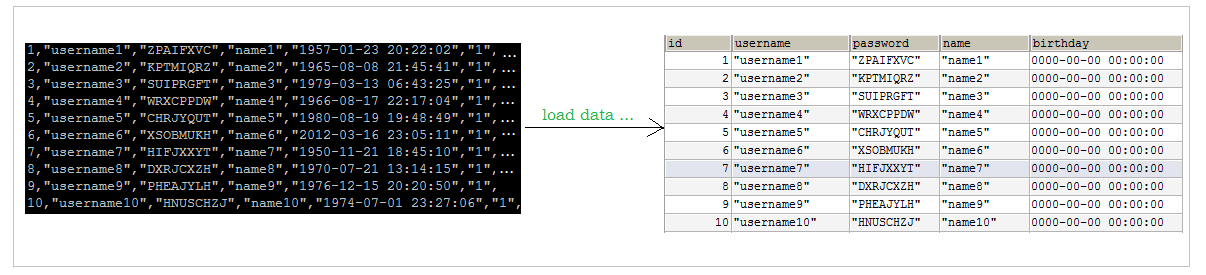
1.load方式导入本地数据
1.环境准备
创建表:


CREATE TABLE `tb_user_2` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(45) NOT NULL, `password` varchar(96) NOT NULL, `name` varchar(45) NOT NULL, `birthday` datetime DEFAULT NULL, `sex` char(1) DEFAULT NULL, `email` varchar(45) DEFAULT NULL, `phone` varchar(45) DEFAULT NULL, `qq` varchar(32) DEFAULT NULL, `status` varchar(32) NOT NULL COMMENT '用户状态', `create_time` datetime NOT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_user_username` (`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
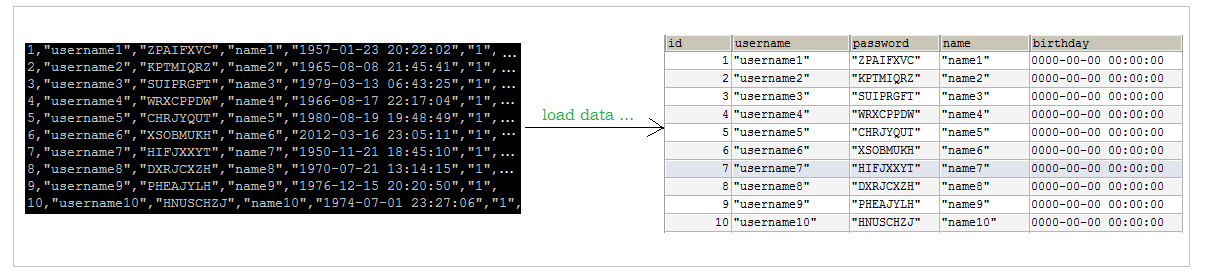
例如我们现在有两个数据脚本文件(每个文件有1000000条数据):
对应文件下载地址:链接:https://pan.baidu.com/s/1RPIuingODnusvi_R_N8YPQ
提取码:1111
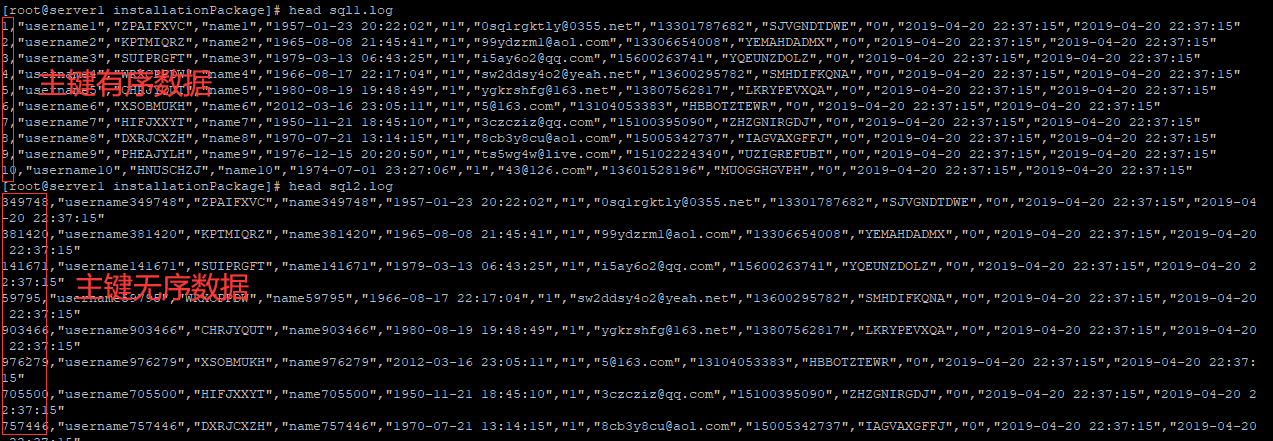
脚本文件介绍 : sql1.log ----> 主键有序 sql2.log ----> 主键无序
导入数据
那么我们可以在mysql中直接使用下面的命令将上面两个数据文件的数据导入到我们上面创建的两个表中:tb_user_1,tb_user_2;
load data local infile '/usr/local/installationPackage/sql1.log' into table `tb_user_1` fields terminated by ',' lines terminated by ' ';
导入有序主键数据:

