本文基于 TiDB release-5.1进行分析,需要用到 Go 1.16以后的版本
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/592
概述
整个 SQL 的执行过程包含以下几个部分:
- 首先是服务器在哪里接收到客户端的连接的;
- 然后就是解析 SQL 语句,将 SQL 解析为 AST 语法树的地方在哪里实现的;
- 解析完 SQL 之后 TiDB 将会进行 SQL 的优化,分别是执行逻辑计划优化、物理计划优化;
- 然后就是将执行优化完的执行计划;
- 因为 TiDB 的数据都是存放在 TiKV 的,所以需要向 TiKV 处理器发送请求;
- 最后将 TiKV 返回的数据封装,返回给这条 SQL 请求的客户端;
构建 AST 语法树
在 handleQuery 里面会调用 cc.ctx.Parse,这一句代码最终会调用到 Parser 解析器的 Parse 方法进行解析:

例如下面的这个 SQL 语句:
select id,name,age from student where age>1 and name='pingcap';

会被解析生成一颗语法树,然后保存到ast.StmtNode这个数据结构里面。
type SelectStmt struct {
dmlNode
*SelectStmtOpts
Distinct bool
From *TableRefsClause
Where ExprNode
Fields *FieldList
GroupBy *GroupByClause
Having *HavingClause
...
}
对 SQL 解析这部分感兴趣的可以看这一篇:https://pingcap.com/zh/blog/tidb-source-code-reading-5 ,写的非常好,我就不再深入。
优化
这里的优化包含三部分:构建执行计划、逻辑计划优化、物理计划优化;
在 handleQuery 里构建完AST语法树之后继续往下看,会调用到 Optimize 函数执行逻辑优化,构建 优化计划:

在 Optimize 函数中会继续调用到 optimize 函数:
func optimize(ctx context.Context, sctx sessionctx.Context, node ast.Node, is infoschema.InfoSchema) (plannercore.Plan, types.NameSlice, float64, error) {
...
// 初始化 PlanBuilder
builder, _ := plannercore.NewPlanBuilder(sctx, is, hintProcessor)
beginRewrite := time.Now()
// 构建执行计划
p, err := builder.Build(ctx, node)
if err != nil {
return nil, nil, 0, err
}
...
names := p.OutputNames()
// 没有 logical plan 则直接返回
logic, isLogicalPlan := p.(plannercore.LogicalPlan)
if !isLogicalPlan {
return p, names, 0, nil
}
...
beginOpt := time.Now()
// logical plan & physical plan
finalPlan, cost, err := plannercore.DoOptimize(ctx, sctx, builder.GetOptFlag(), logic)
sctx.GetSessionVars().DurationOptimization = time.Since(beginOpt)
return finalPlan, names, cost, err
}
这里主要分为两部分,调用 builder.Build构建执行计划 ,以及调用 DoOptimize进行逻辑优化和物理优化。
构建执行计划
构建执行计划是通过调用 builder 的 Build方法进行的,Build 方法里面会根据 AST 树的类型来判断应该要构建什么样的执行计划:
func (b *PlanBuilder) Build(ctx context.Context, node ast.Node) (Plan, error) {
b.optFlag |= flagPrunColumns
switch x := node.(type) {
case *ast.DeleteStmt:
return b.buildDelete(ctx, x)
case *ast.InsertStmt:
return b.buildInsert(ctx, x)
case *ast.SelectStmt:
// select-into 语法处理
if x.SelectIntoOpt != nil {
return b.buildSelectInto(ctx, x)
}
return b.buildSelect(ctx, x)
case *ast.UpdateStmt:
return b.buildUpdate(ctx, x)
case ast.DDLNode:
return b.buildDDL(ctx, x)
...
}
return nil, ErrUnsupportedType.GenWithStack("Unsupported type %T", node)
}
因为代码实在太多了,不可能挨个分析,我这里通过一个简单的例子分析一下 buildSelect 里面做了些什么事情:
比如说我们现在有一张student表,要去查里面的数据:
CREATE TABLE student
(
id VARCHAR(31),
name VARCHAR(50),
age int,
key id_idx (id)
);
INSERT INTO student VALUES ('pingcap001', 'pingcap', 3);
select sum(age) as total_age from student where name='pingcap' group by name;
TiDB 在接收到这样的一条查询命令的时候,先会构建一个 AST 语法树:
type SelectStmt struct {
From *TableRefsClause
Where ExprNode
Fields *FieldList
GroupBy *GroupByClause
Having *HavingClause
OrderBy *OrderByClause
Limit *Limit
...
