CPU性能
响应时间:指的就是,我们执行一个程序,到底需要花多少时间。花的时间越少,自然性能就越好。
吞吐率:在一定的时间范围内,到底能处理多少事情。这里的“事情”,在计算机里就是处理的数据或者执行的程序指令。
我们一般把性能,定义成响应时间的倒数,也就是: 性能 = 1/响应时间
程序运行的时间
程序运行的时间=程序运行结束的时间-程序开始运行的时间
但是,计算机可能同时运行着好多个程序,CPU实际上不停地在各个程序之间进行切换。在这些走掉的时间里面,很可能CPU切换去运行别的程序了。所以这个时间并不准。
我们使用time命令统计运行时间:
$ time seq 1000000 | wc -l
1000000
real 0m0.101s
user 0m0.031s
sys 0m0.016s
其中real就是Wall Clock Time,而程序实际花费的CPU执行时间,就是user time加上sys time。
我们下面对程序的CPU执行时间进行拆解:
程序的CPU执行时间=CPU时钟周期数×时钟周期时间
时钟周期时间:如果一台电脑的主频是2.8GHz,那么可以简单认为,CPU在1秒时间内,可以执行的简单指令的数量是2.8G条。在这个2.8GHz的CPU上,这个时钟周期时间,就是1/2.8G。
对于上面的公式:CPU时钟周期数还可以拆解成指令数×每条指令的平均时钟周期数Cycles Per Instruction,简称CPI)。
