python 2 控制台传参,需要从sys模块中导入argv,argv返回的第一个参数当前脚本(script)的文件名,后面是参数,参数个数必须和解包(unpack)时使用的参数个数一致
1.本例子演示了Python 2 如何用控制台传入参数到脚本中去的过程
转载请声明本文的引用出处:仰望大牛的小清新
如下
1 #python 2 2 # -*- coding: utf-8 -*- 3 from __future__ import unicode_literals 4 from sys import argv 5 print "变量,解包,参数的练习" 6 7 script, first, second, third = argv # unpack,运行时需要从控制台传入3个参数 8 9 print "This script is called: ", script 10 print "Your first variable is: ", first 11 print "Your second variable is : ", second 12 print "Your third variable is: ", third
传参如下
py -2 ex13.py variable1, "a string" 5
输出如图

可以看到,逗号也被作为参数输入了,而空格则没有,同时,字符串的输出也使用了默认的格式,参数被成功传入脚本。
2.关于传参数中输入中文会出错的问题
例子1中的代码在控制台输入中文时没有问题,但是如果使用formatters,例如%s,则会报错
对于这样的代码:
1 # python 2 2 #使用了formatters来输出中文, 会报错 3 4 script, user_name = argv 5 print "Hi %s, I'm the %s script." % (user_name, script)
会产生如下报错

python的默认编码格式可以在控制台进行查看和修改,方法如下
1 # python 2 2 # 获取Python解释器默认的编码方式并改变 3 import sys 4 print sys.getdefaultencoding() #输出默认编码 5 --------------------------------------------------------------- 6 # 改变默认编码为utf-8 7 import sys 8 reload(sys) 9 sys.setdefaultencoding('utf8')
同时,用cmd输入中文,并将该输入写入文件也会出现乱码的情况,此时字符串的encode和decode方法均会报错,此时,上述reload sys的方法则可以有效解决这一问题,这里需要特别注意。
回到正题,然而,即便我设置了python解释器的默认编码,仍然产生上述报错,错误如下

这使我开始思考,恐怕我的系统默认字符集不是utf-8
于是我查看了系统的字符集,查看流程如下:
1.打开cmd
2.右键->属性
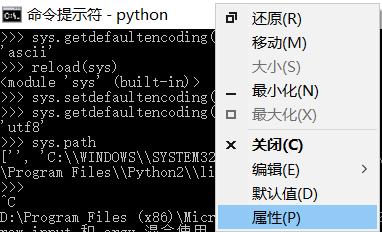
发现我的字符集是。。。GBK
![]()
这就很尴尬了。。。因此将编码修改为gbk,就ok了
完整代码如下:
1 # -*- coding: utf-8 -*- 2 # python 2 3 from __future__ import unicode_literals 4 print "raw_input 和 argv 混合使用" 5 6 import sys 7 reload(sys) 8 sys.setdefaultencoding('gbk')# 我的系统默认的编码,也是cmd传参时使用的编码 9 10 from sys import argv 11 script, user_name = argv 12 prompt = '>' 13 14 print "Hi %s, I'm the %s script." % (user_name, script) 15 print "I'd like to ask you a few questions." 16 17 print "Do you like me %s?" % user_name 18 likes = raw_input(prompt) 19 20 print "Where do you live %s?" % user_name 21 lives = raw_input(prompt) 22 23 print "What kind of computer do you have?" 24 computer = raw_input(prompt) 25 26 print """ 27 Alright, so you said %r about liking me. 28 You live in %r. Not sure where that is. 29 And you have a %r computer. Nice. 30 """ % (likes, lives, computer)
3.如何不修改该源码直接设置python解释器的默认编码
我们可以在每个源码文件的开头直接设置编码为utf-8,但是我们也可以更加方便的直接将python的默认字符集从ascii改为utf-8
方法如下:
3.1首先,我们导入sys包,并通过sys包中的path寻找我们python解释器的lib所在路径
1 # -*- coding: utf-8 -*- 2 #python 2 3 4 import sys 5 print sys.path
在我的电脑上输出如下:

3.2检查输出,可以看到这里有 D:\Program Files\Python2\lib。lib文件夹下的site.py里面的setencoding函数就是解决编码问题的关键。
默认的site.py文件中setencoding函数如下:
1 def setencoding(): 2 """Set the string encoding used by the Unicode implementation. The 3 default is 'ascii', but if you're willing to experiment, you can 4 change this.""" 5 encoding = "ascii" # Default value set by _PyUnicode_Init() 6 if 0: 7 # Enable to support locale aware default string encodings. 8 import locale 9 loc = locale.getdefaultlocale() 10 if loc[1]: 11 encoding = loc[1] 12 if 0: 13 # Enable to switch off string to Unicode coercion and implicit 14 # Unicode to string conversion. 15 encoding = "undefined" 16 if encoding != "ascii": 17 # On Non-Unicode builds this will raise an AttributeError... 18 sys.setdefaultencoding(encoding) # Needs Python Unicode build !
通过我们将encoding根据我们的需要改为utf-8,或者gbk,重启python解释器,即可更改默认设置,同时不需要修改代码
这个方法在工程中更为合适,避免因为一时疏忽而产生大量的报错信息
以更改为utf-8为例,更改后的setencoding如下
总共更改了2处:encoding和比较处的ascii为utf-8,在下面代码中以行末注释形式进行了提醒
1 def setencoding(): 2 """Set the string encoding used by the Unicode implementation. The 3 default is 'ascii', but if you're willing to experiment, you can 4 change this.""" 5 encoding = "utf-8" # Default value set by _PyUnicode_Init() #这里要改 6 if 0: 7 # Enable to support locale aware default string encodings. 8 import locale 9 loc = locale.getdefaultlocale() 10 if loc[1]: 11 encoding = loc[1] 12 if 0: 13 # Enable to switch off string to Unicode coercion and implicit 14 # Unicode to string conversion. 15 encoding = "undefined" 16 if encoding != "ascii": # 这里也要改 17 # On Non-Unicode builds this will raise an AttributeError... 18 sys.setdefaultencoding(encoding) # Needs Python Unicode build !
这样就可以避免在代码文件中重新加载sys模块进行设置了
4.文件输入输出中的编码问题
对于控制台传参,用上述方法就可以解决,但是对于文件输入输出的编码问题,仍不能这样解决
但是我们可以通过两种方式来解决,如下
1 # python 2 2 # 导入codecs模块,并使用模块中的open方法 3 import codecs 4 txt = codecs.open(filename,'r','utf-8') 5 6 #------------------------------------------------------- 7 8 # python 2 9 # 使用decode方法指定编码的解释方法 10 txt = open(filename) 11 print txt.read().decode('utf-8')
5.关于何时关闭文件句柄的问题
1 open(to_file,'w').write(open(from_file).read())#如果简写,那么我们不需要执行文件关闭操作
谢谢大家~~~撒花撒花*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。