}
然后 buildSelect 会根据这颗语法树的节点信息来构建出执行计划,执行计划由下面各个算子构成:
- DataSource :这个就是数据源,也就是表,也就是上面的 student 表;
- LogicalSelection:这个是 where 后面的过滤条件;
- LogicalAggregation:这里主要包含两部分信息,一个是 Group by 后面的字段,以及 select 中的聚合函数的字段,以及函数等;
- Projection:这里就是对应的 select 后面跟的字段;
它们之间是按照层级关系进行封装的:

func (b *PlanBuilder) buildSelect(ctx context.Context, sel *ast.SelectStmt) (p LogicalPlan, err error) {
...
// 构建 dataSource 算子
p, err = b.buildTableRefs(ctx, sel.From)
if err != nil {
return nil, err
}
if sel.GroupBy != nil {
// 获取 group by 的字段
p, gbyCols, err = b.resolveGbyExprs(ctx, p, sel.GroupBy, sel.Fields.Fields)
if err != nil {
return nil, err
}
}
// 通过查询条件构建 Logical Selection
if sel.Where != nil {
p, err = b.buildSelection(ctx, p, sel.Where, nil)
if err != nil {
return nil, err
}
}
// 校验sql是否有函数
hasAgg := b.detectSelectAgg(sel)
needBuildAgg := hasAgg
if hasAgg {
if b.buildingRecursivePartForCTE {
return nil, ErrCTERecursiveForbidsAggregation.GenWithStackByArgs(b.genCTETableNameForError())
}
// len(aggFuncs) == 0 和 sel.GroupBy == nil 表示SELECT字段内的所有聚合函数实际上是来自外层查询的相关聚合,这些聚合已经在外层查询中建立。
aggFuncs, totalMap = b.extractAggFuncsInSelectFields(sel.Fields.Fields)
if len(aggFuncs) == 0 && sel.GroupBy == nil {
needBuildAgg = false
}
}
// 根据sql中的函数构建 LogicalAggregation 算子
if needBuildAgg {
var aggIndexMap map[int]int
p, aggIndexMap, err = b.buildAggregation(ctx, p, aggFuncs, gbyCols, correlatedAggMap)
if err != nil {
return nil, err
}
for agg, idx := range totalMap {
totalMap[agg] = aggIndexMap[idx]
}
}
var oldLen int
// 构建 Projection 字段投影
p, projExprs, oldLen, err = b.buildProjection(ctx, p, sel.Fields.Fields, totalMap, nil, false, sel.OrderBy != nil)
if err != nil {
return nil, err
}
// 构建 having 条件
if sel.Having != nil {
b.curClause = havingClause
p, err = b.buildSelection(ctx, p, sel.Having.Expr, havingMap)
if err != nil {
return nil, err
}
}
// 构建 LogicalSort 算子
if sel.OrderBy != nil {
if b.ctx.GetSessionVars().SQLMode.HasOnlyFullGroupBy() {
p, err = b.buildSortWithCheck(ctx, p, sel.OrderBy.Items, orderMap, windowMapper, projExprs, oldLen, sel.Distinct)
} else {
p, err = b.buildSort(ctx, p, sel.OrderBy.Items, orderMap, windowMapper)
}
if err != nil {
return nil, err
}
}
// 构建 LogicalLimit 算子
if sel.Limit != nil {
p, err = b.buildLimit(p, sel.Limit)
if err != nil {
return nil, err
}
}
...
return p, nil
}
这个过程是非常复杂的,我这上面省略了很多细节。下面我们看一下 buildTableRefs 方法是如何构建 DataSource 算子的。
buildTableRefs 首先会根据传入的 sel.From节点判断它的类型:
func (b *PlanBuilder) buildResultSetNode(ctx context.Context, node ast.ResultSetNode) (p LogicalPlan, err error) {
//对传入的节点进行类型校验
switch x := node.(type) {
// join类型
case *ast.Join:
return b.buildJoin(ctx, x)
// TableSourced 类型
case *ast.TableSource:
var isTableName bool
switch v := x.Source.(type) {
case *ast.SelectStmt:
ci := b.prepareCTECheckForSubQuery()
defer resetCTECheckForSubQuery(ci)
p, err = b.buildSelect(ctx, v)
case *ast.SetOprStmt:
ci := b.prepareCTECheckForSubQuery()
defer resetCTECheckForSubQuery(ci)
p, err = b.buildSetOpr(ctx, v)
case *ast.TableName:
p, err = b.buildDataSource(ctx, v, &x.AsName)
isTableName = true
default:
err = ErrUnsupportedType.GenWithStackByArgs(v)
}
// 重复列校验
dupNames := make(map[string]struct{}, len(p.Schema().Columns))
for _, name := range p.OutputNames() {
colName := name.ColName.O
if _, ok := dupNames[colName]; ok {
return nil, ErrDupFieldName.GenWithStackByArgs(colName)
}
dupNames[colName] = struct{}{}
}
return p, nil
...