程序的CPU执行时间=指令数×CPI×Clock Cycle Time
并行优化
由于通过提升CPU频率已经达到瓶颈,所以开始推出多核CPU,通过提升“吞吐率”而不是“响应时间”,来达到目的。
但是,并不是所有问题,都可以通过并行提高性能来解决。如果想要使用这种思想,需要满足这样几个条件。
- 需要进行的计算,本身可以分解成几个可以并行的任务。
- 需要能够分解好问题,并确保几个人的结果能够汇总到一起。
- 在“汇总”这个阶段,是没有办法并行进行的,还是得顺序执行,一步一步来。
所以并行计算涉及到了一个阿姆达尔定律(Amdahl’s Law)。
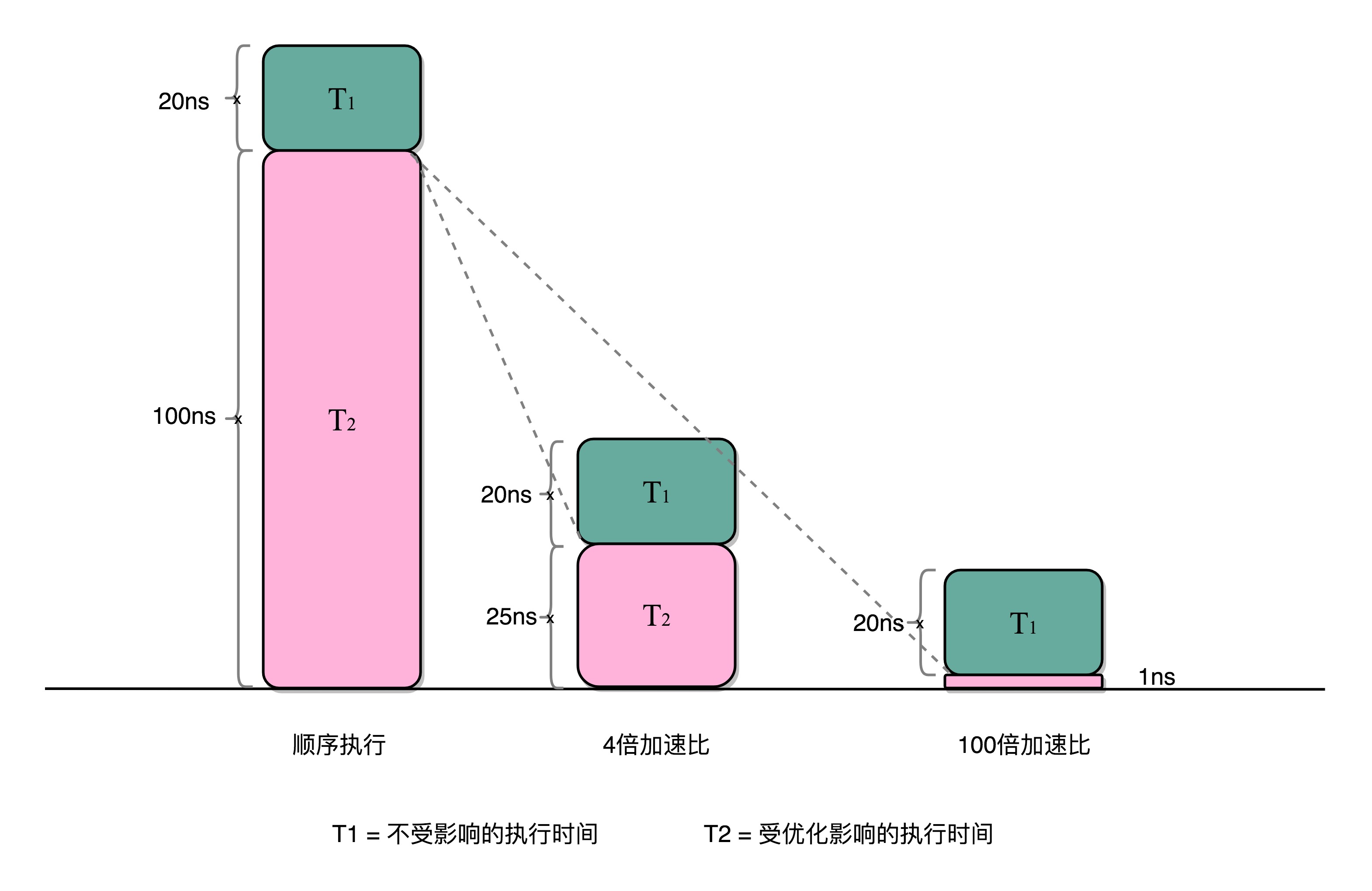
对于一个程序进行优化之后,处理器并行运算之后效率提升的情况。具体可以用这样一个公式来表示:
优化后的执行时间 = 受优化影响的执行时间/加速倍数+不受影响的执行时间
比如做一段数据的计算, 本来如果整个计算单核完成需要120ns,但是我们可以将这个任务拆分成4个,最后再汇总加起来。如果每个任务单独计算需要25ns,加起来汇总需要20ns,那么4个任务并行计算需要100/4+20=25ns。
即使我们增加更多的并行度来提供加速倍数,比如有100个CPU,整个时间也需要100/100+20=21ns。
从编译到汇编,代码怎么变成机器码?
