1 简单动态字符串
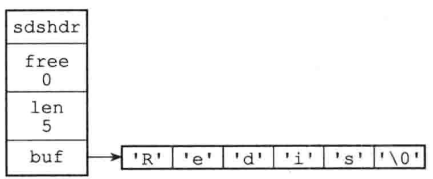
struct sdshdr { unsigned int len; unsigned int free; char buf[]; };
redis> set name intrack
Redis将在数据库中创建一个新的键值对,其中键是一个字符串,一个保存着"name"的sds;值是一个字符串,一个保存着"intrack"的sds。
- 常数复杂度获取字符长度
- 避免缓冲区溢出
- 减少修改字符操作时引起的内存分配次数(注意:free内存大小最大为1M)
- 二进制安全的
- 兼容部分C字符串函数(因为字符串后面以'�'结尾)
2 链表
typedef struct listNode { struct listNode *prev; struct listNode *next; void *value; } listNode;

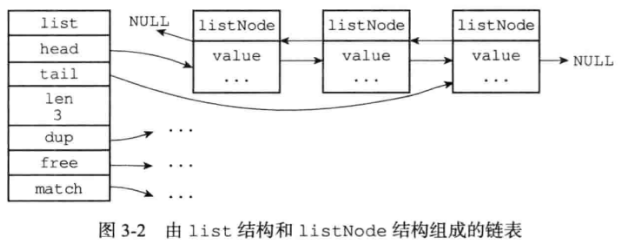
typedef struct list { listNode *head; listNode *tail; void *(*dup)(void *ptr); void (*free)(void *ptr); int (*match)(void *ptr, void *key); unsigned long len; } list;
list结构链表提供了表头指针head、表尾指针tail及链表长度len,而dup/free/match用于实现存储类型无关链表所需的类型特性函数。dup用于复制一个链表节点、free用于释放一个链表节点、match用于匹配链表节点和输入的值是否相等。
- 链表被广泛用于实现Redis的各种功能,比如列表键、发布与订阅、慢查询、监视器等。
- 每个链表节点由一个listNode结构表示,每个节点都有一个指向前置节点和后置节点的指针,所以Redis中链表是双向链表。
- 每个链表使用一个list结构表示,这个结构有表头节点指针、表尾节点指针、以及链表长度信息。
- 链表表头节点的前置节点和表尾的后置节点都指向NULL,所以Redis链表是无环链表。
- 通过将链表设置不同类型的特定函数,使得Redis链表可存储不同类型的值。
3 字典
redis> set msg "hello world"
在数据库中创建了一个键为msg,值为hello world的键值对时,这个键值对就保存在代表数据库的字典里面的。除了用作数据库之外,字典还是哈希键的底层实现之一。
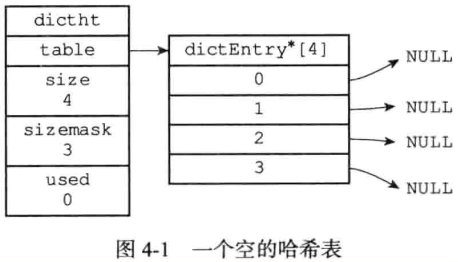
typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; // 哈希表大小掩码,用于计算索引值 unsigned long used; // 已有节点数量 } dictht;
typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry;
key保存键值对中的键,v属性保存值信息,值可以是一个指针/uint64_t整数/int64_t整数。next指向下一个哈希表节点指针,解决键值对冲突问题。

Redis的字典由dict结构定义: typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ int iterators; /* number of iterators currently running */ } dict;
type属性和privdata属性是针对不同类型的键值对,为创建可以存储多种类型的字典而设置的。
typedef struct dictType { unsigned int (*hashFunction)(const void *key); // 哈希计算 void *(*keyDup)(void *privdata, const void *key); // 复制键的函数 void *(*valDup)(void *privdata, const void *obj); // 复制值的函数 int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 比较键的函数 void (*keyDestructor)(void *privdata, void *key); // 销毁键的函数 void (*valDestructor)(void *privdata, void *obj); // 销毁值的函数 } dictType;
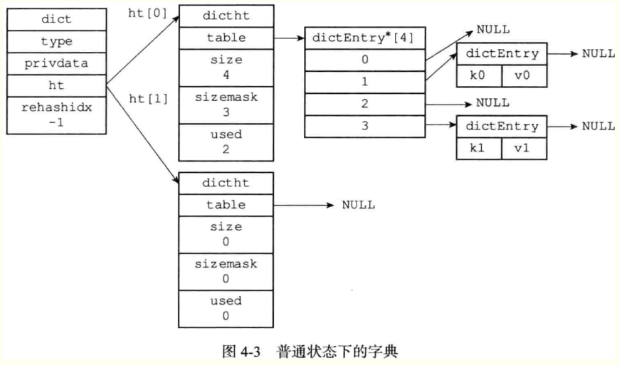
- 字典被广泛用于实现Redis的各种功能,其中包括数据库和哈希键。
- Redis中字典使用哈希表作为底层实现,每个字典有2个哈希表,一个平时使用,另一个只在rehash时使用。
- 当字典作为数据库的底层实现,或者作为哈希键的底层实现时,使用MurmurHash2算法计算键的哈希值。
- 哈希表使用分离连接法解决键冲突问题,被分配到同一个索引上多个键值会连接成一个单向链表。
- 在对哈希表进行扩展或者缩容操作时,需要将现有哈希表中键值对rehash到新哈希表中,这个rehash过程不是一次性完成的,而是渐进的。
4 跳跃表

