爬虫采集下来的数据除了存储在文本文件、excel之外,还可以存储在数据集,如:Mysql,redis,mongodb等,今天辰哥就来教大家如何使用Python连接Mysql,并结合爬虫为大家讲解。
前提:这里默认大家已经安装好mysql。
01 Mysql简介
1.安装pymysql
通过下面这个命令进行安装
pip install pymysql
pymysql库:Python3链接mysql
备注:
ps:MYSQLdb只适用于python2.x
python3不支持MYSQLdb,取而代之的是pymysql
运行会报:ImportError:No module named 'MYSQLdb'
2.python连接mysql
import pymysql as pmq #connect(ip.user,password,dbname) con = pmq.connect('localhost','root','123456','python_chenge') #操作游标 cur = con.cursor()
localhost是本机ip,这里用localhost表示是当前本机,否则将localhost改为对应的数据库ip。
root是数据库用户名,123456是数据库密码,python_chenge是数据库名。
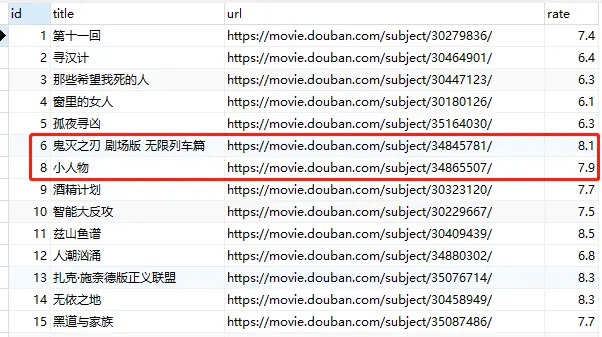
图上的数据库python_chenge已经建立好(建好之后,才能用上面代码去连接),建好之后,当前是没有表的,现在开始用Python进行建表,插入、查询,修改,删除等操作(结合爬虫去讲解)
02 建表
在存储之前,先通过python创建表,字段有四个(一个主键+电影名称,链接,评分)
# 创建 movie 表 movie_sql= ''' create table movie( id int AUTO_INCREMENT primary key not null, title varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci not null, url varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci not null, rate float not null ) ''' # 执行sql语句 cur.execute(movie_sql) # 提交到数据库执行 con.commit()
创建表movie,字段分别为(id ,title ,url ,rate ),CHARACTER SET utf8 COLLATE utf8_general_ci是字符串编码设置为utf8格式
id是主键primary key,int类型,AUTO_INCREMENT自增,非空not null
title,url 是字符串类型varchar(100),同样非空
评分rate 是带小数的数字,所以是float,同样非空

03 插入数据
爬虫已经采集到数据,python已经建好表,接着可以将采集的数据插入到数据库,这里介绍两种方式
### 插入数据 def insert(title,url,rate): # 插入数据一 #cur.execute("INSERT INTO movie(title,url,rate) VALUES('"+str(title)+"','"+str(url)+"',"+str(rate)+")") # 插入数据二 sql = "INSERT INTO movie(title,url,rate) VALUES('"+str(title)+"','"+str(url)+"',"+str(rate)+")" cur.execute(sql) # 提交到数据库执行 con.commit()
id是自增的,所以不需要在传值进去。
定义好插入数据库方法后,开始往数据库进行存储
for i in json_data['subjects']: insert(i['title'],i['url'],i['rate'])
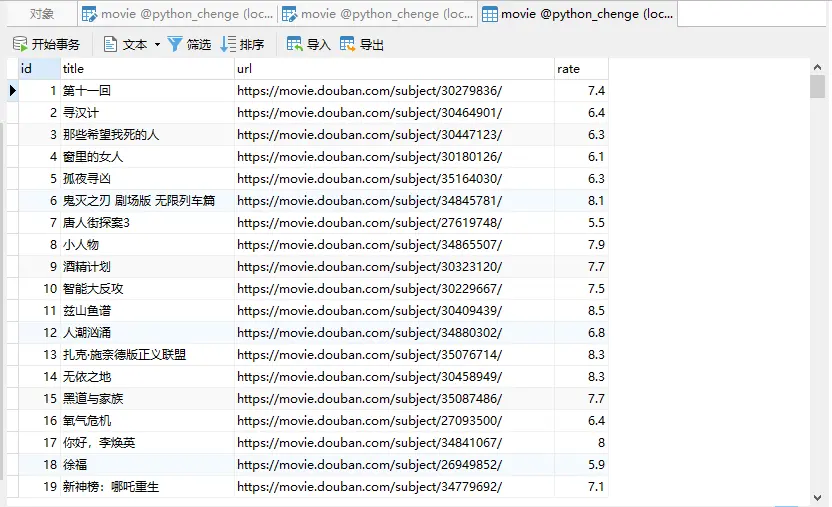
04 查询
1.查询所有
查询表中所有数据
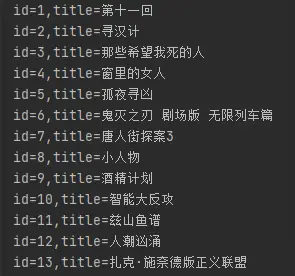
# 查询 cur.execute('select * from movie') results = cur.fetchall() for row in results: Id = row[0] title = row[1] print("id=%s,title=%s" % (Id, title))
2.查询指定的数据
比如查询标题为:唐人街3这一条数据的所有字段
#查询单条 cur.execute('select * from movie where title="唐人街探案3"') results = cur.fetchall() for row in results: Id = row[0] title = row[1] url = row[2] rate = row[3] print("id=%s,title=%s,url=%s,rate=%s" % (Id, title,url,rate))

05 更新修改
更新数据,还是以上面:唐人街3为例,id为7,将唐人街3评分从5.5改为6
### 更新 def update(): sql = "update movie set rate='6' where Id = {0}".format(7) cur.execute(sql) con.commit()

同时看一下数据库
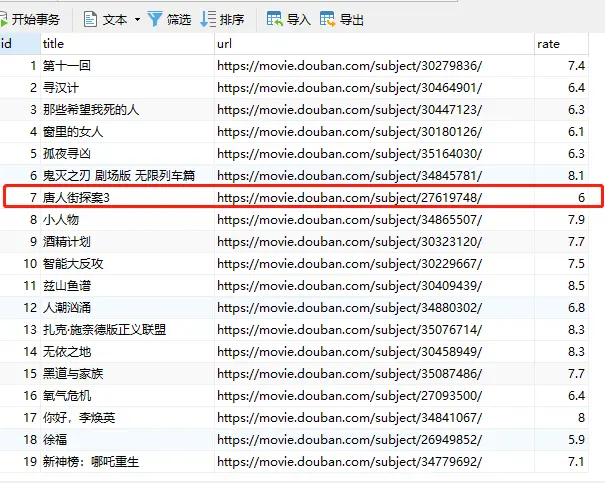
06 删除
同样还是以唐人街为例,其id为7,删除的话咱们可以更新id去删除
def delete(Id): sql = "delete from movie where Id = {0}".format(Id) cur.execute(sql) con.commit()