如下C语言程序例子:
// test.c
int main()
{
int a = 1;
int b = 2;
a = a + b;
}
我们给两个变量 a、b分别赋值1、2,然后再将a、b两个变量中的值加在一起,重新赋值给了a整个变量。
要让这段程序在一个Linux操作系统上跑起来,我们需要把整个程序翻译成一个汇编语言(ASM,Assembly Language)的程序,这个过程我们一般叫编译(Compile)成汇编代码。
针对汇编代码,我们可以再用汇编器(Assembler)翻译成机器码(Machine Code)。这些机器码由“0”和“1”组成的机器语言表示。这一条条机器码,就是一条条的计算机指令。这样一串串的16进制数字,就是我们CPU能够真正认识的计算机指令。

汇编代码其实就是“给程序员看的机器码”,也正因为这样,机器码和汇编代码是一一对应的。我们人类很容易记住add、mov这些用英文表示的指令,而8b 45 f8这样的指令,由于很难一下子看明白是在干什么,所以会非常难以记忆。所以我们需要汇编代码。
程序指令
指令是如何被执行的
一个CPU里面会有很多种不同功能的寄存器。我这里给你介绍三种比较特殊的。
一个是PC寄存器(Program Counter Register),也叫指令地址寄存器(Instruction Address Register)。它就是用来存放下一条需要执行的计算机指令的内存地址。
第二个是指令寄存器(Instruction Register),用来存放当前正在执行的指令。
第三个是条件码寄存器(Status Register),用里面的一个一个标记位(Flag),存放CPU进行算术或者逻辑计算的结果。
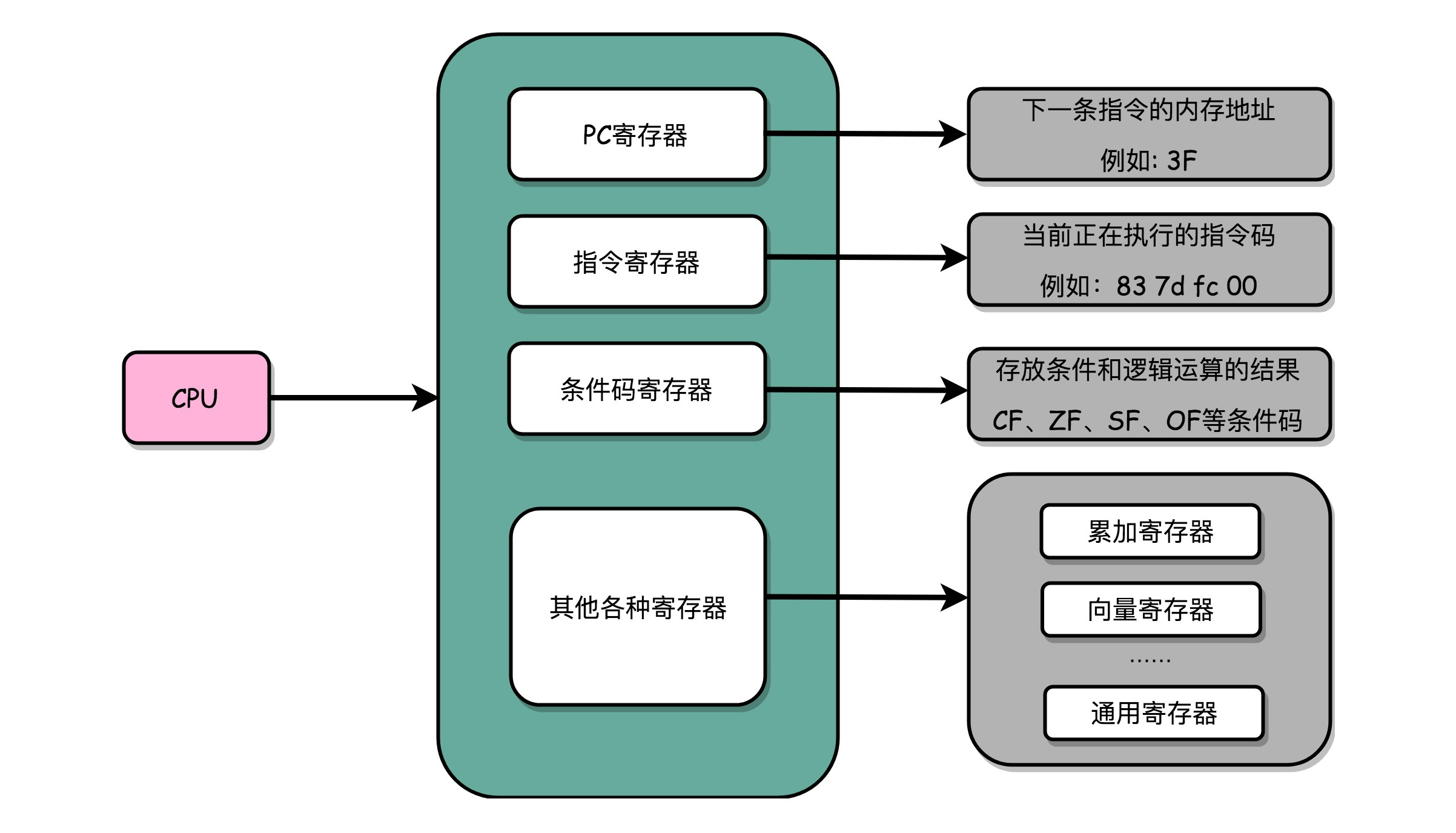
实际上,一个程序执行的时候,CPU会根据PC寄存器里的地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。可以看到,一个程序的一条条指令,在内存里面是连续保存的,也会一条条顺序加载。
程序的执行和跳转
现在就来看一个包含if…else的简单程序。
// test.c
#include <time.h>
#include <stdlib.h>
int main()
{
srand(time(NULL));
int r = rand() % 2;
int a = 10;
if (r == 0)
{
a = 1;
} else {
a = 2;
}
把这个程序编译成汇编代码。
if (r == 0)
3b: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
3f: 75 09 jne 4a <main+0x4a>
{
a = 1;
41: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x1
48: eb 07 jmp 51 <main+0x51>
