今天看了一个斯坦福的讲Java基础的公开课,叫《编程方法学》的公开课,涉及到Java编程中的三大内存区域,觉得讲得挺好的,自己在这里重构一下知识点。
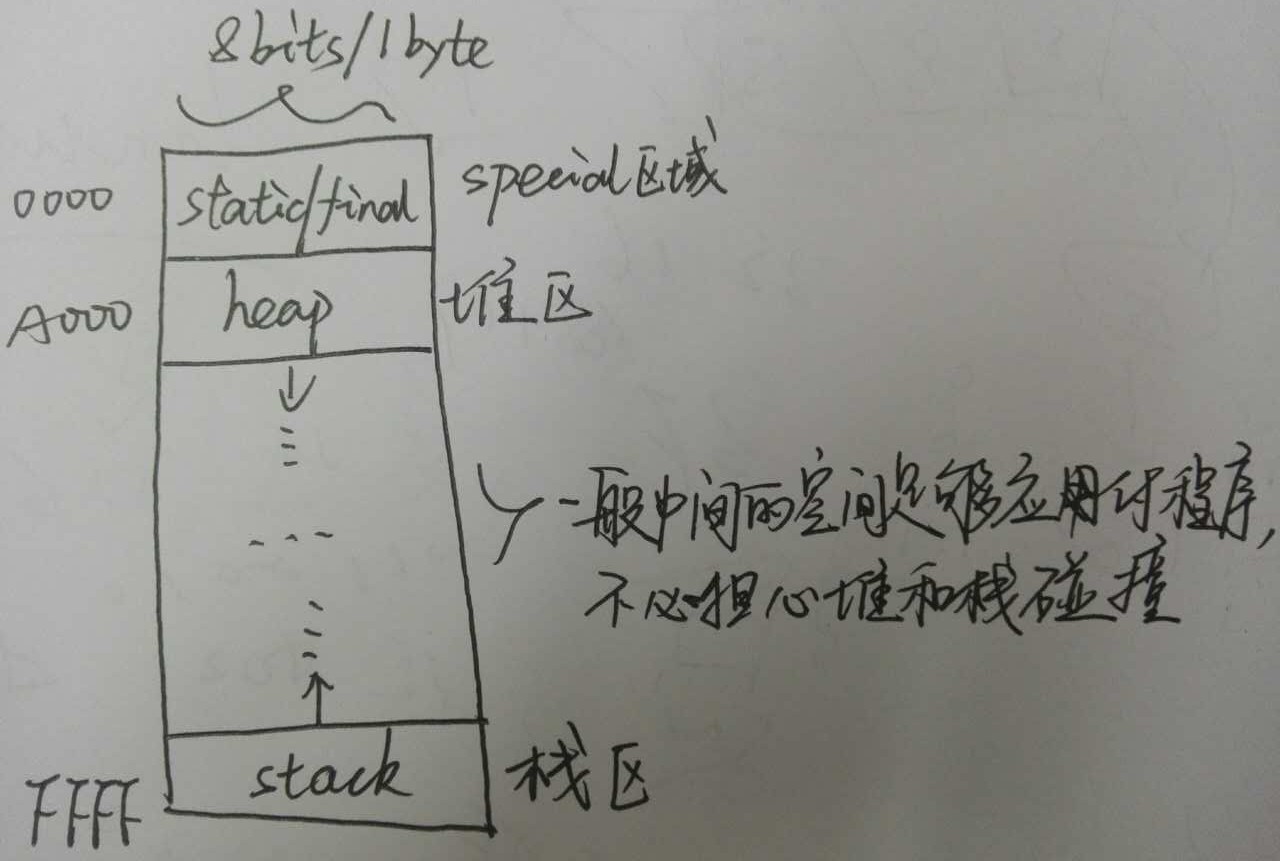
java编程中内存的三大区域:
1.存static/final常量的静态/常量存储区,姑且称它为special区域
2.heap堆区域:存放Dynamic Variable,如new创建出来的对象
3.stack栈区域:存放函数的参数,以及local variable
java虚拟机都会自动回收这些区域里面不再被使用的空间
(三大内存区域模型图)
栈是从上往下不断压栈,堆从上往下拓展。
下面简单说一下视频中讲到的一个例子:
public class Point{
private int px;
private int py;
Point(){
this.px = 0;
this.py = 0;
}
Point(int x, int y){
this.px = x;
this.py = y;
}
public void move(int x,int y){
this.px += x;
this.py += y;
}
public static void main(String[] args){
Point p1 = new Point(2,3);
