1. 路由系统
URL配置(URLconf)就像Django所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表。
2. URLconf配置
1. 基本格式
from django.conf.urls import url
urlpatterns = [
# url() 是包含 请求的url和视图的对应关系的函数
# def url(regex, view, kwargs=None, name=None):
url(正则表达式, views视图,参数,别名),
]
9. 根据分组和方向解析合并删除
就是根据所学知识,将作者、书籍、出版社的删除函数由原来的3个函数写成1个函数
知识点:分组是说后端能捕获到url中括号中的内容
第一种方法
url(r'^all_del/(?P<pk>d+)/(?P<sc>w{0,20})/', views.all_del,name="all_del")
前端代码:
<a href="{% url 'all_del' pk=publish_obj.pk sc='publisher_list' %}">删除</a>
<a href="{% url 'all_del' pk=author_obj.pk sc='author_list' %}">删除</a>
<a href="{% url 'all_del' pk=book_obj.pk sc='book_list' %}">删除</a>
后端代码:
def all_del(request,**kwargs):
pk = int(kwargs["pk"])
sc = kwargs["sc"]
# print(kwargs)
# print(sc)
# print(pk)
ret = ""
if sc == "publisher_list":
ret = models.Publisher.objects.filter(pk=pk)
if not ret:
return HttpResponse("数据不存在1")
elif sc == "book_list":
ret = models.Book.objects.filter(pk=pk)
if not ret:
return HttpResponse("数据不存在2")
elif sc == "author_list":
ret = models.Author.objects.filter(pk=pk)
if not ret:
return HttpResponse("数据不存在3")
ret.delete()
return redirect(sc) # 自动反向解析
第二种方法
url(r'^(publisher|book|author)_del/(d+)/', views.delete,name="delete"),
# url(r'^(w+)_del/(d+)/', views.delete,name="delete"), # 效果相同
前端代码:
<a href="{% url 'delete' 'publisher' publish_obj.pk %}">删除</a>
<a href="{% url 'delete' 'author' author_obj.pk %}">删除</a>
<a href="{% url 'delete' 'book' book_obj.pk %}">删除</a>
# ****************************第三种也用上边代码*******************************
后端代码
def delete(request,name,pk,*args,**kwargs):
# 后端能捕获到url括号中的内容
print(name)
print(pk)
print(args)
print(kwargs)
# 字典形式*******************获取对象
dic = {"book":models.Book,
"publisher":models.Publisher,
'author':models.Author}
models_class = dic.get(name)
ret = models_class.objects.filter(pk=pk)
if not ret:
return HttpResponse("输入有误,不存在")
ret.delete()
return redirect(name+"_list")
第三种方法
反射形式 models相当于一个模块,外部导入的
"".capitalize() # app01.models模块中的属性(类名)都是首字母大写的
models_class = getattr(models,name.capitalize())
ret = models_class.objects.filter(pk=pk)
print(ret)
if not ret:
return HttpResponse("输入有误,不存在")
ret.delete()
return redirect(name+"_list")
拼接成展示页面的路径,也可以修改展示的别名为name相同
2. 示例 django 1.x
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003),
url(r'^articles/([0-9]{4})/$', views.year_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive),
url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail),
]
3. 参数说明
# regex正则表达式 : 一个正则表达式字符串
# views视图: 一个可以调用的对象(最终执行的还是view函数), 或者是一个函数
# kwargs参数: 需要传给视图的参数.以字典形式传递
# name 别名 : 给当前的函数起一个名字, 用于做反向解析
4. django 2.x
from django.urls import path,re_path
# 2.0版本中re_path和1.11版本的url是一样的用法
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug:slug>/', views.article_detail),
]
3. 正则表达式详解
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^articles/2003/$', views.special_case_2003),
url(r'^articles/([0-9]{4})/$', views.year_archive),
url(r'^articles/(d+)/(d{2})/$', views.month_archive),
# (d+) 至少一个数字,上不封顶,(d{2})只能2个数字
url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail),
]
# r"" 表示不转义
# ^XX 以XX开头 以...开头 注意没有/
# $XX 以XX结尾 以...结尾
# () 分组
# + 匹配1个或多个
下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。
# d+ 匹配一个或多个数字
# w+ 匹配数字字母下划线
# [0-9] 0-9数字任意一个
# [0-9a-zA-z] #大小写字母数字,任意一个.
# {3} # 3个
# {0,4} # 范围 0-4个
4. 补充说明
1. 访问时 404 DEBUG = True
DEBUG = True # 访问路径不存在时报出提示信息404
ALLOWED_HOSTS = []
# DEBUG = False 访问不存在路径,Not Found,无其他提示信息
# ALLOWED_HOSTS = ["*"]
2. 访问路径最后没有 /
当访问的路径没有 / 时,我们也能正常访问,并且访问补全了/,那是因为做了重定向
先访问login 在重定向login/
访问 http://www.example.com/blog 时,默认将网址自动转换为 http://www.example/com/blog/ 。
APPEND_SLASH = True, 其作用就是自动在网址结尾加'/'。
如果在settings.py中设置了 APPEND_SLASH=False,此时我们再请求 http://www.example.com/blog 时就会提示找不到页面。
5. 分组命名匹配
1. 有名分组和无名分组
from app01 import views
urlpatterns = [
url(r'^index/',views.index)
url(r'^index/(d+)/(d+)/',views.index),无名分组,分组数据以位置传参的方式给了视图函数
url(r'^index/(?P<xx>d+)/(?P<oo>d+)/',views.index),有名分组,分组数据以关键字传参的方式给了视图函数,不在乎参数位置了,并且视图函数形参的名称要和又名分组的变量名称一样.