}
else
{
a = 2;
4a: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
51: b8 00 00 00 00 mov eax,0x0
}
可以看到,这里对于r == 0的条件判断,被编译成了cmp和jne这两条指令。
对于:
cmp DWORD PTR [rbp-0x4],0x0
cmp指令比较了前后两个操作数的值,这里的DWORD PTR代表操作的数据类型是32位的整数,而[rbp-0x4]则是一个寄存器的地址。所以,第一个操作数就是从寄存器里拿到的变量r的值。第二个操作数0x0就是我们设定的常量0的16进制表示。cmp指令的比较结果,会存入到条件码寄存器当中去。
在这里,如果比较的结果是False,也就是0,就把零标志条件码(对应的条件码是ZF,Zero Flag)设置为1。
cmp指令执行完成之后,PC寄存器会自动自增,开始执行下一条jne的指令。
对于:
jne 4a <main+0x4a>
jne指令,是jump if not equal的意思,它会查看对应的零标志位。如果为0,会跳转到后面跟着的操作数4a的位置。这个4a,对应这里汇编代码的行号,也就是上面设置的else条件里的第一条指令。
当跳转发生的时候,PC寄存器就不再是自增变成下一条指令的地址,而是被直接设置成这里的4a这个地址。这个时候,CPU再把4a地址里的指令加载到指令寄存器中来执行。
4a: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
51: b8 00 00 00 00 mov eax,0x0
4a的指令,实际是一条mov指令,第一个操作数和前面的cmp指令一样,是另一个32位整型的寄存器地址,以及对应的2的16进制值0x2。mov指令把2设置到对应的寄存器里去,相当于一个赋值操作。然后,PC寄存器里的值继续自增,执行下一条mov指令。
下一条指令也是mov,第一个操作数eax,代表累加寄存器,第二个操作数0x0则是16进制的0的表示。这条指令其实没有实际的作用,它的作用是一个占位符。
函数调用
我们先来看个例子:
// function_example.c
#include <stdio.h>
int static add(int a, int b)
{
return a+b;
}
int main()
{
int x = 5;
int y = 10;
int u = add(x, y);
}
我们把这个程序编译之后:
int static add(int a, int b)
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 89 7d fc mov DWORD PTR [rbp-0x4],edi
7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
