一、代码规范
- 1. 命名及书写规范
1)驼峰式命名 例如:SalaryPayingId
尽量使用英文单词,不要使用拼音(让人一眼就能看懂)
表的主键最好使用Guid.
2)字段长度定义
定义string类型的字段长度。

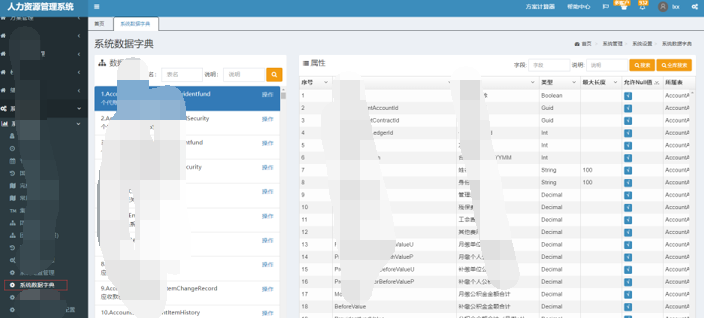
3)数据库表名及字段名称说明
数据库字段和表名定义的时候需要加上注释,我们当前的数据字典模块会读取当前的注释,
表结构之间不能有太多依赖,新表的设计最好不要影响基础表的操作。
更改新的功能时,如果对原有数据有影响,需要提前制定处理方案。
原表字段的删除要慎重
- 2. 代码存放路径规范
1) 每个模块分文件夹存放
当前有很多模块在设计的时候,创建的文件都是在一个文件夹里面,找起来特别的麻烦,最好是不通过的模块分开单独存放,便于之后的使用及查找
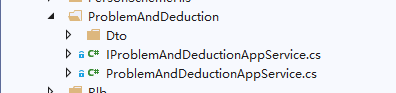
例如:我们问题点这里的模块,其实是有分很多的小模块,但是现在所有的代码都是放到这个里面,每次找起来就很麻烦。
我们对于的web层,application层,等这种相关的最好都是对应的。
- 3. 代码重写、循环调用、循环嵌套调用数据库
1) 如果一段代码重复出现3次以上,那么你的代码就需要优化了。
2) For循环里面调用数据库查询,会多次连接数据库,造成资源的消耗。可先批量从数库进行读取(需要条件过滤),然后再去循环,降低数据库的连接次数。
调整前:

调整后:
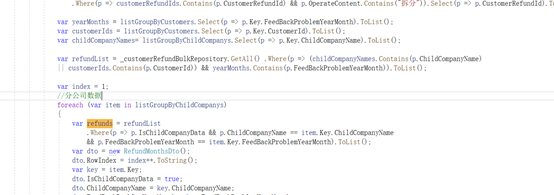
3)忌:for循环里调用UnitOfWork 非常耗资源
using (var uow = UnitOfWorkManager.Begin(TransactionScopeOption.RequiresNew)){}
- 4. 接口及接口文档的书写
1)接口 以后是否会拓展 是否要进行token验证
提供接口文档,是否可以做一些公用的接口,不要只针对当前这个需求,以及之后的拓展
对外接口,最好能够整理对应的接口文档进行详细说明。
- 5. 代码注释
1)遇到比较复杂的逻辑,可采用清晰的注释来辅助说明。但大的原则是尽可能的让你的代码看起来一目了然,无需注释也可以轻松看懂。
- 6. 大数据量操作
1) 如果遇到数据量比较多的,可采用多线程分批处理
2) 大数据量的定时任务最好放在使用时间最少的时候执行
3) 涉及到查询的地方,最好限制一下查询的最大范围,避免一次性查询太多数据。
- 7. 日常问题点记录
1)平时遇到问题,处理之后,可将问题点记录下来,分类进行整理。可以有自己的博客,或者自己整理的文件夹来进行记录
二、数据库
- 1. Sql查询优化
1) 如果linq查询比较复杂,可采用sql脚本的方式查询。需要注意的是我们传入list类型的参数时,如果数据量过多,在执行数据库的时候会超过长度,sql语句会被截断,此时可以采用字符串拼接的方式来查询。(但字符串拼接的方式尽量要少用,防止注入)
2) 复杂逻辑,可先在本地打开执行计划,看是否需要创建索引。
选择筛选度高的字段创建索引
尽可能的使用索引字段作为查询条件,尤其是聚集索引(比如id)
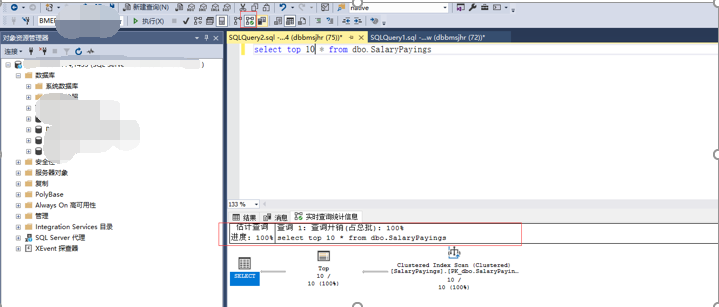
3) 排查本地问题时,可采用SQL Profiler来进行脚本的监控。
SQL Profiler: https://www.cnblogs.com/luoxiaoxiao102/p/15169920.html
- 2. 基本sql书写(基本的语句要会)
1) 简单数据库查询及修改,数据库小工具的使用,针对测试。
Sql常用查询:https://www.cnblogs.com/luoxiaoxiao102/p/15169780.html
- 3. 数据库小工具的使用
1)接口测试,Postmen的使用,针对测试。
简单用法:https://www.cnblogs.com/luoxiaoxiao102/p/15169842.html
定义环境变量:https://www.cnblogs.com/luoxiaoxiao102/p/13217633.html
一个接口调用多次:https://www.cnblogs.com/luoxiaoxiao102/p/13335907.html
模拟多线程调用接口:https://www.cnblogs.com/luoxiaoxiao102/p/13335975.html