采集小红书数据爬虫:
1.本来是要通过app端的接口去直接采集数据,但是app接口手机端设置本地代理这边开启抓包后就不能正常访问数据。
所以就采用了微信小程序里的小红书app接口去采集数据。
2.通过 fiddler去抓包,手机端进入小程序端口选择彩妆向下滑动请求数据,这边fiddler就会抓到请求数据和相应的response。

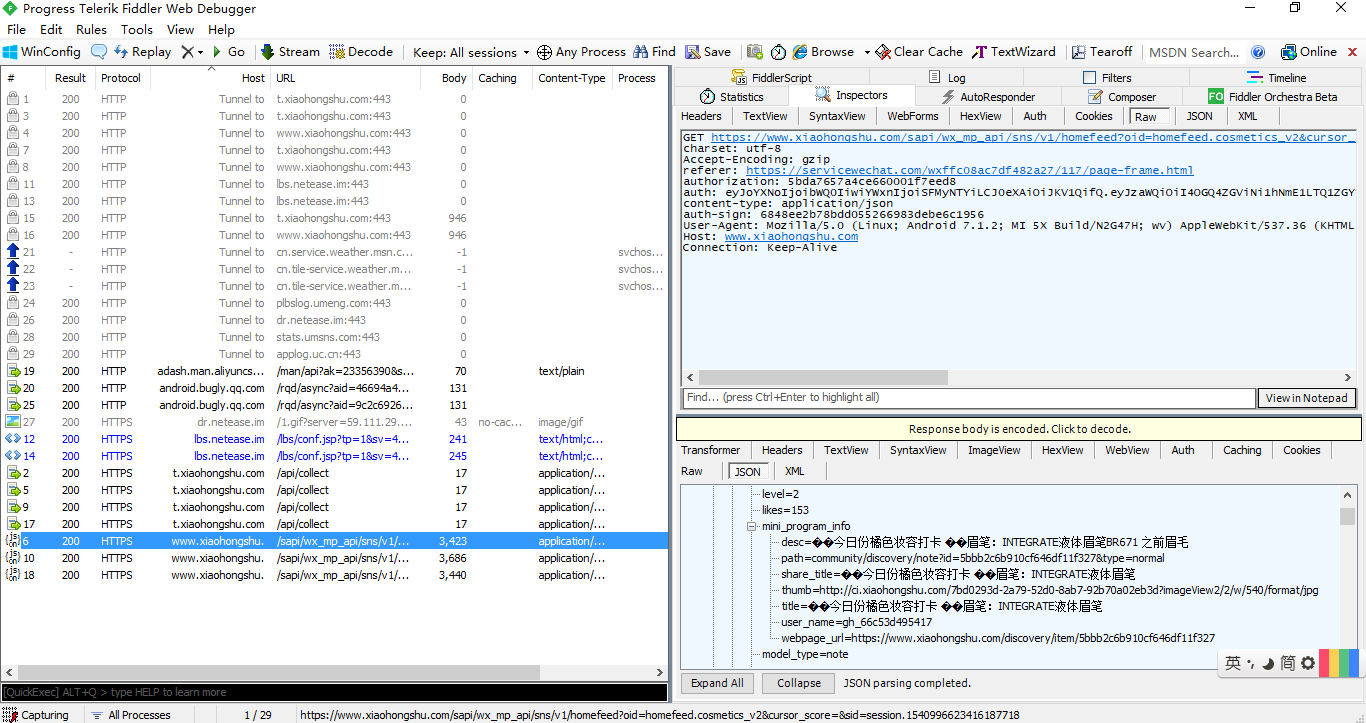
由上边的两图可以看到请求的一个过程,这里每次单击拖动只会更新10条数据(数据包含在data{}里),下面就要对请求的header参数进行分析。

3.经过分析 主要参数包含
"auth":"eyJoYXNoIjoibWQ0IiwiYWxnIjoiSFMyNTYiLCJ0eXAiOiJKV1QifQ.eyJzaWQiOiI5M2JhM2Q3MC03MWJhLTQzOGYtODhiNC03MDNiZDZlNDRkNjYiLCJleHBpcmUiOjE1NDEwNjkyNTJ9.MIolGQY-A-j-n2cxDYKeN9ILh4gBaYMHUWiA0IRJILQ"
"auth-sign":"13c136011f62d6bc0e7d2bf1f7f04201",
而且参数还具有一个时效性,请求的一段时间内是能够返回得到有效数据的。
这里呢,暂时未做分析只是先把10条数据先拿下来试试,稍后再做处理。
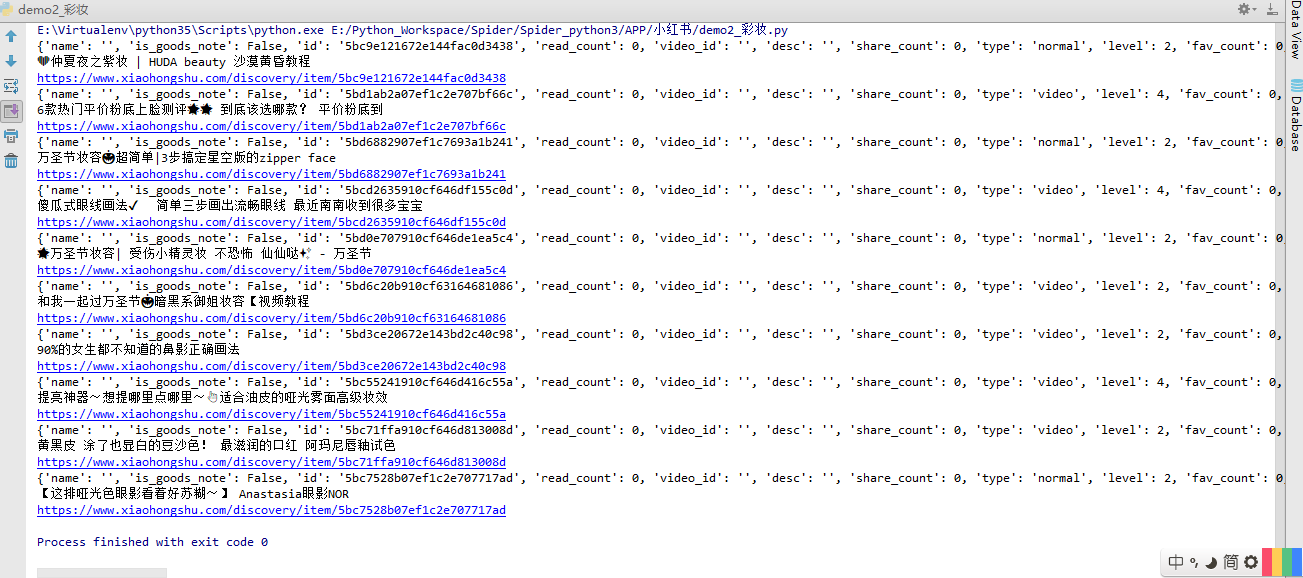