]
views.py
def index(request,n,m): # 无名分组,位置传参
return HttpResponse('xx')
def index(request,xx,oo): # 有名分组,关键字传参
return HttpResponse('xx')
2. 视图函数中指定默认值
# urls.py中
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^blog/$', views.page), # 没有传num也能访问
url(r'^blog/page(?P<num>[0-9]+)/$', views.page),
]
# views.py中,可以为num指定默认值. 接收num不存在时,使用默认值
def page(request, num="1"):
pass
3. 捕获的参数永远都是字符串
每个在URLconf中捕获的参数都作为一个普通的Python字符串传递给视图,无论正则表达式使用的是什么匹配方式。例如,下面这行URLconf 中:
url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive), # year 参数 始终是一个字符串
4. URLconf匹配的位置
URLconf 在请求的URL上查找,将它当做一个普通的Python字符串。不包括GET和POST参数以及域名。
例如,http://www.example.com/myapp/ 请求中,URLconf 将查找 /myapp/ 。
在http://www.example.com/myapp/?page=3 请求中,URLconf 仍将查找 /myapp/ 。
URLconf 不检查请求的方法。换句话讲,所有的请求方法 —— 同一个URL的`POST`、`GET`、`HEAD`等等 —— 都将路由到相同的函数。
5. 传递额外的参数给视图函数(了解)
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'^blog/(?P<year>[0-9]{4})/$', views.year_archive, {'foo': 'bar'}),
]
在这个例子中,对于/blog/2005/请求,Django 将调用views.year_archive(request, year='2005', foo='bar')。
当传递额外参数的字典中的参数和URL中捕获值的命名关键字参数同名时,函数调用时将使用的是字典中的参数,而不是URL中捕获的参数。
6. 路由分发 include
多个App应用时,为了避免混淆修改错误问题,引入路由分发
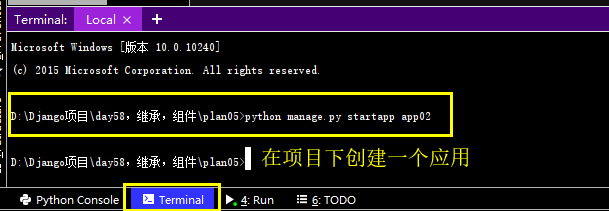
1. 创建新应用
python manage.py startapp app02
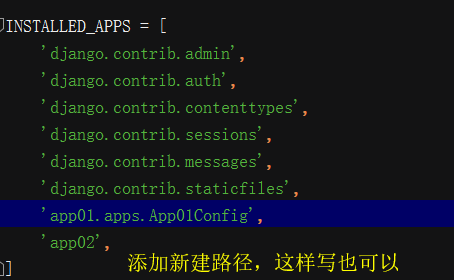
2. 注册app02
3. include 路由分发
from django.conf.urls import url,include # 引入include
from django.contrib import admin
urlpatterns = [
# url(r'^admin/', admin.site.urls),
#凡是以app01开头的去app01文件去找
url(r'^app01/', include("app01.urls")),
#凡是以app02开头的去app02文件去找
url(r'^app02/', include("app02.urls")),
]
# 例如,访问 http://127.0.0.1:8000/app01/home/,我们先找到app01/,然后根据include去app01应用下查找路径home/匹配
4. app01下创建urls文件
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^home/', views.home),]
app01下views文件代码
from django.shortcuts import render,HttpResponse
from django.urls import reverse
def home(request):
print("app01>>>",reverse("home")) # reverse解析时出错,命名空间解决,覆盖现象
return HttpResponse("app01下的路径")
5. app02下创建urls文件
from django.conf.urls import url
from app02 import views
urlpatterns = [
url(r'^home/', views.home),]
app02下views文件代码
from django.shortcuts import render,HttpResponse
from django.urls import reverse
def home(request):
print("app02>>>", reverse("home")) # reverse解析时出错,命名空间解决,覆盖现象
return HttpResponse("app02下的路径")
以上代码存在一个错误,就是不同应用命名同一个别名,反向解析结果都是后一个的路径,这就用到了命名空间解决问题
7. url 别名和反向解析
写法
url(r'^index2/', views.index,name='index'),
反向解析
后端: from django.urls import reverse
reverse('别名') 例如:reverse('index') -- /index2/
html: {% url '别名' %} -- 例如:{% url 'index' %} -- /index2/
1. urls文件起别名
urlpatterns = [
# url(r'^admin/', admin.site.urls),
#url(r'^index/', views.index), ---------------改名前
#url(r'^login/', views.login), ---------------改名前
url(r'^index2/', views.index,name="index"), ------改名后
url(r'^login2/', views.login,name="login"), ------改名后
]
2. views文件中改名方法
reverse("别名")-----路径
from django.shortcuts import render,redirect,HttpResponse
from django.urls import reverse # 引入reverse方法
def index(request):
return render(request,"index.html")
def login(request):
if request.method == "GET":
print(reverse("index"))
print(reverse("login"))
return render(request,"login.html")
else:
name = request.POST.get("username")
pwd = request.POST.get("password")
if name == "Alex" and pwd == "123":
# return redirect("/index2/")---可以
# return redirect("index")--用别名也可以,redirect方法源码做了反向解析了
return redirect(reverse("index")) ---此处改变也可以
else:
return HttpResponse("用户名或密码错误!!")