}
}
因为在 sql 的 from 后面可以接表名、join语句、子查询等,所以这里会根据不同的情况做一些判断处理。我们上面的例子中,sql 比较简单 from 后面只接了表,所以首先会走到 buildJoin 判断一下有没有做 join ,如果没有那么会直接到 ast.TableSource 分支中,然后调用 buildDataSource 方法。

func (b *PlanBuilder) buildDataSource(ctx context.Context, tn *ast.TableName, asName *model.CIStr) (LogicalPlan, error) { dbName := tn.Schema sessionVars := b.ctx.GetSessionVars() // 根据表名从缓存中获取表的元数据 tbl, err := b.is.TableByName(dbName, tn.Name) if err != nil { return nil, err } tableInfo := tbl.Meta() ... //校验是否是 virtual table if tbl.Type().IsVirtualTable() { if tn.TableSample != nil { return nil, expression.ErrInvalidTableSample.GenWithStackByArgs("Unsupported TABLESAMPLE in virtual tables") } return b.buildMemTable(ctx, dbName, tableInfo) } // 校验是否是一个视图 if tableInfo.IsView() { if tn.TableSample != nil { return nil, expression.ErrInvalidTableSample.GenWithStackByArgs("Unsupported TABLESAMPLE in views") } return b.BuildDataSourceFromView(ctx, dbName, tableInfo) } // 校验该表是否是一个序列对象 if tableInfo.IsSequence() { if tn.TableSample != nil { return nil, expression.ErrInvalidTableSample.GenWithStackByArgs("Unsupported TABLESAMPLE in sequences") } return b.buildTableDual(), nil } // 校验是否有分区 if tableInfo.GetPartitionInfo() != nil { ... } else if len(tn.PartitionNames) != 0 { return nil, ErrPartitionClauseOnNonpartitioned } tblName := *asName if tblName.L == "" { tblName = tn.Name } // 这里应该是获取的可能会用到的索引 possiblePaths, err := getPossibleAccessPaths(b.ctx, b.TableHints(), tn.IndexHints, tbl, dbName, tblName, b.isForUpdateRead, b.is.SchemaMetaVersion()) if err != nil { return nil, err } // 获取表的字段 var columns []*table.Column if b.inUpdateStmt { columns = tbl.WritableCols() } else if b.inDeleteStmt { columns = tbl.FullHiddenColsAndVisibleCols() } else { columns = tbl.Cols() } var statisticTable *statistics.Table if _, ok := tbl.