最近突然得知之后的工作有很多数据采集的任务,有朋友推荐webmagic这个项目,就上手玩了下。发现这个爬虫项目还是挺好用,爬取静态网站几乎不用自己写什么代码(当然是小型爬虫了~~|)。好了,废话少说,以此随笔记录一下渲染网页的爬取过程首先找到一个js渲染的网站,这里直接拿了学习文档里面给的一个网址,http://angularjs.cn/
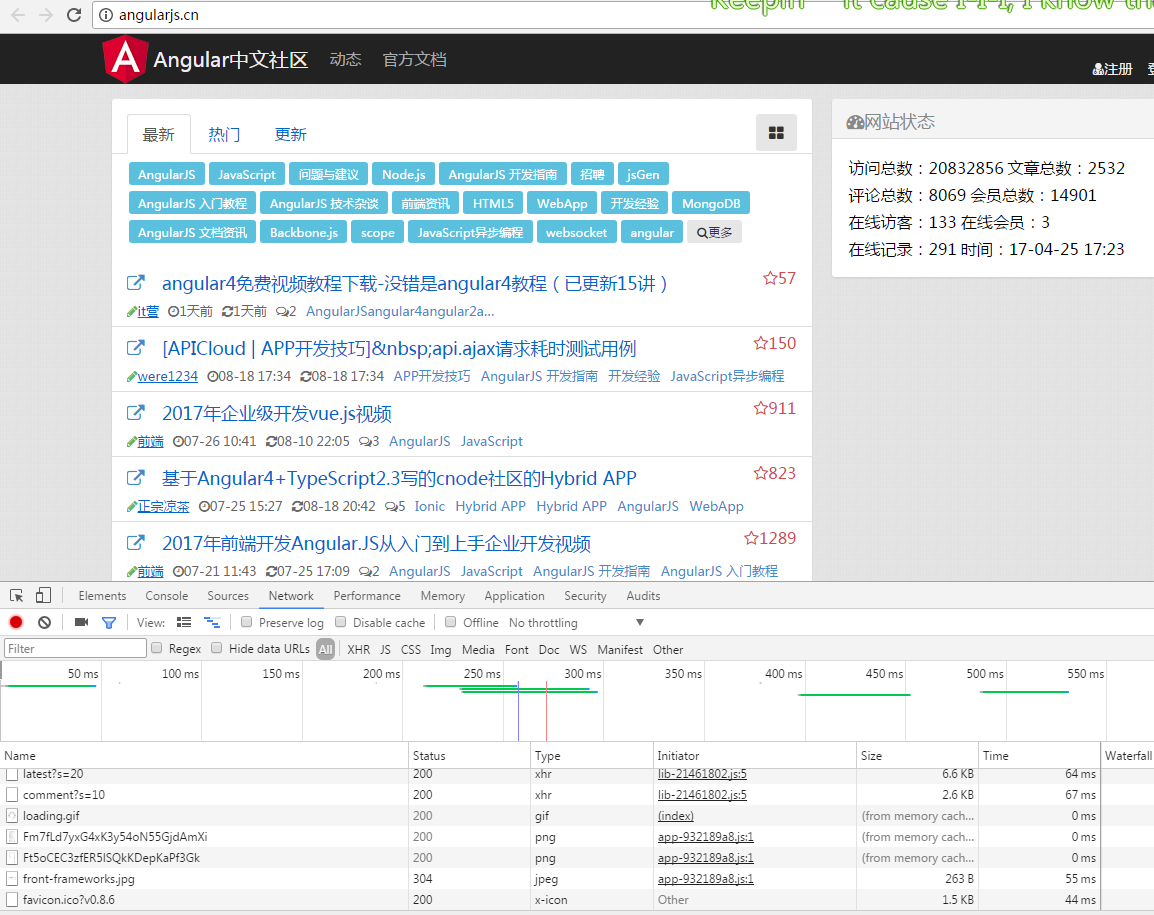
打开网页是这样的
查看源码是这样的
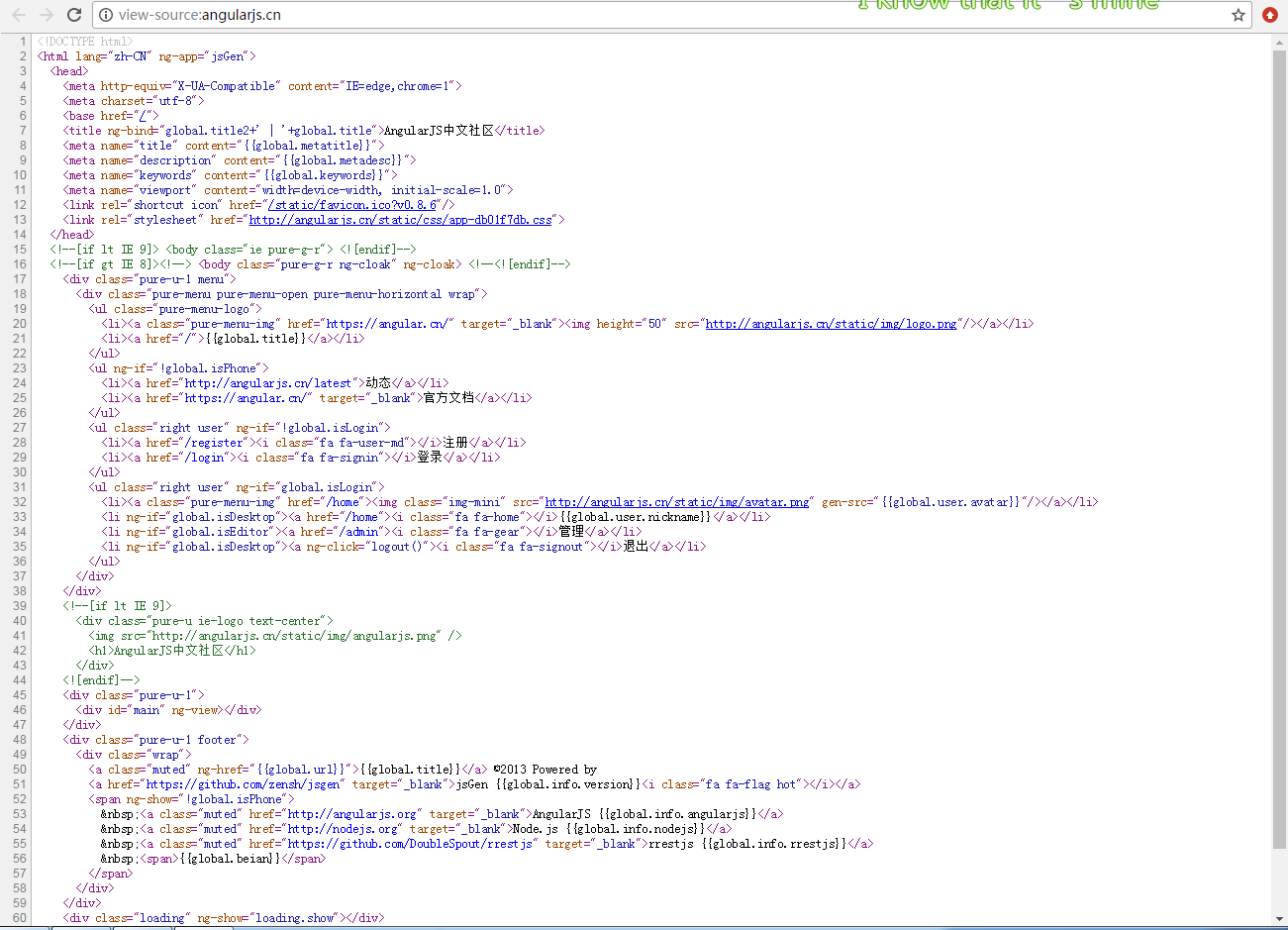
源码这么少,不用说肯定是渲染出来的了,随便搜了一条记录,果然源码里面找不到结果
那就开始解析网址了,从浏览器开发者工具里面发现了这么些请求记录
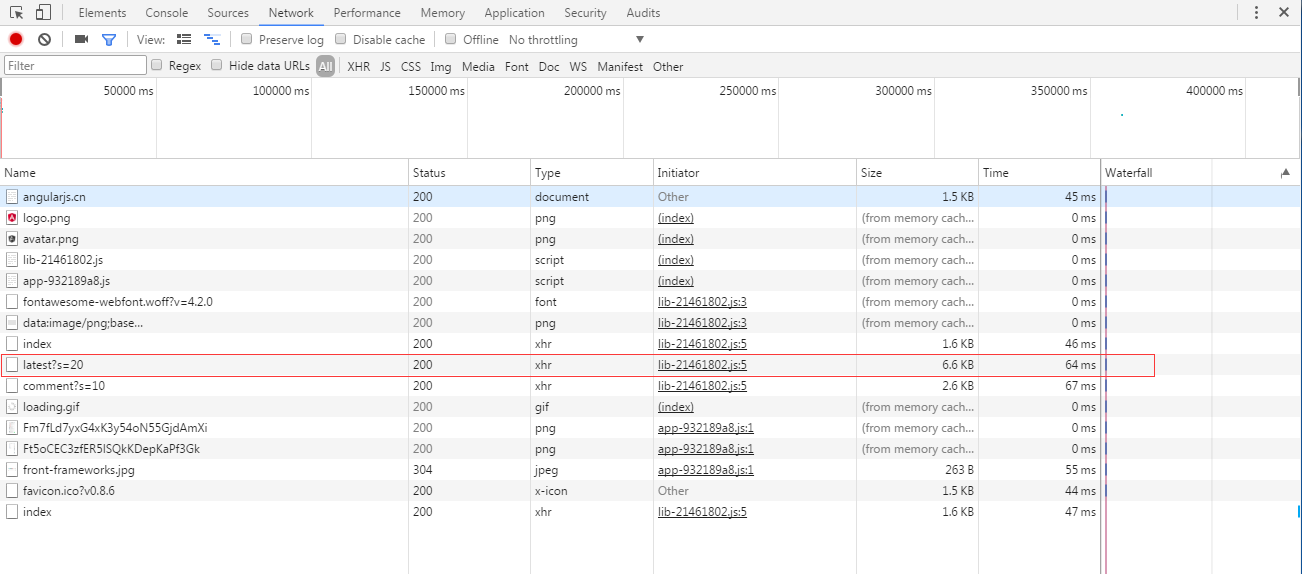
