Mycat 简介
Mycat 是一个实现了 MySQL 协议的 Server,前端用户可以把它看作是一个数据库代理,用 MySQL 客
户端工具和命令行访问,而其后端可以用 MySQL 原生协议或JDBC 协议与多个 MySQL 服务器通信,
其核心功能是分库分表和读写分离,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里
或者其他数据库里。
-
对于 DBA 来说,可以这么理解 Mycat
Mycat 就是 MySQL Server,但是Mycat 本身并不存储数据,数据是在后端的 MySQL 上存储的,
因此数据可靠性以及事务等都是 MySQL 保证的。简单的说,Mycat 就是 MySQL 最佳伴侣。 -
对于软件工程师来说,可以这么理解 Mycat
Mycat 就是一个近似等于 MySQL 的数据库服务器,你可以用连接 MySQL 的方式去连接
Mycat(除了端 口不同,默认的 Mycat 端口是 8066 而非 MySQL 的 3306,因此需要在连接字符
串上增加端口信息),大多数 情况下,可以用你熟悉的对象映射框架使用 Mycat,但建议对于分
片表,尽量使用基础的 SQL 语句,因为这样能 达到最佳性能,特别是几千万甚至几百亿条记录的
情况下。 -
对于架构师来说,可以这么理解 Mycat
Mycat 是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分表分库、容灾备份,而且
可以用于多 用户应用开发、云平台基础设施、让你的架构具备很强的适应性和灵活性,借助于即
将发布的 Mycat 智能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,
你可以自动或手工调整后端存储,将不同的 表映射到不同存储引擎上,而整个应用的代码一行也
不用改变。
Mycat 核心概念
逻辑库
对数据进行分片处理之后,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成了
整个完整的数据库存储。Mycat在操作时,使用逻辑库来代表这个完整的数据库集群,便于对整个集群
操作。
逻辑表
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。
分片表
分片表,是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数
据,所 有分片构成了完整的数据。例如在 mycat 配置中的 t_node 就属于分片表,数据按照规则被分
到 dn1,dn2 两个分片节点上。
<table name="t_node" primaryKey="vid" autoIncrement="true" dataNode="dn1,dn2"
rule="rule1" />
非分片表
一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就
是那些不需要进行数据切分的表。如下配置中 t_node,只存在于分片节点dn1上。
<table name="t_node" primaryKey="vid" autoIncrement="true" dataNode="dn1" />
ER表
Mycat提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片
上,即子表依赖于父表,通过表分组(Table Group)保证数据 join 不会跨库操作。表分组(Table Group)
是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
全局表
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几
个特性:
-
变动不频繁;
-
数据量总体变化不大;
-
数据规模不大,很少有超过数十万条记录。
对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间
的关联,就成了比较棘手的问题,所以 Mycat 中通过数据冗余来解决这类表的 join,即所有的分片都有
一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。数据冗余是解决跨分片数
据 join 的一种很好的思路,也是数据切分规划的另外一条重要规则。
分片节点
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点
dataNode。
节点主机
数据切分后,每个分片节点不一定都会独占一台机器,同一机器上面可以有多个分片数据库, 这样一个
或多个分片节点所在的机器就是节点主机,为了规避单节点主机并发数限制, 尽量将读写压力高的分片
节点均衡的放在不同的节点主机dataHost。
分片规则
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则rule,这样按照某种业务规则把
数据分到 某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数
据处理的难度。
server.xml配置
server.xml几乎保存了所有 mycat 需要的系统配置信息。
user标签
这个标签主要用于定义登录 mycat 的用户和权限。例如下面的例子中,我们定义了一个用户,用户名
为 user、密码也为 user,可访问的 schema为lg_edu_order。
<user name="user">
<property name="password">user</property>
<property name="schemas">lg_edu_order</property>
<property name="readOnly">true</property>
<property name="defaultSchema">lg_edu_order</property>
</user>
firewall标签
<firewall>
<!-- ip白名单 用户对应的可以访问的 ip 地址 -->
<whitehost>
<host host="127.0.0.*" user="root"/>
<host host="127.0.*" user="root"/>