(table.PartitionedTable); !ok || b.ctx.GetSessionVars().UseDynamicPartitionPrune() { statisticTable = getStatsTable(b.ctx, tbl.Meta(), tbl.Meta().ID) } // 构建DataSource结构体 ds := DataSource{ DBName: dbName, TableAsName: asName, table: tbl, tableInfo: tableInfo, statisticTable: statisticTable, astIndexHints: tn.IndexHints, IndexHints: b.TableHints().indexHintList, indexMergeHints: indexMergeHints, possibleAccessPaths: possiblePaths, Columns: make([]*model.ColumnInfo, 0, len(columns)), partitionNames: tn.PartitionNames, TblCols: make([]*expression.Column, 0, len(columns)), preferPartitions: make(map[int][]model.CIStr), is: b.is, isForUpdateRead: b.isForUpdateRead, }.Init(b.ctx, b.getSelectOffset()) var handleCols HandleCols schema := expression.NewSchema(make([]*expression.Column, 0, len(columns))...) names := make([]*types.FieldName, 0, len(columns)) // 添加字段 for i, col := range columns { ds.Columns = append(ds.Columns, col.ToInfo()) names = append(names, &types.FieldName{ DBName: dbName, TblName: tableInfo.Name, ColName: col.Name, OrigTblName: tableInfo.Name, OrigColName: col.Name, Hidden: col.Hidden, NotExplicitUsable: col.State != model.StatePublic, }) newCol := &expression.Column{ UniqueID: sessionVars.AllocPlanColumnID(), ID: col.ID, RetType: col.FieldType.Clone(), OrigName: names[i].String(), IsHidden: col.Hidden, } // 校验是否是int类型的主键 if col.IsPKHandleColumn(tableInfo) { handleCols = &IntHandleCols{col: newCol} } schema.Append(newCol) ds.TblCols = append(ds.TblCols, newCol) } // 如果没有int 类型的主键,那么则会默认添加一个 if handleCols == nil { if tableInfo.IsCommonHandle { primaryIdx := tables.FindPrimaryIndex(tableInfo) handleCols = NewCommonHandleCols(b.ctx.GetSessionVars().StmtCtx, tableInfo, primaryIdx, ds.TblCols) } else { extraCol := ds.newExtraHandleSchemaCol() handleCols = &IntHandleCols{col: extraCol} ds.Columns = append(ds.Columns, model.NewExtraHandleColInfo()) schema.Append(extraCol) names = append(names, &types.FieldName{ DBName: dbName, TblName: tableInfo.Name, ColName: model.ExtraHandleName, OrigColName: model.ExtraHandleName, }) ds.TblCols = append(ds.TblCols, extraCol) } } ds.handleCols = handleCols