一、非贪婪匹配
首先先看一个需求,我们的输入是一串数字字符串,我们需要做的是它最后面的所有0字符和0前面的子串提取出来,例如:
"123000":"123"和"000""110":"11"和"0""1234":"1234"和""
我们很自然地可以写出这样的表达式:^(d*)(0*)$
可是如果这样写匹配的结果和我们想象的是一样吗?
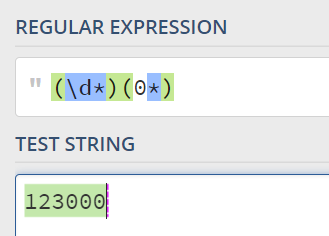
可以发现,分解的结果为:"123000"和"",与我们的想象完全不同。
产生这样的结果的原因是:正则表达式默认使用贪婪匹配,任何一个规则,它总是尽可能多地向后匹配,因此,d+总是会把后面的0包含进来。
而我们需要做的是使d*尽量少匹配,而0*尽量多地匹配,这就需要使用到非贪婪匹配了,其含义即为使表达式尽量少地向后匹配。使用的方式是在某个量词后面加上?,即原来的正则表达式需要修改为:^(d*?)(0*)$,这样我们的匹配结果为:
可以发现现在得到的结果就是完全符合需求了。
| 输入串 | 结果 |
|---|---|
"123000" |
  |
"110" |
  |
"1234" |
  |