<host host="127.*" user="root"/>
<host host="1*7.*" user="root"/>
</whitehost>
<!-- 黑名单允许的 权限 后面为默认 -->
<blacklist check="true">
<property name="selelctAllow">false</property>
<property name="selelctIntoAllow">false</property>
<property name="updateAllow">false</property>
<property name="insertAllow">false</property>
<property name="deletetAllow">false</property>
<property name="dropAllow">false</property>
</blacklist>
</firewall>
全局序列号
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,Mycat 提供了全局
sequence,并且提供了包含本地配置和数据库配置等多种实现方式。
<system>
<property name="sequnceHandlerType">0</property>
</system>
0表示使用本地文件方式;1表示使用数据库方式生成;2表示使用本地时间戳方式;3表示基于ZK与本
地配置的分布式ID生成器;4表示使用zookeeper递增方式生成
本地文件
此方式 Mycat 将 sequence 配置到文件中,当使用到 sequence 中的配置后,Mycat 会更下 classpath
中的 sequence_conf.properties 文件中 sequence 当前的值。
#default global sequence
GLOBAL.HISIDS=
GLOBAL.MINID=10001
GLOBAL.MAXID=20000
GLOBAL.CURID=10000
# self define sequence
COMPANY.HISIDS=
COMPANY.MINID=1001
COMPANY.MAXID=2000
COMPANY.CURID=1000
ORDER.HISIDS=
ORDER.MINID=1001
ORDER.MAXID=2000
ORDER.CURID=1000
数据库方式
在数据库中建立一张表,存放 sequence 名称(name),sequence 当前值(current_value),步长
(increment) 等信息。
CREATE TABLE MYCAT_SEQUENCE
(
name VARCHAR(64) NOT NULL,
current_value BIGINT(20) NOT NULL,
increment INT NOT NULL DEFAULT 1,
PRIMARY KEY (name)
) ENGINE = InnoDB;
本地时间戳方式
ID为64 位二进制 ,42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加)
换算成十进制为 18 位数的 long 类型,每毫秒可以并发 12 位二进制的累加。
在 Mycat 下配置sequence_time_conf.properties文件
WORKID=0-31 任意整数
DATAACENTERID=0-31 任意整数
每个Mycat 配置的 WORKID、DATAACENTERID 不同,组成唯一标识,总共支持32*32=1024 种组合。
分布式 ZK ID 生成器
Zk 的连接信息统一在 myid.properties 的 zkURL 属性中配置。基于 ZK 与本地配置的分布式 ID 生成
器,InstanceID可以通过ZK自动获取,也可以通过配置文件配置。在
sequence_distributed_conf.properties,只要配置INSTANCEID=ZK就表示从 ZK 上获取 InstanceID。
ID 最大为63位二进制,可以承受单机房单机器单线程 1000*(2^6)=640000 的并发。结构如下
-
current time millis(微秒时间戳 38 位,可以使用 17 年)
-
clusterId(机房或者 ZKid,通过配置文件配置,5 位)
-
instanceId(实例 ID,可以通过 ZK 或者配置文件获取,5 位)
-
threadId(线程 ID,9 位)
-
increment(自增,6 位)
ZK 递增方式
Zk 的连接信息统一在 myid.properties 的 zkURL 属性中配置。需要配置sequence_conf.properties文
件
-
TABLE.MINID 某线程当前区间内最小值
-
TABLE.MAXID 某线程当前区间内最大值
-
TABLE.CURID 某线程当前区间内当前值
schema.xml配置
schema.xml 作为 Mycat 中重要的配置文件之一,管理着 Mycat 的逻辑库、表、分片节点、主机等信
息。
schema标签
schema 标签用于定义 Mycat 实例中的逻辑库,Mycat 可以有多个逻辑库,每个逻辑库都有自己的相关
配 置。可以使用 schema 标签来划分这些不同的逻辑库。
<!-- 逻辑库 -->
<schema name="lg_edu_order" checkSQLschema="true" sqlMaxLimit="100"
dataNode="dn1"></schema>
| 属性名 | 值 | 数量限制 | 说明 |
|---|---|---|---|
| dataNode | 任意String | (0..1) | 分片节点 |
| sqlMaxLimit | Integer | (1) | 查询返回的记录数限制limit |
| checkSQLschema | Boolean | (1) | 是否去表库名 |
table标签
table标签定义了 Mycat 中的逻辑表,所有需要拆分的表都需要在这个标签中定义
<table name="b_order" dataNode="dn1,dn2" rule="b_order_rule" primaryKey="ID"