typedef struct zskiplistNode { robj *obj; // Redis对象 double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned int span; } level[]; } zskiplistNode;
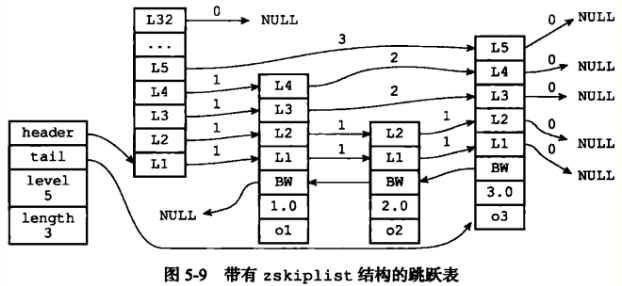
span属性用于记录两个节点之间的距离,指向NULL的forward值都为0。节点的分值score是一个浮点数,跳跃表中所有节点都按照分值从小到大排列。obj属性必须指向一个字符串对象,而字符串则保存着一个sds。
typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;
header和tail指针分表指向跳跃表的表头和表尾节点,通过length属性记录表长度,level属性用于保存跳跃表中层高最大的节点的层高值。每个跳跃表节点层高都是1~32的随机值,在同一个跳跃表中,多个节点可以包含相同的分值,但是每个节点的成员对象必须是唯一的。当分值相同时,节点按照成员对象的大小排序。
5 整数结合
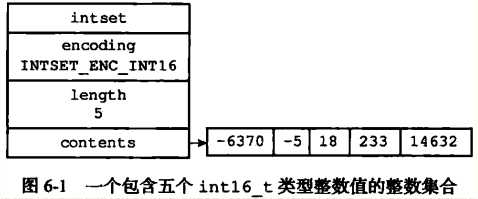
typedef struct intset { uint32_t encoding; // 16/32/64编码 uint32_t length; // 数组长度 int8_t contents[]; } intset;
contents数组用于存储整数,数组中的值按照值的大小从小到大有序排列,并且不会包含重复项。当encoding编码的是int型整数的话,那么contents数组中每4项用于保存一个int型整数。
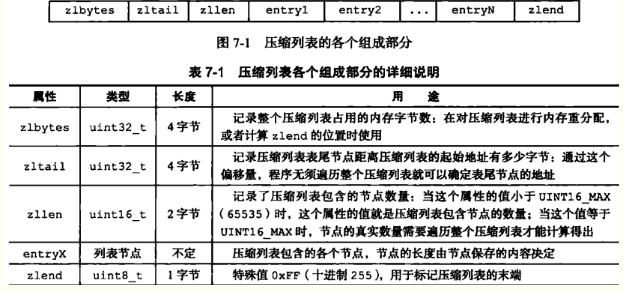
6 压缩列表
7 Redis中的对象
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj;
type表示对象类型,对于Redis键值对来说,键永远都是字符串,值可以是字符串、列表、哈希表、集合、有序集合中的一种。encoding表示对象编码,也就是该对象使用什么底层数据结构实现。ptr指向对象的底层数据结构。


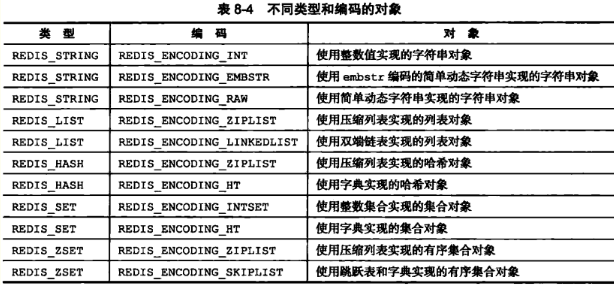
7.1 字符串对象
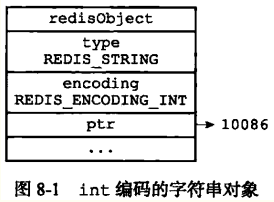

embstr编码方式是redisObject结构和sdshdr结构在一块内存中,使用embstr对象只需要调用一次内存分配函数即可,而raw方式需要调用2次。因为在同一块内存中,所以对缓存是友好的。