Point p2 = new Point(4,5);
p1.move(1, 1);
}
}
我们从main函数里面的代码开始看起,首先p1和p2都是main函数作用域里面的两个局部变量,它们表示的是对象的引用。上面说到,局部变量存放在栈区,所以在栈区压栈给p1,p2分配空间,因为它们指向的是对象空间,所以空间里的值存放的是映射到实际对象空间的地址。然后程序new了两个Point对象,每个对象都需要分配三块区域:
一个是成员属性px,一个是成员属性py,还有一个是用于存放对象的其他信息(包括说由1000地址怎么获取到px的值等等)。然后构造函数会把这px和py空间里面的值初始化为响应的值。
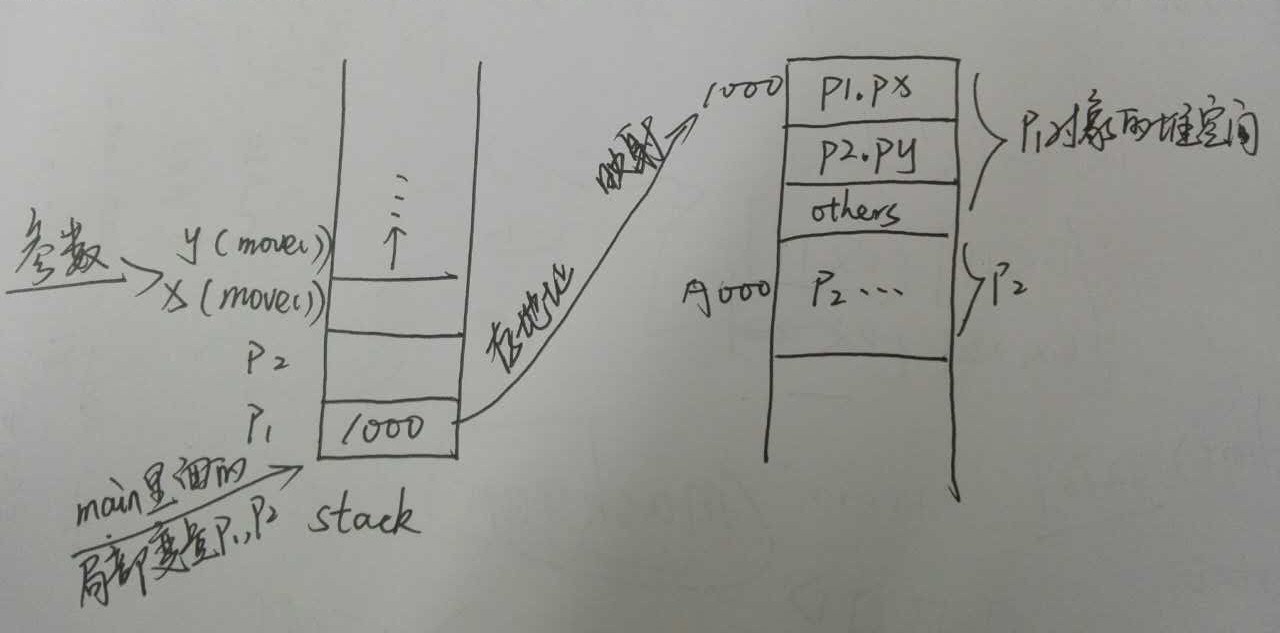
然后执行p1.move()函数,程序会首先保存当前上下文,然后跳转到响应的函数地址去执行代码。操作的是p1对象,先在栈区存放this指针的值(也就是指向p1对象堆空间的地址1000[其实是首地址,然后通过首地址和那个others区域可找到相应的属性]),然后函数有两个参数,同样在栈区存放着两个参数的值1、1。然后程序跳转到p1对象堆空间中去把px属性和py的属性值分别加1。函数执行结束,刚才执行函数时分配的栈区空间全部收回,通过出栈的方式从栈顶一个个清理空间,然后恢复上下文,继续执行往下代码……