autoIncrement="true"/>
| 属性 | 值 | 数量限制 | 说明 |
|---|---|---|---|
| name | String | (1) | 逻辑表名 |
| dataNode | String | (1..*) | 分片节点 |
| rule | String | (0..1) | 分片规则 |
| ruleRequired | Boolean | (0..1) | 是否强制绑定分片规则 |
| primaryKey | String | (1) | 主键 |
| type | String | (0..1) | 逻辑表类型,全局表、普通表 |
| autoIncrement | Boolean | (0..1) | 自增长主键 |
| subTables | String | (1) | 分表 |
| needAddLimit | Boolean | (0..1) | 是否为查询SQL自动加limit限制 |
dataNode标签
dataNode标签定义了 MyCat 中的分片节点,也就是我们通常说所的数据分片。
<!-- 数据节点 -->
<dataNode name="dn1" dataHost="lg_edu_order_1" database="lg_edu_order_1" />
name: 定义数据节点的名字,这个名字需要是唯一的,我们需要在 table 标签上应用这个名字,来建
立表与分片对应的关系。
dataHost : 用于定义该分片属于哪个分片主机,属性值是引用 dataHost 标签上定义的 name 属性。
database: 用于定义该分片节点属于哪个具体的库。
dataHost标签
dataHost标签在 Mycat 逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分
离配置和心跳语句
<dataHost name="lg_edu_order_1" maxCon="100" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
</dataHost>
| 属性 | 值 | 数量限制 | 说明 |
|---|---|---|---|
| name | String | (1) | 节点主机名 |
| maxCon | Integer | (1) | 最大连接数 |
| minCon | Integer | (1) | 最小连接数 |
| balance | Integer | (1) | 读操作负载均衡类型 |
| writeType | Integer | (1) | 写操作负载均衡类型 |
| dbType | String | (1) | 数据库类型 |
| dbDriver | String | (1) | 数据库驱动 |
| switchType | String | (1) | 主从切换类型 |
heartbeat标签
heartbeat标签内指明用于和后端数据库进行心跳检查的语句。例如:MySQL 可以使用 select user()、
Oracle 可以 使用 select 1 from dual 等
<dataHost>
<heartbeat>select user()</heartbeat>
</dataHost>
writeHost和readHost标签
writeHost和readHost标签都指定后端数据库的相关配置给 mycat,用于实例化后端连接池。唯一不同
的是,writeHost 指定写实例、readHost 指定读实例。在一个 dataHost 内可以定义多个 writeHost 和
readHost。但是,如果 writeHost 指定的后端数据库宕机, 那么这个 writeHost 绑定的所有 readHost
都将不可用。另一方面,由于这个 writeHost 宕机系统会自动的检测 到,并切换到备用的 writeHost
上去。
<dataHost name="lg_edu_order_2" maxCon="100" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="M1" url="192.168.95.133:3306" user="root" password="1234">
</writeHost>
</dataHost>
| 属性 | 值 | 数量限制 | 说明 |
|---|---|---|---|
| host | String | (1) | 主机名 |
| url | String | (1) | 连接字符串 |
| password | String | (1) | 密码 |
| user | String | (1) | 用户名 |
| weight | String | (1) | 权重 |
| usingDecrypt | String | (1) | 是否对密码加密,默认0 |
rule.xml配置
rule.xml用于定义Mycat的分片规则
tableRule标签
<tableRule name="c_order_rule">
<rule>
<columns>user_id</columns>
<algorithm>partitionByOrderFunc</algorithm>
</rule>
</tableRule>
name:指定唯一的名字,用于标识不同的表规则。
columns:指定要拆分的列名字。
algorithm:使用 function 标签中的 name 属性,连接表规则和具体路由算法。
function标签
<function name="partitionByOrderFunc"
class="io.mycat.route.function.PartitionByMod">
<property name="count">2</property>
</function>
name:指定算法的名字。
class:制定路由算法具体的类名字。
property: 为具体算法需要用到的一些属性。
Mycat实战
Mycat安装
提示:需要先安装jdk
-
下载Mycat-server工具包
-
解压Mycat工具包
tar -zxvf Mycat-server-1.6.7.5-release-20200410174409-linux.tar.gz -
进入mycat/bin,启动Mycat