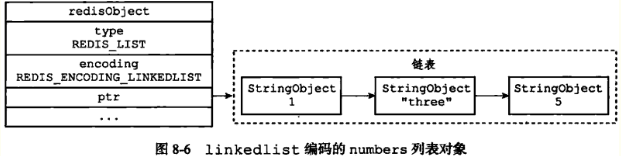
注意,linkedlist编码的列表对象在底层双端列表中包含了多个字符串对象,这个嵌套字符串对象行为在哈希表、集合中都会出现,字符串对象是Redis五种类型中唯一一种会被其他四种类型对象嵌套的对象。
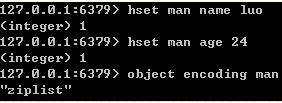

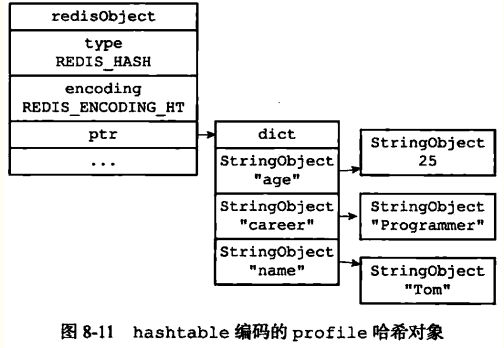
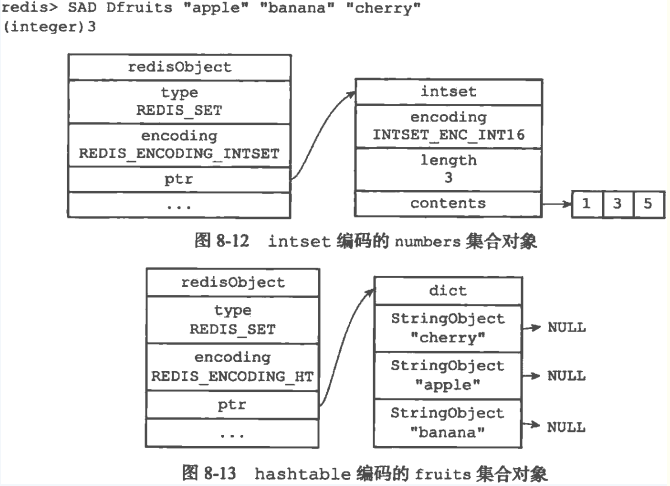
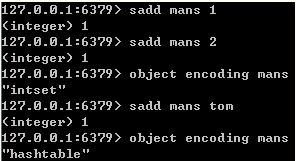
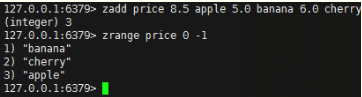
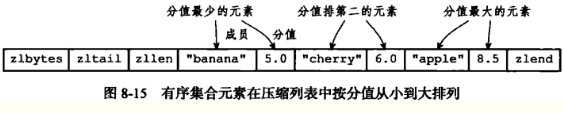
以上命令对应的压缩列表视图如下所示:
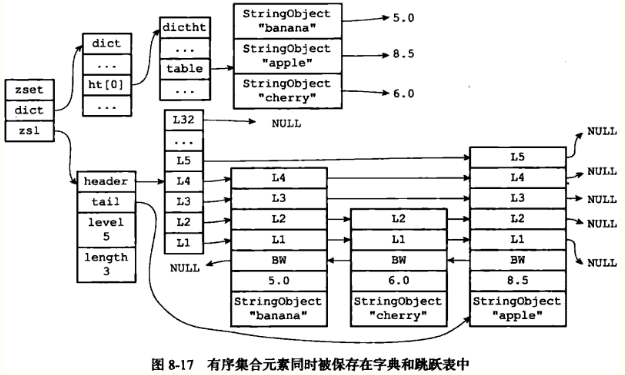
typedef struct zset { dict *dict; zskiplist *zsl; } zset;
zset中的zsl跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点保存一个集合元素,跳跃表节点的object属性保存元素的成员,score属性保存元素的分值。通过该跳跃表,可以对有序集合进行范围型操作,比如zrank、zrange命令就是基于跳跃表实现的。