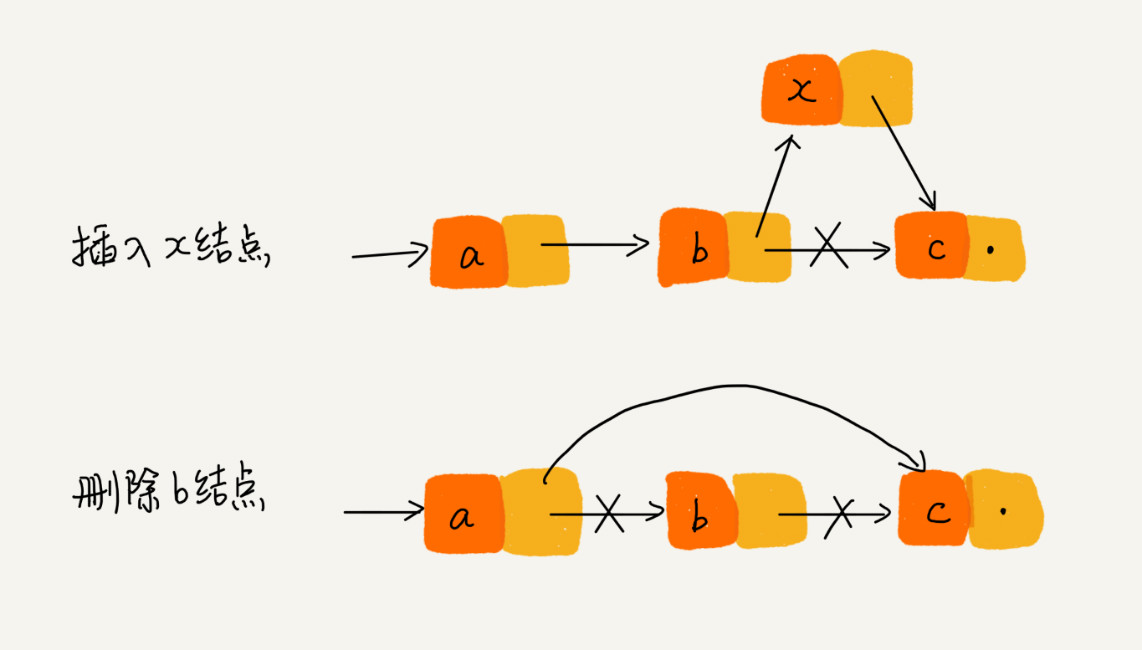
2、删除
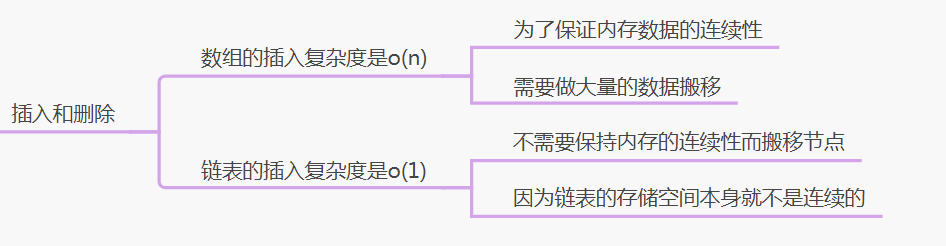
3、双向链表
1、什么是双向链表

2、单链表和双向链表存储上的区别

3、双向链表的应用场景

三、双向链表比单向链表高效
1、删除操作
1、删除结点中“值等于某个给定值”的结点

2、删除给指定指针指向的结点

3、在链表的某个指定节点前面插入一个结点

2、有序链表

3、双向链表的应用更加广泛

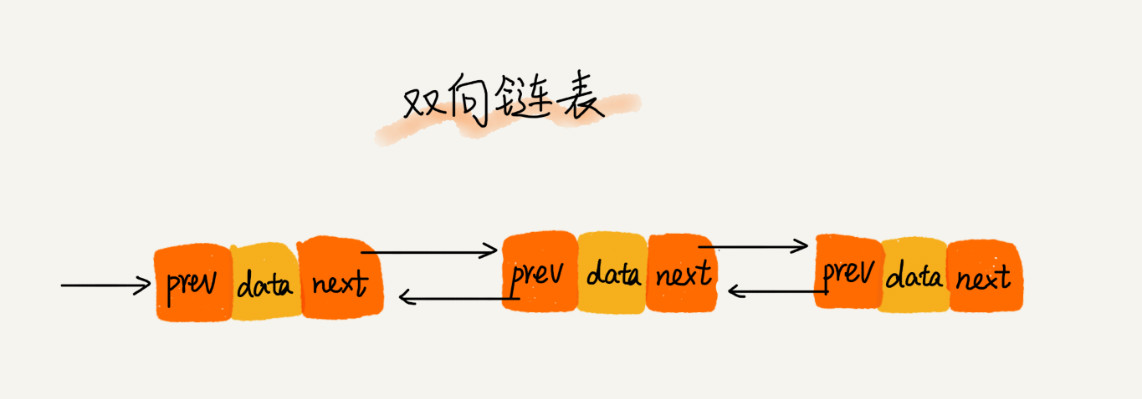
4、循环链表
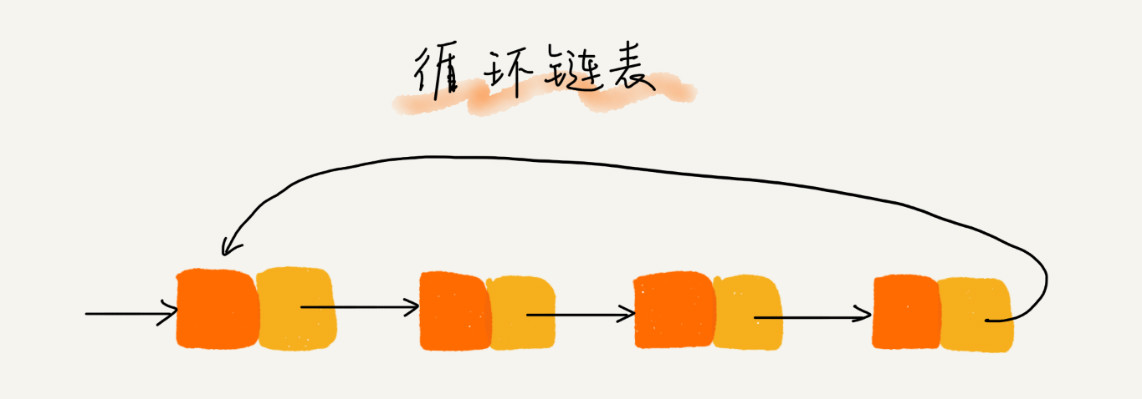