启动命令:./mycat start
停止命令:./mycat stop
重启命令:./mycat restart
查看状态:./mycat status
- 访问Mycat
mysql -uroot -proot -h127.0.0.1 -P8066
分库分表
在rule.xml配置Mycat分库分表。
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="b_order_rule">
<rule>
<columns>company_id</columns>
<algorithm>partitionByOrderFunc</algorithm>
</rule>
</tableRule>
<!-- 路由函数定义 -->
<function name="partitionByOrderFunc"
class="io.mycat.route.function.PartitionByMod">
<property name="count">2</property>
</function>
</mycat:rule>
Mycat常用分片规则如下:
-
时间类:按天分片、自然月分片、单月小时分片
-
哈希类:Hash固定分片、日期范围Hash分片、截取数字Hash求模范围分片、截取数字Hash分
片、一致性Hash分片 -
取模类:取模分片、取模范围分片、范围求模分片
-
其他类:枚举分片、范围约定分片、应用指定分片、冷热数据分片
Mycat常用分片配置示例:
- 自动分片
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
autopartition-long.txt文件内容如下:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
枚举分片
把数据分类存储。
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<!-- 找不到分片时设置容错规则,把数据插入到默认分片0里面 -->
<property name="defaultNode">0</property>
</function>
partition-hash-int.txt文件内容如下:
10000=0
10010=1
取模分片
根据分片字段值 % 分片数 。
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!--分片数 -->
<property name="count">3</property>
</function>
冷热数据分片
根据日期查询日志数据冷热数据分布 ,最近 n 个月的到实时交易库查询,超过 n 个月的按照 m 天
分片。
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-hotdate</algorithm>
</rule>
</tableRule>
<function name="sharding-by-hotdate"
class="org.opencloudb.route.function.PartitionByHotDate">
<!-- 定义日期格式 -->
<property name="dateFormat">yyyy-MM-dd</property>
<!-- 热库存储多少天数据 -->
<property name="sLastDay">30</property>
<!-- 超过热库期限的数据按照多少天来分片 -->
<property name="sPartionDay">30</property>
</function>
一致性哈希分片
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否
则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点
被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,
没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就
是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的
murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何
东西 -->
</function>
读写分离
在schema.xml文件中配置Mycat读写分离。使用前需要搭建MySQL主从架构,并实现主从复制,
Mycat不负数据同步问题。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0"
dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="localhost:3306" user="root" password="123456">
<readHost host="S1" url="localhost:3307" user="root" password="123456"
weight="1" />
</writeHost>
</dataHost>
balance参数:
0 : 所有读操作都发送到当前可用的writeHost
1 :所有读操作都随机发送到readHost和stand by writeHost
2 :所有读操作都随机发送到writeHost和readHost
3 :所有读操作都随机发送到writeHost对应的readHost上,但是writeHost不负担读压力
writeType参数:
0 : 所有写操作都发送到可用的writeHost
1 :所有写操作都随机发送到readHost
2 :所有写操作都随机发送到writeHost,readHost
或者
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0"
dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="localhost:3306" user="root" password="123456">
</writeHost>