# return redirect("/login/")
3. html文件改名方法
{% url '别名' %} --- 改路径
<h1>红浪漫spa会所</h1>
<img src="/static/img/1.webp.jpg" alt="">
{# <a href="/login2/">登录页</a>#} --改名前路径
<a href="{% url 'login' %}">登录页</a> --改名后写法
8. 命名空间 namespace
上述代码解决方法
项目下urls文件添加 namespace属性
urlpatterns = [
# url(r'^admin/', admin.site.urls),
#凡是以app01开头的去app01文件去找
url(r'^app01/', include("app01.urls",namespace="app01")),
#凡是以app02开头的去app02文件去找
url(r'^app02/', include("app02.urls",namespace="app02")),]
reverse("app01:home") reverse("app02:home")
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^app01/', include('app01.urls',namespace='app01')),
url(r'^app02/', include('app02.urls',namespace='app02')),]
使用:
后端:reverse('命名空间名称:别名') -- reverse('app01:home')
hmtl:{% url '命名空间名称:别名' %} -- {% url 'app01:home' %}
9. 根据分组和方向解析合并删除
*args获取无名分组
**kwargs获取有名分组
就是根据所学知识,将作者、书籍、出版社的删除函数由原来的3个函数写成1个函数
知识点:分组是说后端能捕获到url中括号中的内容
第一种方法
url(r'^all_del/(?P<pk>d+)/(?P<sc>w{0,20})/', views.all_del,name="all_del")
前端代码:
<a href="{% url 'all_del' pk=publish_obj.pk sc='publisher_list' %}">删除</a>
<a href="{% url 'all_del' pk=author_obj.pk sc='author_list' %}">删除</a>
<a href="{% url 'all_del' pk=book_obj.pk sc='book_list' %}">删除</a>
后端代码:
def all_del(request,**kwargs):
pk = int(kwargs["pk"])
sc = kwargs["sc"]
# print(kwargs)
# print(sc)
# print(pk)
ret = ""
if sc == "publisher_list":
ret = models.Publisher.objects.filter(pk=pk)
if not ret:
return HttpResponse("数据不存在1")
elif sc == "book_list":
ret = models.Book.objects.filter(pk=pk)
if not ret:
return HttpResponse("数据不存在2")
elif sc == "author_list":
ret = models.Author.objects.filter(pk=pk)
if not ret:
return HttpResponse("数据不存在3")
ret.delete()
return redirect(sc) # 自动反向解析
第二种方法
url(r'^(publisher|book|author)_del/(d+)/', views.delete,name="delete"),
# url(r'^(w+)_del/(d+)/', views.delete,name="delete"), # 效果相同
前端代码:
<a href="{% url 'delete' 'publisher' publish_obj.pk %}">删除</a>
<a href="{% url 'delete' 'author' author_obj.pk %}">删除</a>
<a href="{% url 'delete' 'book' book_obj.pk %}">删除</a>
# ****************************第三种也用上边代码*******************************
后端代码
def delete(request,name,pk,*args,**kwargs):
# 后端能捕获到url括号中的内容
print(name)
print(pk)
print(args)
print(kwargs)
# 字典形式*******************获取对象
dic = {"book":models.Book,
"publisher":models.Publisher,
'author':models.Author}
models_class = dic.get(name)
ret = models_class.objects.filter(pk=pk)
if not ret:
return HttpResponse("输入有误,不存在")
ret.delete()
return redirect(name+"_list")
第三种方法
反射形式 models相当于一个模块,外部导入的
"".capitalize() # app01.models模块中的属性(类名)都是首字母大写的
models_class = getattr(models,name.capitalize())
ret = models_class.objects.filter(pk=pk)
print(ret)
if not ret:
return HttpResponse("输入有误,不存在")
ret.delete()
return redirect(name+"_list")
拼接成展示页面的路径,也可以修改展示的别名为name相同