四、常见链表结构总结
1、用空间换时间

2、时间换空间

3、总结

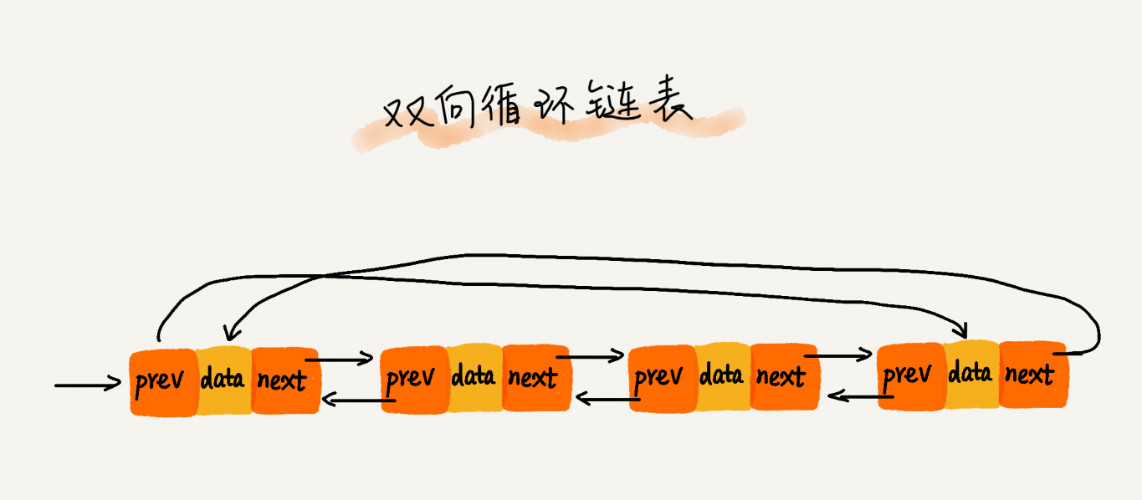
4、双向循环链表

五、链表VS数据性能大比拼
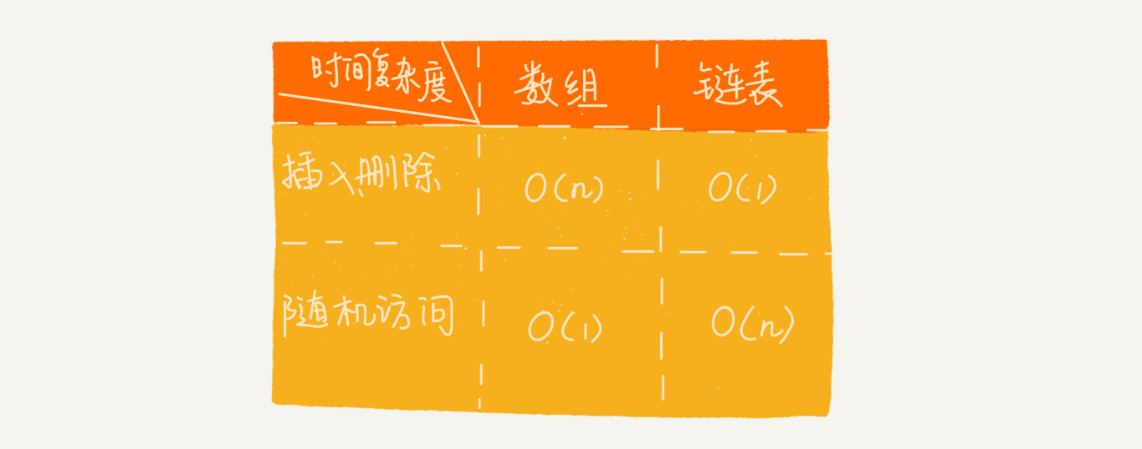
1、时间复杂度

2、数组的优点

3、数组的缺点

4、Java中的ArrayList容器

5、数组的应用场景

六、解答开篇
1、如何实现LRU缓存淘汰算法

2、现在我们来看一下m缓存的访问时间复杂度
