一 什么是网络爬虫?
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
二 python如何访问互联网?
python通过urllib库访问互联网,urllib的一般格式为:url+lib
1 url的一般格式为(带方括号[]的为可选项):
- protocol://hostname[:port]/path/[:parameters][?query]#fragment
- 协议 域名(主机ip地址) 端口 路径
2 url由三部分组成:
- 第一部分是协议:http,https,ftp,file,ed2k...
- 第二部分是存放资源的服务器的域名系统或IP地址(有时候要包含端口号,各种传输协议都有默认的端口号,如http的默认端口号为80)。
- 第三部分是资源的具体地址,如目录或者文件名等。
3 urllib模块的简单使用
1 import urllib.request #导入urllib.request模块 2 response = urllib.request.urlopen("http://www.fishc.com") #调用该模块的urlopen()方法访问对应网页 3 html = response.read() # 将访问到的内容读取出来并保存在html变量中 4 print(html) # 打印html里面的内容,此时应该是格式混乱的 5 html = html.decode("utf-8") # 对html的内容进行解码操作,解码为utf-8的形式 6 print(html) # 重新打印
三 实战
1 爬取网站图片
- urlopen()函数的url参数既可以是字符串,也可以是request类对象;如果参数是一个url地址的话,python会把该地址转换成一个Request对象,然后再把这个对象作为参数传给urlopen函数。
- urlopen函数实际上是返回一个对象,该对象是一个类文件,跟文件对象很像,所以可以用read()方法读取urlopen()函数返回的内容。
- 除了read()方法之外,我们还可以:
- 通过调用geturl()方法得到被爬取的网站的具体地址;
- 通过调用info()方法得到HttpMessage的对象,其中包含远程服务器返回的head信息;
- 通过调用getcode()方法的到http协议的状态码
-
 class54_download_cat.py
class54_download_cat.py1 import urllib.request 2 3 response = urllib.request.urlopen('http://placekitten.com/g/300/200') # 打开要爬取的网站 4 cat_img = response.read() # 读取被爬网站的内容并保存 5 6 """ 7 req = urllib.request.Request('http://placekitten.com/g/300/200') 8 response = urllib.request.urlopen(req) 9 cat_img = response.read() 10 """ 11 12 with open('cat_300_200.jpg','wb') as f: # 把读取到的内容写入电脑磁盘 13 f.write(cat_img) 14 15 print(response.geturl()) 16 print(response.info()) 17 print(response.getcode()) 18 response.info()

2 利用有道词典翻译文本——怎么用python模拟浏览器进行翻译
- 客户端和服务器之间通信最常用的两种方法:
- get:从服务器请求获得数据
- post:向指定服务器提交被处理的数据
- post请求中Headers内容介绍:

- Remote Address:服务器的IP地址+端口号
- Request URL:urlopen方法实际打开的可以实现翻译的地址
- Request Method:请求的方法
- Status Code:状态码
- 客户端(浏览器)发送请求的headers的内容
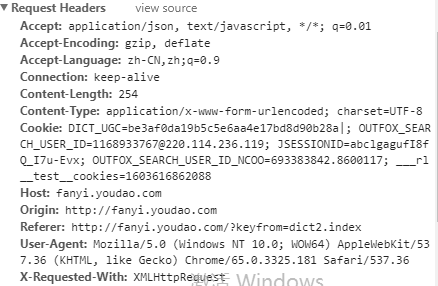
- Request Headers:客户端发送请求的请求头,它常常被服务端(服务器)用来判断是否非人类(有的代码可以自动访问服务器)访问。
- User-Agent:服务器识别人类访问还是代码访问的标志;如果是代码访问可能会被屏蔽
- post方法中的Form Data模块
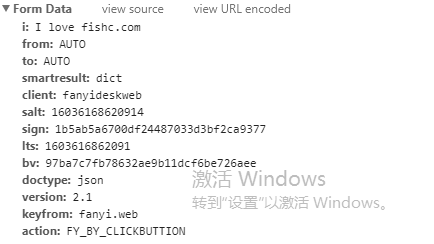
- i :后面跟的是提交的待翻译的原文
- 用python怎么提交post表单
- 如果给data参数没有赋值,请求的方法默认是GET形式;如果给data参数赋值了,请求的方法是POST形式。
- 并且data参数是具有固定格式的,我们可以通过urllib.parse.urlencode()方法将数据转换成data参数需要的形式
- 提交表单的过程中,data参数的内容就是浏览器发送的post请求中的form data模块的信息
-
class54_translation.py
1 import urllib.request 2 import urllib.parse 3 import json 4 5 content = input('请输入需要翻译的内容:') 6 7 url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' 8 data = {} 9 data['i'] = content 10 data['from'] = 'AUTO' 11 data['to'] = 'AUTO' 12 data['smartresult'] = 'dict' 13 data['client'] = 'fanyideskweb' 14 data['salt'] = '16036168620914' 15 data['sign'] = '1b5ab5a6700df24487033d3bf2ca9377' 16 data['lts'] = '1603616862091' 17 data['bv'] = '97ba7c7fb78632ae9b11dcf6be726aee' 18 data['doctype'] = 'json' 19 data['version'] = '2.1' 20 data['keyfrom'] = 'fanyi.web' 21 data['action'] = 'FY_BY_CLICKBUTTION' 22 data = urllib.parse.urlencode(data).encode('utf-8') 23 24 response = urllib.request.urlopen(url,data) 25 html = response.read().decode('utf-8') 26 27 28 target = json.loads(html) 29 """ 30 print(html) 31 print(target) 32 print(type(target)) 33 print(target['translateResult']) 34 print(target['translateResult'][0][0]) 35 """ 36 print("翻译结果:%s" % (target['translateResult'][0][0]['tgt']))