就直接从得到的数据量最大的请求开始查看,如上红线标记的。从xhr看出这是个ajax请求来的数据,打开请求的数据是这样的
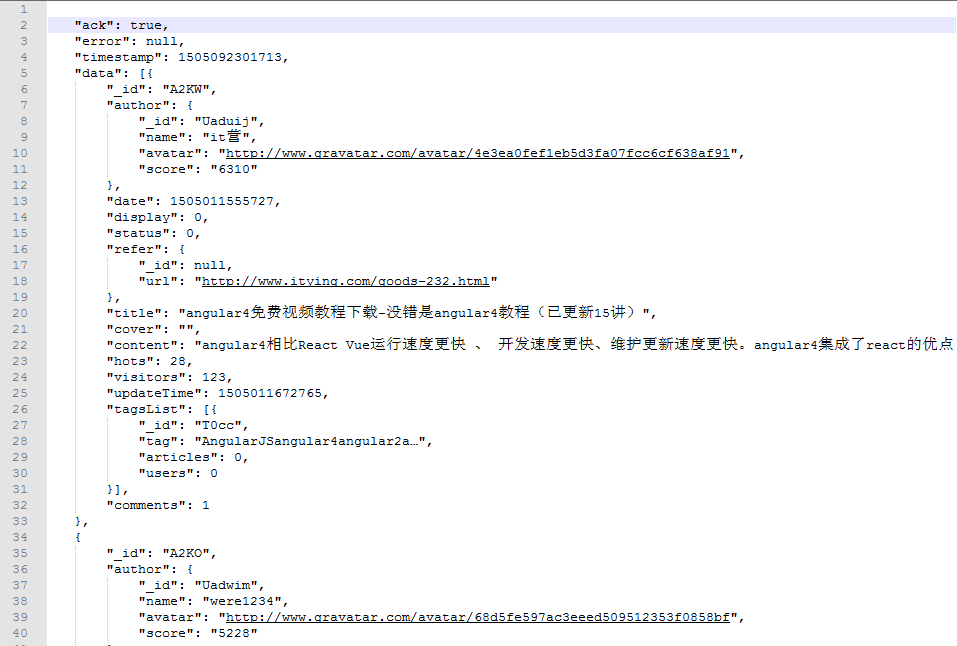
从网页上找一条源码里面找不到的记录,放在这个json数据里面搜索一下,运气还是不错的,搜索到了
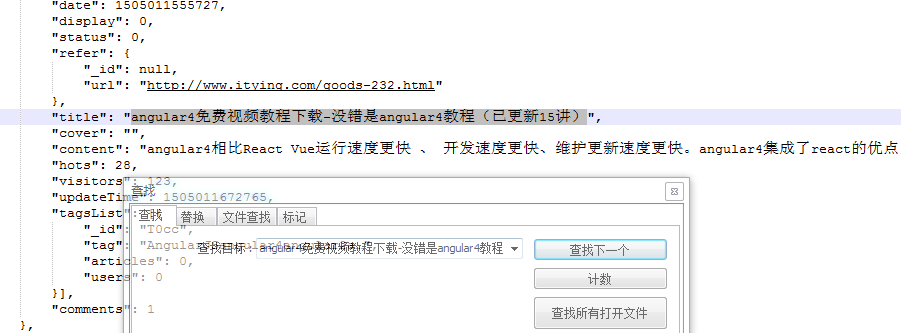
那不用说,就是它了!!接下来直接解析这个json就能拿到所有渲染后的链接了。
从网页直接点击一个链接进入,发现链接是这样的:
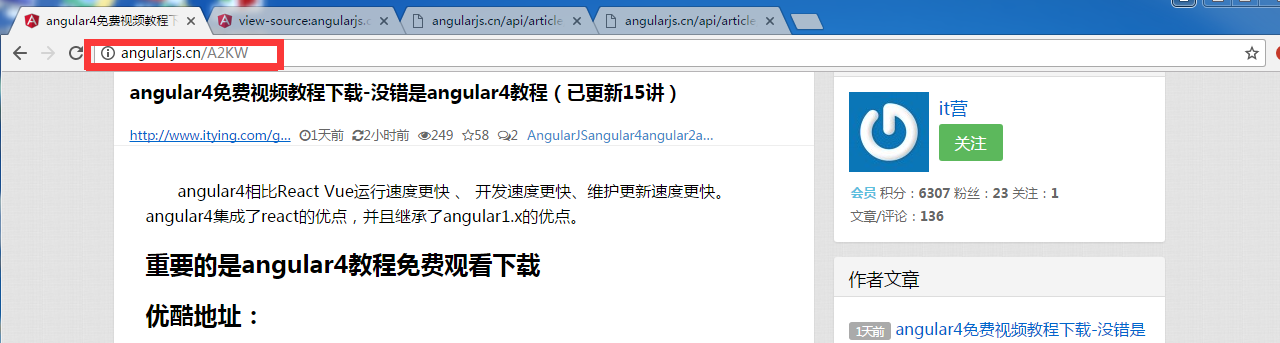
然后回到json文件,找到这个标题
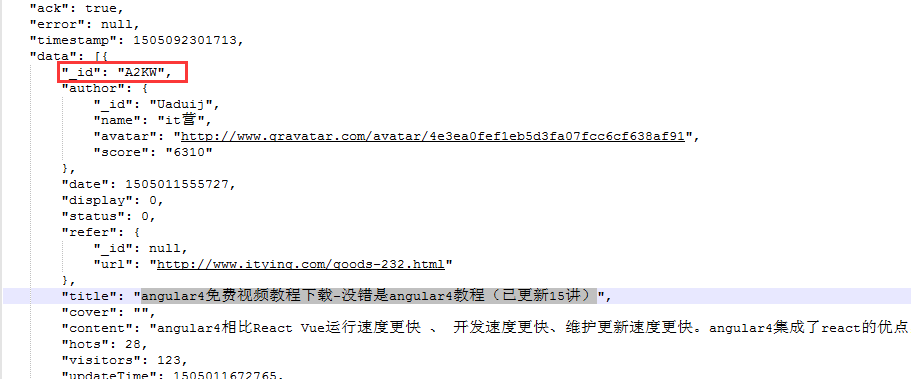
找到一个很了不起的东西!就是那个id,它就是链接后面带的。大胆推测,所有链接都是这个尿性!!(事实上我多点了几个链接看才敢确认这个尿性)
