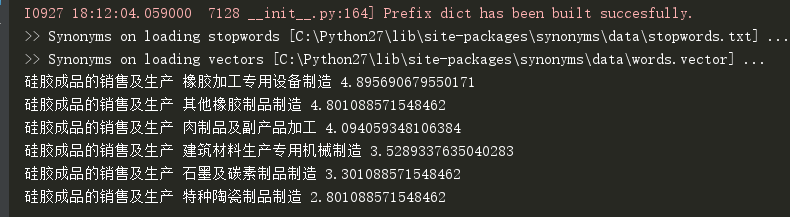
synonyms自带的相似度比较结果并不能满意。
以下提高了名词分数占比,随便写的,错误之处请指正
主要代码
# encoding=utf8
import synonyms,jieba,re
jieba.load_userdict('mydict.txt')
sen1 = "硅胶成品的销售及生产"
temp2 = ['橡胶加工专用设备制造', '石墨及碳素制品制造', '其他橡胶制品制造', '建筑材料生产专用机械制造', '肉制品及副产品加工', "特种陶瓷制品制造"]
def getWordType(word):
w,t = synonyms.seg(word)
return t[0]
# 去重、排序
def deal_list(objs, order='name', isLen=True, reverse=False):
temp,result = {},[]
for obj in objs:
temp[obj[order]] = obj
for prpo in temp:
result.append(temp[prpo])
if isLen:
return sorted(result, key=lambda obj: len(obj[order]))
return sorted(result, key=lambda obj: obj[order], reverse=reverse)
def wordCompare(instr, sentences):
result = []
keys = {}
words,types = synonyms.seg(instr)
for i,w1 in enumerate(words):
keys[w1] = []
if re.findall('[vn]+', types[i]) and len(w1)>1:
ws,ss = synonyms.nearby(w1)
for j,w2 in enumerate(ws):
if ss[j]<0.6:
break
keys[w1].append({
'text': w2,
'source': ss[j],
'typeSource': 2 if re.findall('[vn]+', getWordType(w2)) else 0.5
})
if len(keys[w1])==0:
keys[w1].append({
'text': w1,
'source': 1,
'typeSource': 2 if re.findall('[vn]+', getWordType(w1)) else 0.5 #名词类得分加倍,其它对折
})
for i in sentences:
source = 0
for j in keys:
bfSource = 1 #降低同一个词的同义词影响
for k in keys[j]:
if k['text'] in i:
source += (bfSource*k['source']*k['typeSource'])
bfSource = k['source']
result.append({
'text': i,
'source': source
})
return result
if __name__ == '__main__':
temp2 = deal_list(wordCompare(sen1, temp2), order='source', isLen=False, reverse=True)
for i in temp2:
print sen1, i['text'], i['source']
mydict.txt
运行结果