"mappings": { "player": { "properties": { "name": { "index": "not_analyzed", "type": "string" }, "age": { "type": "integer" }, "salary": { "type": "integer" }, "team": { "index": "not_analyzed", "type": "string" }, "position": { "index": "not_analyzed", "type": "string" } }, "_all": { "enabled": false } } }
索引中的全部数据:
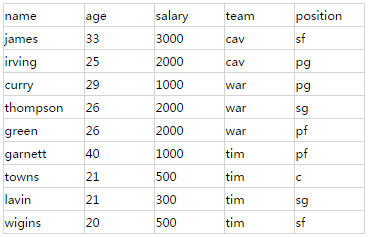
首先,初始化Builder:
SearchRequestBuilder sbuilder = client.prepareSearch("player").setTypes("player");
接下来举例说明各种聚合操作的实现方法,因为在es的api中,多字段上的聚合操作需要用到子聚合(subAggregation),初学者可能找不到方法(网上资料比较少,笔者在这个问题上折腾了两天,最后度了源码才彻底搞清楚T_T),后边会特意说明多字段聚合的实现方法。另外,聚合后的排序也会单独说明。
- group by/count
例如要计算每个球队的球员数,如果使用SQL语句,应表达如下:
select team, count(*) as player_count from player group by team;
ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
sbuilder.addAggregation(teamAgg);
SearchResponse response = sbuilder.execute().actionGet();
- group by多个field
例如要计算每个球队每个位置的球员数,如果使用SQL语句,应表达如下:
select team, position, count(*) as pos_count from player group by team, position;
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
TermsBuilder posAgg= AggregationBuilders.terms("pos_count").field("position");
sbuilder.addAggregation(teamAgg.subAggregation(posAgg));
SearchResponse response = sbuilder.execute().actionGet();
- max/min/sum/avg
例如要计算每个球队年龄最大/最小/总/平均的球员年龄,如果使用SQL语句,应表达如下:
select team, max(age) as max_age from player group by team;
ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
MaxBuilder ageAgg= AggregationBuilders.max("max_age").field("age");
sbuilder.addAggregation(teamAgg.subAggregation(ageAgg));
SearchResponse response = sbuilder.execute().actionGet();
- 对多个field求max/min/sum/avg
例如要计算每个球队球员的平均年龄,同时又要计算总年薪,如果使用SQL语句,应表达如下:
select team, avg(age)as avg_age, sum(salary) as total_salary from player group by team;
ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("team");
AvgBuilder ageAgg= AggregationBuilders.avg("avg_age").field("age");
SumBuilder salaryAgg= AggregationBuilders.avg("total_salary ").field("salary");
sbuilder.addAggregation(teamAgg.subAggregation(ageAgg).subAggregation(salaryAgg));
SearchResponse response = sbuilder.execute().actionGet();
- 聚合后对Aggregation结果排序
例如要计算每个球队总年薪,并按照总年薪倒序排列,如果使用SQL语句,应表达如下:
select team, sum(salary) as total_salary from player group by team order by total_salary desc;
ES的java api:
TermsBuilder teamAgg= AggregationBuilders.terms("team").order(Order.aggregation("total_salary ", false);
SumBuilder salaryAgg= AggregationBuilders.avg("total_salary ").field("salary");
sbuilder.addAggregation(teamAgg.subAggregation(salaryAgg));
SearchResponse response = sbuilder.execute().actionGet();
需要特别注意的是,排序是在TermAggregation处执行的,Order.aggregation函数的第一个参数是aggregation的名字,第二个参数是boolean型,true表示正序,false表示倒序。
- Aggregation结果条数的问题
默认情况下,search执行后,仅返回10条聚合结果,如果想反悔更多的结果,需要在构建TermsBuilder 时指定size:
TermsBuilder teamAgg= AggregationBuilders.terms("team").size(15);
- Aggregation结果的解析/输出
得到response后:
Map<String, Aggregation> aggMap = response.getAggregations().asMap(); StringTerms teamAgg= (StringTerms) aggMap.get("keywordAgg"); Iterator<Bucket> teamBucketIt = teamAgg.getBuckets().iterator(); while (teamBucketIt .hasNext()) { Bucket buck = teamBucketIt .next(); //球队名 String team = buck.getKey(); //记录数 long count = buck.getDocCount(); //得到所有子聚合 Map subaggmap = buck.getAggregations().asMap(); //avg值获取方法 double avg_age= ((InternalAvg) subaggmap.get("avg_age")).getValue(); //sum值获取方法 double total_salary = ((InternalSum) subaggmap.get("total_salary")).getValue(); //... //max/min以此类推 }
- 总结
综上,聚合操作主要是调用了SearchRequestBuilder的addAggregation方法,通常是传入一个TermsBuilder,子聚合调用TermsBuilder的subAggregation方法,可以添加的子聚合有TermsBuilder、SumBuilder、AvgBuilder、MaxBuilder、MinBuilder等常见的聚合操作。
从实现上来讲,SearchRequestBuilder在内部保持了一个私有的
SearchSourceBuilder实例,
SearchSourceBuilder内部包含一个List<AbstractAggregationBuilder>,每次调用addAggregation时会调用
SearchSourceBuilder实例,添加一个AggregationBuilder。
同样的,TermsBuilder也在内部保持了一个List<AbstractAggregationBuilder>,调用addAggregation方法(来自父类addAggregation)时会添加一个AggregationBuilder。有兴趣的读者也可以阅读源码的实现。