接下来就好办了,写代码解析这个json数据,然后拼凑出所有链接加入爬取队列爬取就行了。
结果发现通过首页链接点进去的下级链接,还是js渲染的。。。
没办法,拿着链接请求继续分析
得到这么些请求数据:
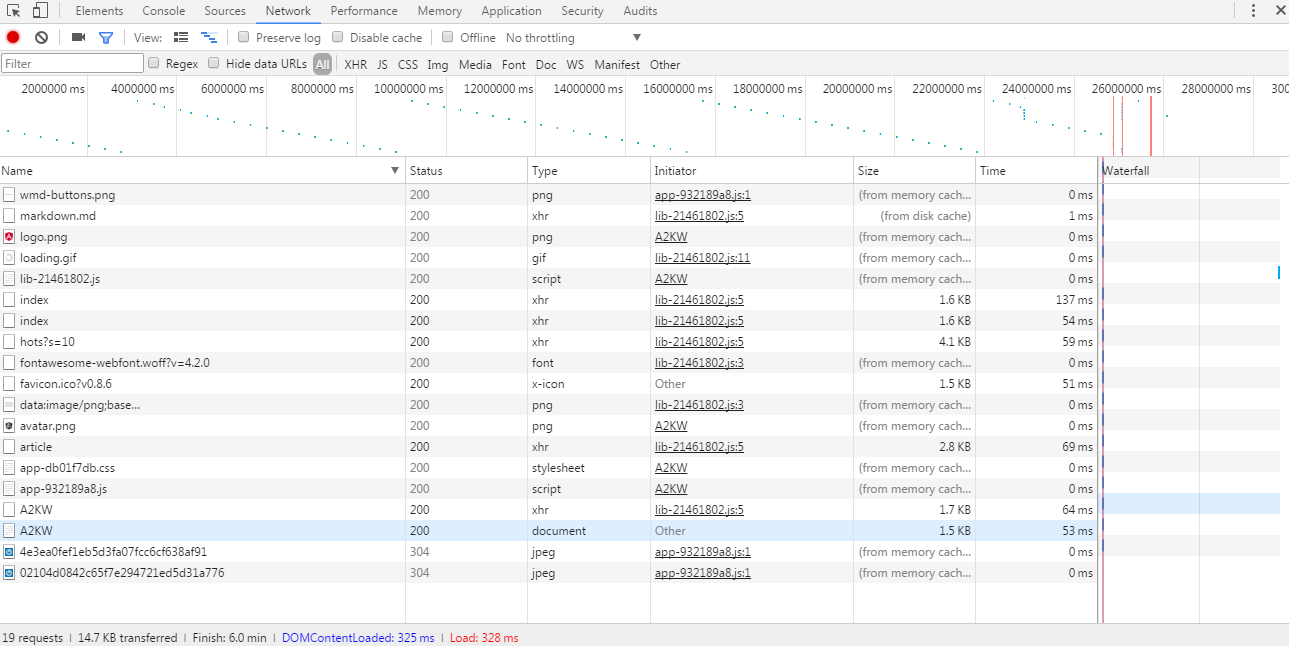
直接看到xhr栏,也就是ajax请求的数据
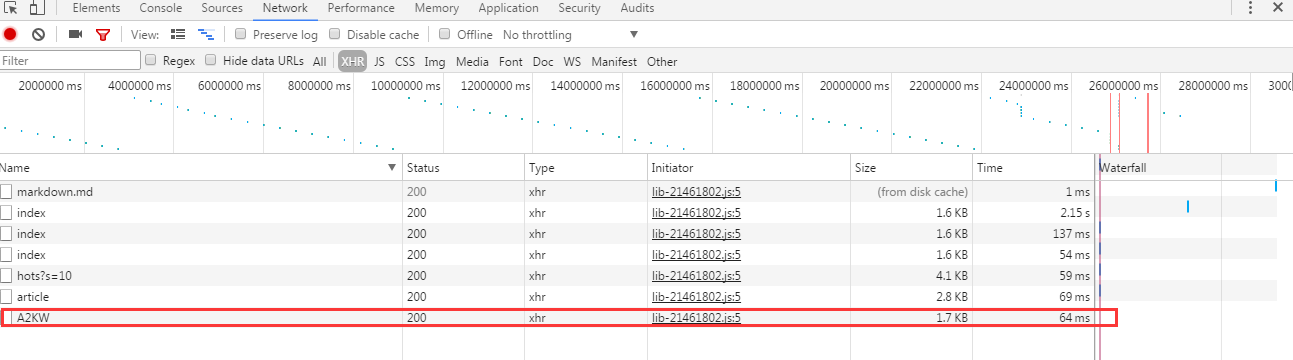
依旧从大到小查看json数据,和页面的内容匹配,直到第三个才找到正确的。++|
然后得到了最终数据的请求链接:http://angularjs.cn/api/article/A2KW
接下来就可以写代码了:
1 public class SpiderTest implements PageProcessor { 2 // 