导入无序主键数据:

可见,在导入外部数据的时候我们尽量使用顺序主键数据;
优化:
2) 关闭唯一性校验

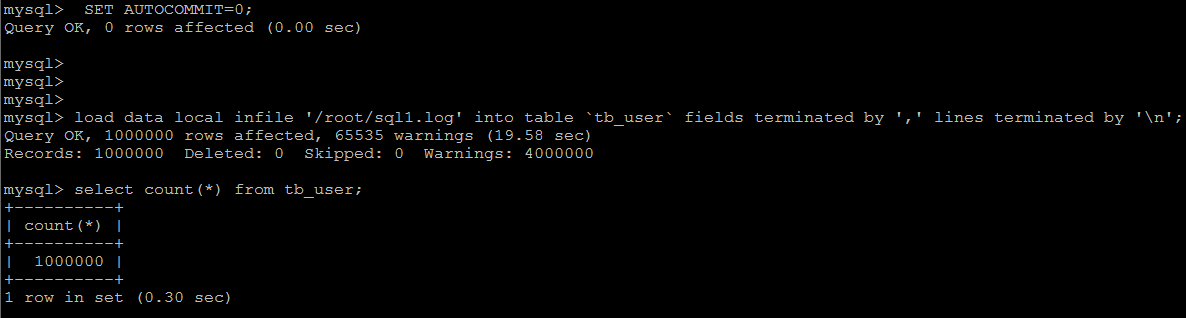
如果应用使用自动提交的方式,建议在导入前执行 SET AUTOCOMMIT=0,关闭自动提交,导入结束后再执行 SET AUTOCOMMIT=1,打开自动提交,也可以提高导入的效率。
2.存储过程批量导入数据
1.环境准备
创建表:
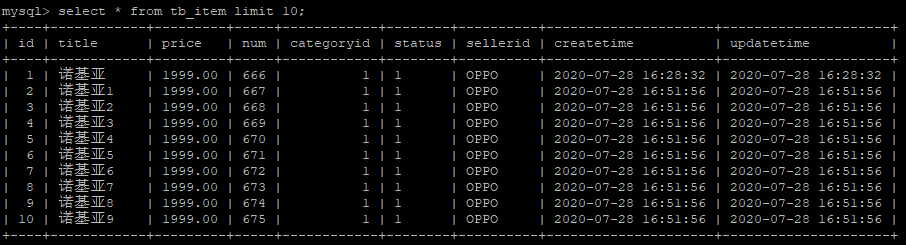
CREATE TABLE `tb_item` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品id', `title` varchar(100) NOT NULL COMMENT '商品标题', `price` decimal(20,2) NOT NULL COMMENT '商品价格,单位为:元', `num` int(10) NOT NULL COMMENT '库存数量', `categoryid` bigint(10) NOT NULL COMMENT '所属类目,叶子类目', `status` varchar(1) DEFAULT NULL COMMENT '商品状态,1-正常,2-下架,3-删除', `sellerid` varchar(50) DEFAULT NULL COMMENT '商家ID', `createtime` datetime DEFAULT NULL COMMENT '创建时间', `updatetime` datetime DEFAULT NULL COMMENT '更新时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';
然后我们都知道,我们插入一条数据可以使用:
insert into tb_item values (1,'诺基亚',1999,666,1,'1','OPPO',now(),now());
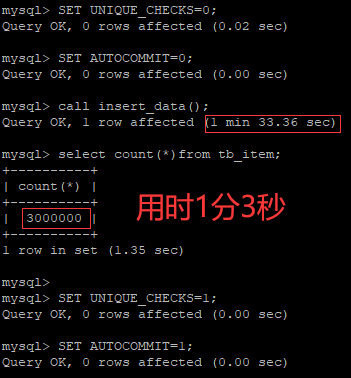
那么我们把上面语句写到存储过程循环执行3000000次,然后调用存储过程,不就可以插入3000000个数据了吗?
delimiter $ create procedure insert_data() begin declare i int default 1; while (i<3000000) do insert into tb_item values (null,concat('诺基亚',i),1999,666+i,1,'1','OPPO',now(),now()); set i=i+1; end while; end$ delimiter ;
调用存储过程之前我们最好执行上面提到的优化操作:
SET UNIQUE_CHECKS=0;
SET AUTOCOMMIT=0;