handleMap := make(map[int64][]HandleCols) handleMap[tableInfo.ID] = []HandleCols{handleCols} b.handleHelper.pushMap(handleMap) ds.SetSchema(schema) ds.names = names ds.setPreferredStoreType(b.TableHints()) ds.SampleInfo = NewTableSampleInfo(tn.TableSample, schema.Clone(), b.partitionedTable) b.isSampling = ds.SampleInfo != nil ... return result, nil}
在 buildDataSource 方法里面主要是根据表的原数据信息构建DataSource结构体。DataSource 主要记录了表的各种基础信息:
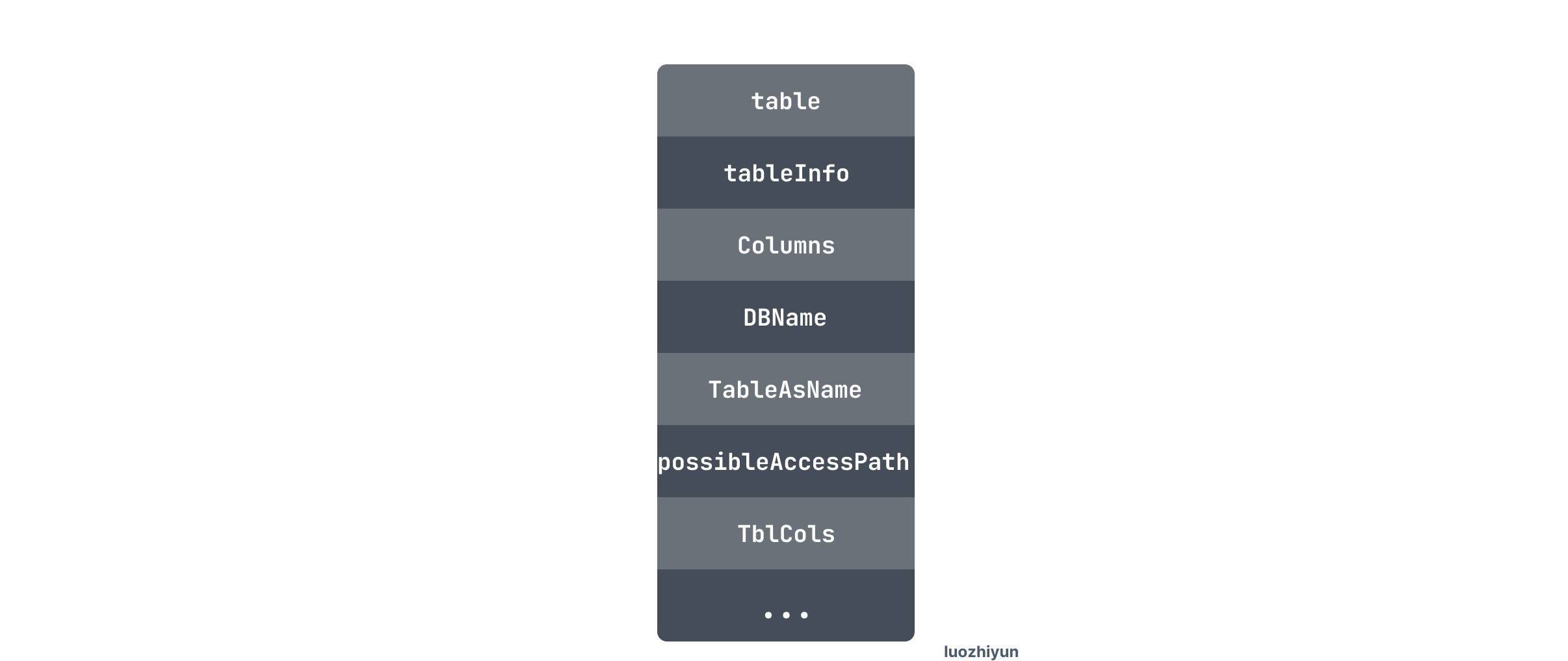
我这里暂时只讲解一下构建 DataSource 这个过程,其他的代码自己感兴趣的可以翻阅一下。
DoOptimize
下面我们再回到 optimize 函数中,在 builder.Build 构建完执行计划之后会调用 plannercore.DoOptimize,先执行逻辑优化,逻辑优化主要是基于规则的优化,简称 RBO(rule based optimization)。然后将逻辑计划基于代价优化(CBO)为一个物理计划,即 Cost-Based Optimization(CBO)的过程。
func DoOptimize(ctx context.Context, sctx sessionctx.Context, flag uint64, logic LogicalPlan) (PhysicalPlan, float64, error) { if flag&flagPrunColumns > 0 && flag-flagPrunColumns > flagPrunColumns { flag |= flagPrunColumnsAgain } // 首先是根据构建好的执行计划执行相应的逻辑优化 logic, err := logicalOptimize(ctx, flag, logic) if err != nil { return nil, 0, err } if !AllowCartesianProduct.Load() && existsCartesianProduct(logic) { return nil, 0, errors.Trace(ErrCartesianProductUnsupported) } planCounter := PlanCounterTp(sctx.GetSessionVars().StmtCtx.StmtHints.ForceNthPlan) if planCounter == 0 { planCounter = -1 } // 然后进行物理优化 physical, cost, err := physicalOptimize(logic, &planCounter) if err != nil { return nil, 0, err } // 最后再优化 finalPlan := postOptimize(sctx, physical) return finalPlan, cost, nil}
下面我们先看一下逻辑优化。
逻辑优化
func logicalOptimize(ctx context.Context, flag uint64, logic LogicalPlan) (LogicalPlan, error) { var err error // 遍历优化规则 for i, rule := range optRuleList { if flag&(1<<uint(i)) == 0 || isLogicalRuleDisabled(rule) { continue } // 执行优化 logic, err = rule.optimize(ctx, logic) if err != nil { return nil, err } } return logic, err}
逻辑优化会遍历所有的 optRuleList 优化规则,然后根据优化规则执行优化。目前 TIDB 中主要有这些优化规则:
var optRuleList = []logicalOptRule{ &gcSubstituter{}, &columnPruner{}, &buildKeySolver{}, &decorrelateSolver{}, &aggregationEliminator{}, &projectionEliminator{}, &maxMinEliminator{}, &ppdSolver{}, &outerJoinEliminator{}, &partitionProcessor{}, &aggregationPushDownSolver{}, &pushDownTopNOptimizer{}, &joinReOrderSolver{}, &columnPruner{}, // column pruning again at last, note it will mess up the results of buildKeySolver}
这里每一行都是一种优化器,例如gcSubstituter用于将表达式替换为虚拟生成列,以便于使用索引;columnPruner用于对列进行剪裁,即去除用不到的列,避免将他们读取出来,以减小数据读取量;aggregationEliminator能够在 group by {unique key} 时将不需要的聚合计算消除掉,以减少计算量;
下面看几个例子:
columnPruner 列裁剪
列剪裁主要是将算子中用不到的列去掉,以减少读取的总数据量,例如我们上面例子中的表查询所有学生的名字:
select sum(age) as total_age from student where name='pingcap' group by name;
对于这个 SQL 来说用到了 age,name 这几个字段,然后在构建 LogicalPlan 的时候 DataSource、LogicalSelection、LogicalAggregation、Projection 这几个算子都是有实现 PruneColumns 方法的:
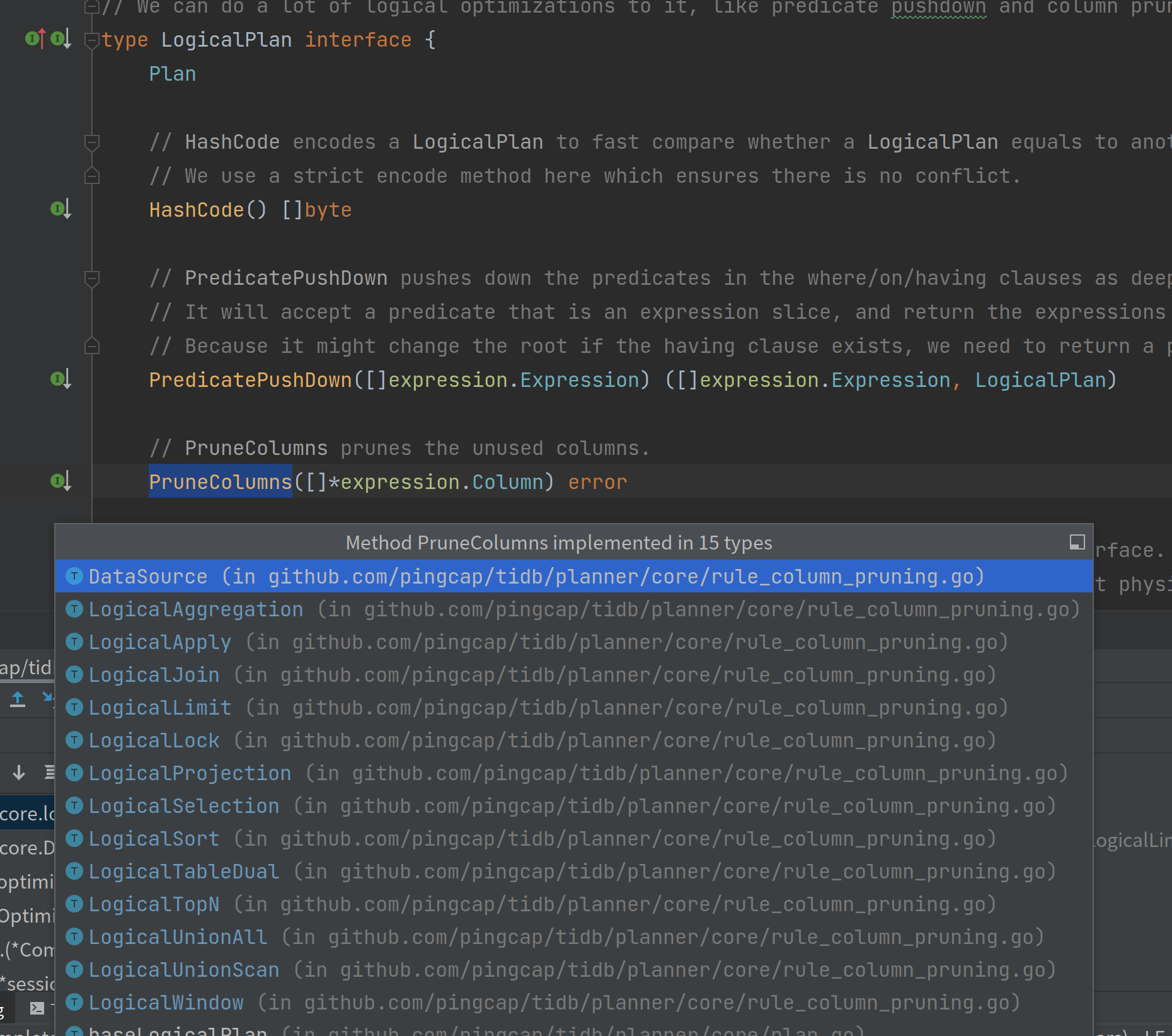
因此在执行 PruneColumns 方法的时候会递归执行嵌套的子方法,然后获取到所有用到的字段,去掉用不到的字段。
谓词下推 Predicate Push Down(PDD)
谓词下推的基本思想是将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。
例如下面这个简单的 SQL:
select * from student where name='pingcap';
在该查询中,将谓词name='pingcap'下推到 TiKV 上对数据进行过滤,可以减少由于网络传输带来的开销。
不过谓词下推还有很多局限性,例如 Limit 节点不能下推,毕竟先进行筛选,再 limit,和先 limit,再筛选是两个概念;以及外连接中内表上的谓词不能下推,因为外连接在不满足 on 条件时会对内表填充 NULL,不能直接过滤。
物理优化
这一阶段中,优化器会为逻辑执行计划中的每个算子选择具体的物理实现,以将逻辑优化阶段产生的逻辑执行计划转换成物理执行计划。
逻辑算子的不同对应的物理实现在时间复杂度、资源消耗和物理属性等方面也有不同。在这个过程中,优化器会根据数据的统计信息来确定不同物理实现的代价,并选择整体代价最小的物理执行计划。
例如我们这条 SQL :
select sum(age) as total_age from student where name='pingcap' group by name;
经过逻辑优化之后,会生成这样的逻辑计划:
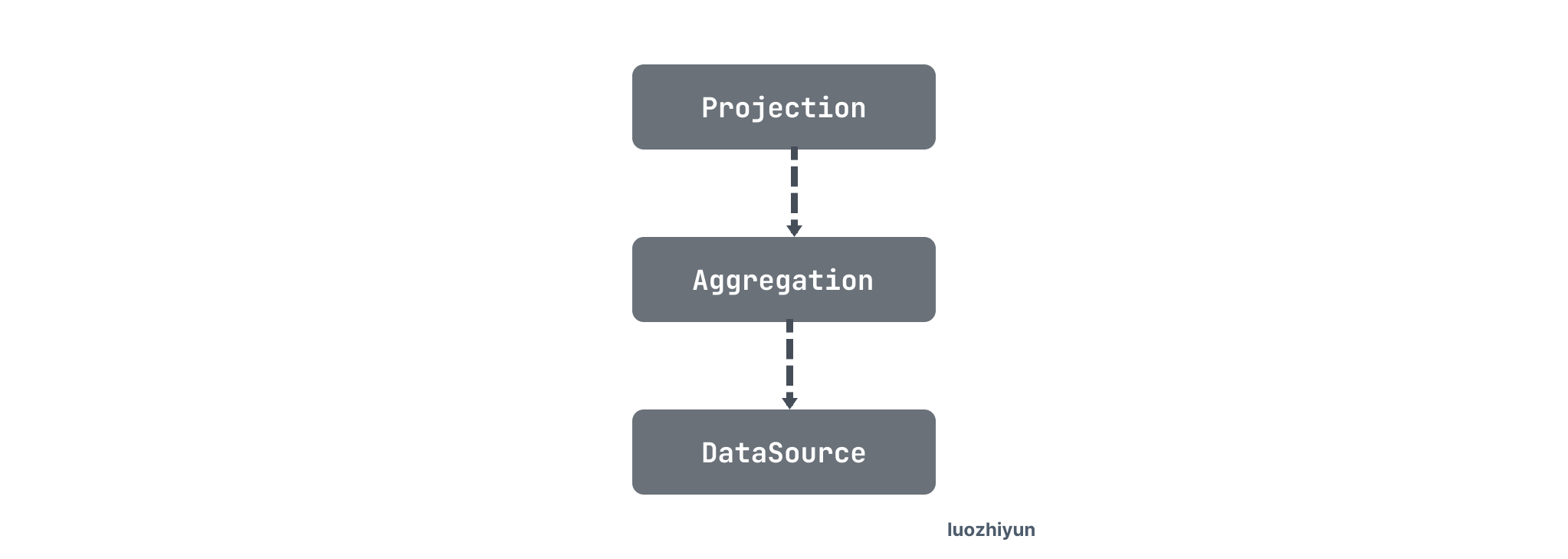
此语句中逻辑算子有 DataSource、Aggregation 和 Projection。例如对于 DataSource 来说在物理优化这个阶段需要选择是 IndexReader 通过索引读取数据,还是 TableReader 通过 row ID读取数据,亦或是 IndexLookUpReader 通过回表读取数据。
physicalOptimize
func physicalOptimize(logic LogicalPlan, planCounter *PlanCounterTp) (PhysicalPlan, float64, error) { // 用于存放每一个算子对接收到的下层返回数据的要求 prop := &property.PhysicalProperty{ TaskTp: property.RootTaskType, ExpectedCnt: math.MaxFloat64, } logic.SCtx().GetSessionVars().StmtCtx.TaskMapBakTS = 0 // 将逻辑计划转换为物理计划 t, _, err := logic.findBestTask(prop, planCounter) if err != nil { return nil, 0, err } ... return t.plan(), t.cost(), err}