抓取网站的相关配置,包括编码、抓取间隔、重试次数等 3 private Site site = Site.me().setRetryTimes(3).setSleepTime(100); 4 // 先从浏览器中分析出隐藏请求可得出以下匹配规则 5 private static final String URLRULE = "http://angularjs\.cn/api/article/latest.*"; 6 private static String firstUrl = "http://angularjs.cn/api/article/"; 7 8 @Override 9 public Site getSite() { 10 // TODO Auto-generated method stub 11 return site; 12 } 13 14 @Override 15 public void process(Page page) { 16 // TODO Auto-generated method stub 17 /** 18 * 筛选出所有符合条件的url,手动添加到爬取队列。 19 */ 20 if (page.getUrl().regex(URLRULE).match()) { 21 //通过jsonpath得到json数据中的id内容,之后再拼凑待爬取链接 22 List<String> endUrls = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText()); 23 if (CollectionUtils.isNotEmpty(endUrls)) { 24 for (String endUrl : endUrls) { 25 page.addTargetRequest(firstUrl + endUrl); 26 } 27 } 28 } else { 29 //通过jsonpath从爬取到的json数据中提取出id和content内容 30 page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText())); 31 page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText())); 32 } 33 34 } 35 36 @Test 37 public void test(){ 38 Spider.create(new SpiderTest()).addUrl("http://angularjs.cn/api/article/latest?s=20").run(); 39 } 40 }
至此一个渲染的网页就爬取下来了。over