3 代码隐藏
- 用python程序爬取网站次数过多,会被原网站屏蔽,所以我们需要通过一些方法将代码隐藏,从而让我们的程序可以正常运行。
- 方法一:通过修改headers中的User-Agent来模拟浏览器访问对应的网站,从而避免我们通过代码访问该网站被网站发现后屏蔽
- 方法一:直接设置一个字典,把User-Agent作为参数传给Request类中的headers{}参数——通过Request的headers参数修改
- 方法二:在Request生成之后,调用add_header()把User-Agent加进去——通过Request.add_header()方法修改
- 加入代码隐藏功能的class54_translation.py文件
-
class54_translation2.py
1 import urllib.request # 发送http请求的模块 2 import urllib.parse # 负责解析功能的urllib.parse模块 3 import json # json是一种轻量级的数据交换格式,就是用字符串的形式把python的数据结构封装起来 4 import time # 时间相关模块 5 6 while True: # 通过while循环使得程序一直爬取对应网站 7 content = input('请输入需要翻译的内容(输入"q!"退出程序):') 8 if content == "q!": 9 break 10 11 url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' # 要访问的网站的地址 12 13 data = {} 14 data['i'] = content 15 data['from'] = 'AUTO' 16 data['to'] = 'AUTO' 17 data['smartresult'] = 'dict' 18 data['client'] = 'fanyideskweb' 19 data['salt'] = '16036168620914' 20 data['sign'] = '1b5ab5a6700df24487033d3bf2ca9377' 21 data['lts'] = '1603616862091' 22 data['bv'] = '97ba7c7fb78632ae9b11dcf6be726aee' 23 data['doctype'] = 'json' 24 data['version'] = '2.1' 25 data['keyfrom'] = 'fanyi.web' 26 data['action'] = 'FY_BY_CLICKBUTTION' 27 data = urllib.parse.urlencode(data).encode('utf-8') # 将原来的数据转换成data参数需要的格式,并将其从unicode形式编码为utf-8的形式 28 29 """ 30 # 直接打开爬取网页的代码 31 response = urllib.request.urlopen(url,data) 32 html = response.read().decode('utf-8') # 解码形式 33 """ 34 35 """ 36 # Request对象生成之前:通过字典的方式添加User-Agent参数 37 head = {} 38 head['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' 39 req = urllib.request.Request(url,data,head) 40 """ 41 42 # Request对象生成之后:通过add_header方法把user-agent参数添加进去 43 req = urllib.request.Request(url,data) # 发送请求,传递url网址和data参数,生成Request类 44 req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36') 45 46 response = urllib.request.urlopen(req) 47 html = response.read().decode('utf-8') # 解码形式 48 49 target = json.loads(html) # 利用json的loads方法载入html字符串,即将字符串格式的html转换成一个字典,然后通过索引的1方式访问target字典的内容,从而得到翻译后的结果 50 """ 51 print(html) 52 print(target) 53 print(type(target)) 54 print(target['translateResult']) 55 print(target['translateResult'][0][0]) 56 """ 57 print("翻译结果:%s" % (target['translateResult'][0][0]['tgt'])) 58 print(req.headers) 59 time.sleep(5) # 延迟程序模拟浏览器访问要爬取网站的时间,防止被该网站屏蔽我们的爬虫程序
- 方法二:使用代理
- 1 参数是一个字典{'协议类型':'代理IP:端口号'} proxy_support = urllib.request.ProxyHandler({})
- 2 定制和创建一个opener opener = urllib.request.build_opener(proxy_support)
- 什么是opener:可以把它看作一个私人定制,使用urlopen()方法打开一个网页的时候就是在使用一个默认的opener工作,这个opener的内容可以由我们自己定制的:比如可以给它加入特殊的headers;或者给他指定相关的代理,让他用代理ip去访问。
- 3a 安装opener urllib.request.install_opener(opener)
- 覆盖python默认的opener之后用新的opener进行工作(不用再写1、2步骤),即永久代理
- 3b 调用opener opener.open(url)
- 需要每次使用的时候把1、2写出来再用
- 举例:
-
class55_proxy_eg.py
1 import urllib.request 2 import random 3 4 url = 'http://www.whatismyip.com.tw' 5 6 iplist = ['119.6.144.73:81','183.203.208.166:8118','111.1.32.28:81'] 7 8 proxy_support = urllib.request.ProxyHandler({'http':random.choice(iplist)}) 9 10 opener = urllib.request.build_opener(proxy_support) 11 opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36')] 12 13 14 urllib.request.install_opener(opener) 15 16 response = urllib.request.urlopen(url) 17 html = response.read().decode('utf-8') 18 19 print(html)
链接不成功。。。