findBestTask 会递归调用下层节点的 findBestTask 方法,生成物理算子并且估算其代价,然后从中选择代价最小的方案。
type LogicalPlan interface { // findBestTask converts the logical plan to the physical plan. It's a new interface. // It is called recursively from the parent to the children to create the result physical plan. // Some logical plans will convert the children to the physical plans in different ways, and return the one // With the lowest cost and how many plans are found in this function. // planCounter is a counter for planner to force a plan. // If planCounter > 0, the clock_th plan generated in this function will be returned. // If planCounter = 0, the plan generated in this function will not be considered. // If planCounter = -1, then we will not force plan. findBestTask(prop *property.PhysicalProperty, planCounter *PlanCounterTp) (task, int64, error) //..}
findBestTask 是 LogicalPlan 接口的一个方法,主要目的就是将逻辑计划转为物理计划。
func (p *baseLogicalPlan) findBestTask(prop *property.PhysicalProperty, planCounter *PlanCounterTp) (bestTask task, cntPlan int64, err error) { bestTask = p.getTask(prop) if bestTask != nil { planCounter.Dec(1) return bestTask, 1, nil } bestTask = invalidTask cntPlan = 0 newProp := prop.CloneEssentialFields() var plansFitsProp, plansNeedEnforce []PhysicalPlan var hintWorksWithProp bool // 返回该逻辑算子下面所有的物理计划 plansFitsProp, hintWorksWithProp, err = p.self.exhaustPhysicalPlans(newProp) if err != nil { return nil, 0, err } ... var cnt int64 var curTask task // 找到最优task if bestTask, cnt, err = p.enumeratePhysicalPlans4Task(plansFitsProp, newProp, false, planCounter); err != nil { return nil, 0, err } ...END: p.storeTask(prop, bestTask) return bestTask, cntPlan, nil}func (p *baseLogicalPlan) enumeratePhysicalPlans4Task(physicalPlans []PhysicalPlan, prop *property.PhysicalProperty, addEnforcer