import requests def main(): headers = { "charset":"utf-8", "Accept-Encoding":"gzip", "referer":"https://servicewechat.com/wxffc08ac7df482a27/117/page-frame.html", "authorization":"5bda7657a4ce660001f7eed8", "auth":"eyJoYXNoIjoibWQ0IiwiYWxnIjoiSFMyNTYiLCJ0eXAiOiJKV1QifQ.eyJzaWQiOiI5M2JhM2Q3MC03MWJhLTQzOGYtODhiNC03MDNiZDZlNDRkNjYiLCJleHBpcmUiOjE1NDEwNjkyNTJ9.MIolGQY-A-j-n2cxDYKeN9ILh4gBaYMHUWiA0IRJILQ", "content-type":"application/json", "auth-sign":"13c136011f62d6bc0e7d2bf1f7f04201", "User-Agent":"Mozilla/5.0 (Linux; Android 7.1.2; MI 5X Build/N2G47H; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/64.0.3282.137 Mobile Safari/537.36 MicroMessenger/6.7.3.1360(0x26070336) NetType/WIFI Language/zh_CN Process/appbrand2", "Host":"www.xiaohongshu.com", "Connection":"Keep-Alive", } url = "http://www.xiaohongshu.com/sapi/wx_mp_api/sns/v1/homefeed?oid=homefeed.cosmetics_v2&cursor_score=1541067389.9540&sid=session.1540996623416187718" datas = requests.get(url= url, headers=headers ).json() data = datas['data'] # print(data) for i in data: print(i) print(i['title']) print(i['share_link']) if __name__ == "__main__": main()
结果如图:
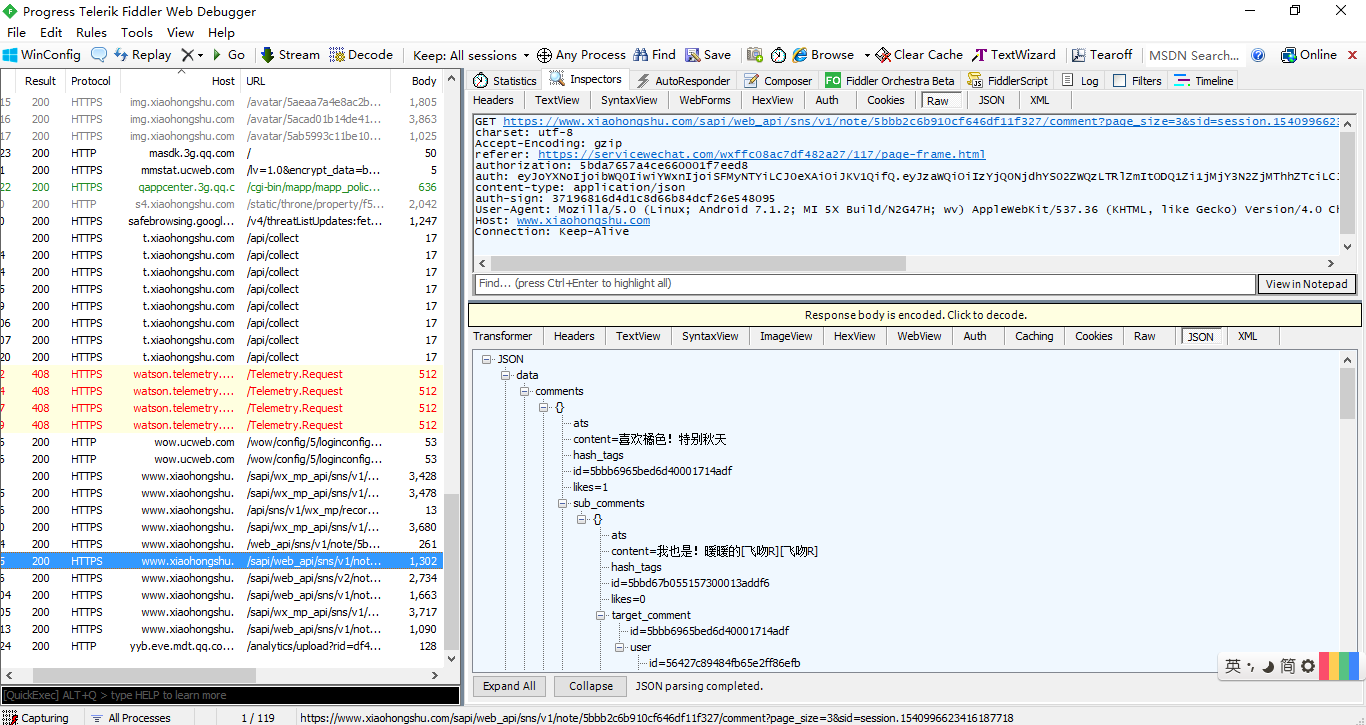
4.进入单个tag的详情页:
评论
5.能力有限,目前只能分析到这几步,采集每一项tag的具体东西还没做完善,后期的处理还需要更多新的东西支持,所涉及的东西很多自己也是初次接触采集app端的数据,appium模拟还没有接触,后期的appium自动化测试模拟人工完成一系列的操作还在学习摸索中。