return a+b;
a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
d: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
10: 01 d0 add eax,edx
}
12: 5d pop rbp
13: c3 ret
0000000000000014 <main>:
int main()
{
14: 55 push rbp
15: 48 89 e5 mov rbp,rsp
18: 48 83 ec 10 sub rsp,0x10
int x = 5;
1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5
int y = 10;
23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xa
int u = add(x, y);
2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
30: 89 d6 mov esi,edx
32: 89 c7 mov edi,eax
34: e8 c7 ff ff ff call 0 <add>
39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
3c: b8 00 00 00 00 mov eax,0x0
}
41: c9 leave
42: c3 ret
在add函数编译之后,代码先执行了一条push指令和一条mov指令;在函数执行结束的时候,又执行了一条pop和一条ret指令。
add函数的第0行,push rbp这个指令,就是在进行压栈。这里的rbp又叫栈帧指针(Frame Pointer),是一个存放了当前栈帧位置的寄存器。push rbp就把之前调用函数的返回地址,压到栈顶。
接着,第1行的一条命令mov rbp, rsp里,则是把rsp这个栈指针(Stack Pointer)的值复制到rbp里,而rsp始终会指向栈顶。这个命令意味着,rbp这个栈帧指针指向的返回地址,变成当前最新的栈顶,也就是add函数的返回地址了。
而在函数add执行完成之后,又会分别调用第12行的pop rbp来将当前的栈顶出栈,然后调用第13行的ret指令,将程序的控制权返回到出栈后的栈顶,也就是main函数的返回地址。
拆解程序执行
实际上,“C语言代码-汇编代码-机器码” 这个过程,在我们的计算机上进行的时候是由两部分组成的。
第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。在这三个阶段完成之后,我们就生成了一个可执行文件。
第二部分,我们通过装载器(Loader)把可执行文件装载(Load)到内存中。CPU从内存中读取指令和数据,来开始真正执行程序。

链接
静态链接