bool, planCounter *PlanCounterTp) (task, int64, error) { var bestTask task = invalidTask var curCntPlan, cntPlan int64 childTasks := make([]task, 0, len(p.children)) childCnts := make([]int64, len(p.children)) cntPlan = 0 for _, pp := range physicalPlans { childTasks = childTasks[:0] curCntPlan = 1 TimeStampNow := p.GetlogicalTS4TaskMap() savedPlanID := p.ctx.GetSessionVars().PlanID // 递归查找子task for j, child := range p.children { childTask, cnt, err := child.findBestTask(pp.GetChildReqProps(j), &PlanCounterDisabled) childCnts[j] = cnt if err != nil { return nil, 0, err } curCntPlan = curCntPlan * cnt if childTask != nil && childTask.invalid() { break } childTasks = append(childTasks, childTask) } if len(childTasks) != len(p.children) { continue } // 将子task加入到父task集合中 curTask := pp.attach2Task(childTasks...) ... // 计算代价 if curTask.cost() < bestTask.cost() || (bestTask.invalid() && !curTask.invalid()) { bestTask = curTask } } return bestTask, cntPlan, nil}
这里的物理计划都会返回 task 结构。
// task is a new version of `PhysicalPlanInfo`. It stores cost information for a task.
type task interface {
count() float64
addCost(cost float64)
cost() float64
copy() task
plan() PhysicalPlan
invalid() bool
}
task分两种, roottask在TiDB端执行
rootTaskis the final sink node of a plan graph. It should be a single goroutine on tidb.copTaskis a task that runs in a distributed kv store.
总结
在执行优化的过程非常的长,也是非常的复杂,这里只能说是抛砖引玉,大概的说说这一过程,很多细节跟到源码里面的时候非常难看懂,很多细节内容后面我再慢慢分析。
Reference
https://pingcap.com/blog-cn/tidb-source-code-reading-3
https://tech.meituan.com/2018/05/20/sql-parser-used-in-mtdp.html
https://pingcap.com/zh/blog/tidb-source-code-reading-5
https://pingcap.com/zh/blog/tidb-source-code-reading-6
https://pingcap.com/zh/blog/tidb-source-code-reading-7
https://pingcap.com/zh/blog/tidb-source-code-reading-8
https://zhuanlan.zhihu.com/p/373889188
https://lenshood.github.io/2020/10/03/tidb-lesson-6/
https://github.com/xieyu/blog/blob/master/src/tidb/datasource-physical-optimize.md
