一、问题
客户反馈,业务hang死,创建问题时段awr,top event 是checkpoint incomplete
1.1、awr,top event
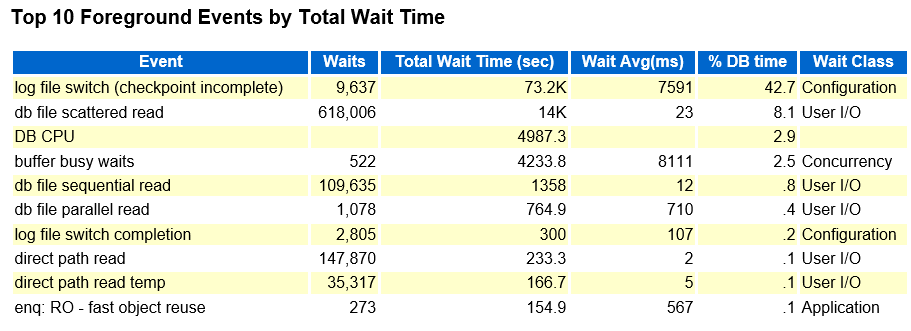
可以发现是log file switch(checkpoint incomplete) 这个等待事件是指current log file 写满,需要切换创建归档日志,但是需要覆盖的旧的日志文件里面对应的脏块并未写入磁盘,ckpt未完成导致日志无法切换,业务的dml操作就被hang住了。
根据上面的理论知识,问题的可能性有2:
1.日志文件日志组数量太少,在业务频繁的dml产生大量redo容易造成日志非常快速的写满,让IO的压力很大且很集中【方法就是增加日志组里面日志文件的大小,增加日志组数量,让IO的操作时间延长,达到分散的目的】;
2.存储性能太差,导致ckpt检查点无法完成数据写入的动作;
1.2 日志切换,及日志组调整
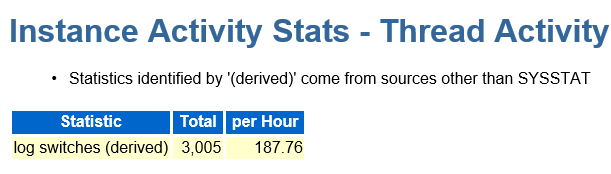
total=3005是因为这个awr创建是00~16 16个小时!!!,但是即使如此,per Hour 每小时切换187次!!! 3分钟不到切换一次! Oracle Mos有建议无明确规定,建议是15~30分钟切换一次。
日志组3组,日志文件单个50M,属于数据库11.2.0.4 安装的默认大小,对其进行调整。
新增6组500M日志文件,删除原3组50M日志文件【单实例删除日志组并不会删除操作系统日志,但是为了安全可以不擅长日志文件,保留即可】
1.3 IO效率

可以发现log file parallel write avg(ms)=5 不算太差,也不算太好的IO效率
db file sequentail read,db file single write avg(ms)分别是3,2 不算差;
db file async i/o submit 业务的dml操作被log file swith(checkpoint incomplete)阻塞无法作为IO效率查询,log file switch(checkpoint incomplete)同样如此。
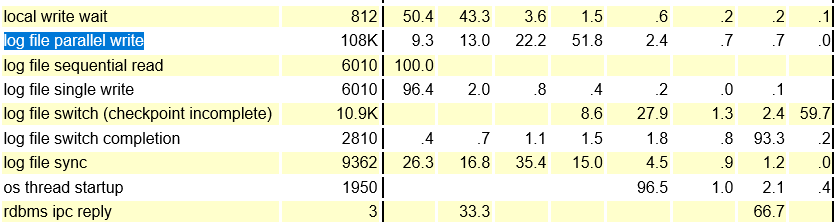
4ms <log file parallel write 51.8% <8ms 说明IO效率真的不高!!! 而且此awr还是00~16:00 存在空闲期见高效率io 稀释的情况。
二、总结
1.日志组3组,日志文件单个50M,属于数据库11.2.0.4 安装的默认大小,对其进行调整。
新增6组500M日志文件,删除原3组50M日志文件【单实例删除日志组并不会删除操作系统日志,但是为了安全可以不擅长日志文件,保留即可】
2.对Oracle 存储进行更换,使用更好更快的存储! 或者让日志文件放在更好的存储上!