程序的链接,是把对应的不同文件内的代码段,合并到一起,成为最后的可执行文件。
在可执行文件里,我们可以看到,对应的函数名称,像add、main等等,乃至你自己定义的全局可以访问的变量名称对应的地址,存储在一个叫作符号表(Symbols Table)的位置里。符号表相当于一个地址簿,把名字和地址关联了起来。
经过程序的链接之后,main函数里调用add的跳转地址,不再是下一条指令的地址了,而是add函数的入口地址了。
链接器会扫描所有输入的目标文件,然后把所有符号表里的信息收集起来,构成一个全局的符号表。然后再根据重定位表,把所有不确定要跳转地址的代码,根据符号表里面存储的地址,进行一次修正。最后,把所有的目标文件的对应段进行一次合并,变成了最终的可执行代码。
这个合并代码段的方法,是叫静态链接。
动态链接
在动态链接的过程中,我们想要“链接”的,不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库(Shared Libraries)。
要想要在程序运行的时候共享代码,也有一定的要求,就是这些机器码必须是“地址无关”的。换句话说就是,这段代码,无论加载在哪个内存地址,都能够正常执行。
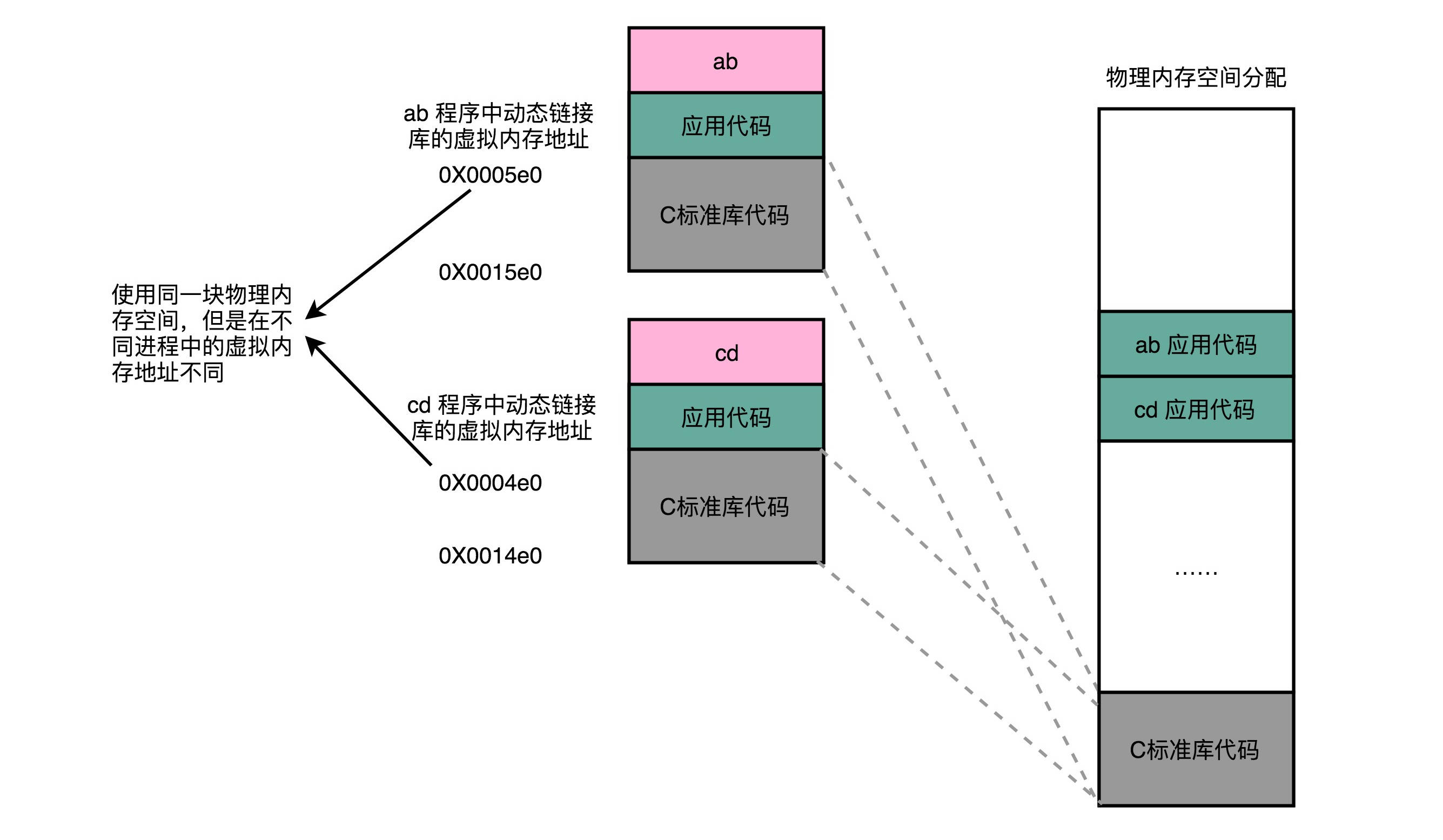
动态代码库内部的变量和函数调用都是使用相对地址。因为整个共享库是放在一段连续的虚拟内存地址中的,无论装载到哪一段地址,不同指令之间的相对地址都是不变的。
装载程序
在运行这些可执行文件的时候,我们其实是通过一个装载器,解析ELF或者PE格式的可执行文件。装载器会把对应的指令和数据加载到内存里面来,让CPU去执行。
装载器需要满足两个要求:
- 可执行程序加载后占用的内存空间应该是连续的。因为CPU在执行指令的时候,程序计数器是顺序地一条一条指令执行下去。
- 我们需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。因为我们现在的计算机通常会同时运行很多个程序,可能你想要的内存地址已经被其他加载了的程序占用了。
基于上面,我们需要在内存空间地址和整个程序指令指定的内存地址做一个映射。
把指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address),实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。
内存分页
分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。
从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。

分页之后避免了整个程序和硬盘进行交换而产生性能瓶颈。即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,让整个机器被内存交换的过程给卡住。