<writeHost host="S1" url="localhost:3307" user="root" password="123456">
</writeHost>
</dataHost>
以上两种取模第一种当写挂了读不可用,第二种可以继续使用,事务内部的一切操作都会走写节点,所
以读操作不要加事务,如果读延时较大,使用根据主从延时切换的读写分离,或者强制走写节点
强制路由
一个查询 SQL 语句以/* !mycat * /注解来确定其是走读节点还是写节点。
/*! /
/# /
/* */
强制走从:
/*!mycat:db_type=slave*/ select * from travelrecord //有效
/*#mycat:db_type=slave*/ select * from travelrecord
强制走写:
/*!mycat:db_type=master*/ select * from travelrecord //有效
/*#mycat:db_type=slave*/ select * from travelrecord
1.6 以后Mycat除了支持db_type注解以外,还有其他注解,如下:
/*!mycat:sql=sql */ 指定真正执行的SQL
/*!mycat:schema=schema1 */ 指定走那个schema
/*!mycat:datanode=dn1 */ 指定sql要运行的节点
/*!mycat:catlet=io.mycat.catlets.ShareJoin */ 通过catlet支持跨分片复杂SQL实现以及存
储过程支持等
主从延时切换
switchType参数:
-1: 表示不自动切换
1 :表示自动切换
2 :基于MySQL主从同步状态决定是否切换
3 :基于MySQL cluster集群切换机制
1.4 开始支持 MySQL 主从复制状态绑定的读写分离机制,让读更加安全可靠,配置如下:
MyCAT 心跳检查语句配置为 show slave status ,dataHost 上定义两个新属性: switchType="2" 与
slaveThreshold="100",此时意味着开启 MySQL 主从复制状态绑定的读写分离与切换机制,Mycat 心
跳机 制通过检测 show slave status 中的 "Seconds_Behind_Master", "Slave_IO_Running",
"Slave_SQL_Running" 三个字段来确定当前主从同步的状态以及 Seconds_Behind_Master 主从复制时
延, 当 Seconds_Behind_Master > slaveThreshold 时,读写分离筛选器会过滤掉此 Slave 机器,防止
读到很久之 前的旧数据,而当主节点宕机后,切换逻辑会检查 Slave 上的 Seconds_Behind_Master 是
否为 0,为 0 时则 表示主从同步,可以安全切换,否则不会切换。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0"
dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status </heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="localhost:3306" user="root" password="123456">
</writeHost>
<writeHost host="S1" url="localhost:3316" user="root"
</dataHost>
1.4.1 开始支持 MySQL 集群模式,让读更加安全可靠,配置如下: MyCAT 心跳检查语句配置为 show
status like ‘wsrep%’ ,dataHost 上定义两个新属性: switchType="3"
此时意味着开启 MySQL 集群复制状态状态绑定的读写分离与切换机制,Mycat 心跳机制通过检测集群
复制时延时,如果延时过大或者集群出现节点问题不会负载改节点。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0"
dbType="mysql" dbDriver="native" switchType="3" >
<heartbeat> show status like ‘wsrep%’</heartbeat>
<writeHost host="M1" url="localhost:3306" user="root"password="123456">
</writeHost>
<writeHost host="S1"url="localhost:3316"user="root"password="123456" >
</writeHost>
</dataHost>
Mycat事务
Mycat 数据库事务
Mycat 目前没有出来跨分片的事务强一致性支持,单库内部可以保证事务的完整性,如果跨库事务,
在执行的时候任何分片出错,可以保证所有分片回滚,但是一旦应用发起 commit 指令,无法保证所有
分片都成功,考虑到某个分片挂的可能性不大所以称为弱 XA。
XA 事务使用
Mycat 从 1.6.5 版本开始支持标准 XA 分布式事务,考虑到 MySQL 5.7 之前版本XA有bug,所以推荐最
佳搭配 XA 功能使用 MySQL 5.7 版本。
Mycat 实现 XA 标准分布式事务,Mycat 作为XA 事务协调者角色,即使事务过程中 Mycat 宕机挂掉,
由于 Mycat 会记录事务日志,所以 Mycat 恢复后会进行事务的恢复善后处理工作。考虑到分布式事务
的性能开销比较大,所以只推荐在全局表的事务以及其他一些对一致性要 求比较高的场景。
使用示例:
XA 操作说明
- XA 事务需要设置手动提交
set autocommit=0;
-
使用该命令开启 XA 事务
set xa=on; -
执行相应的 SQL 语句部分
insert into city(id,name,province) values(200,'chengdu','sichuan');update position set salary='300000' where id<5; -
提交或回滚事务
commit;
rollback;
保证Repeatable Read
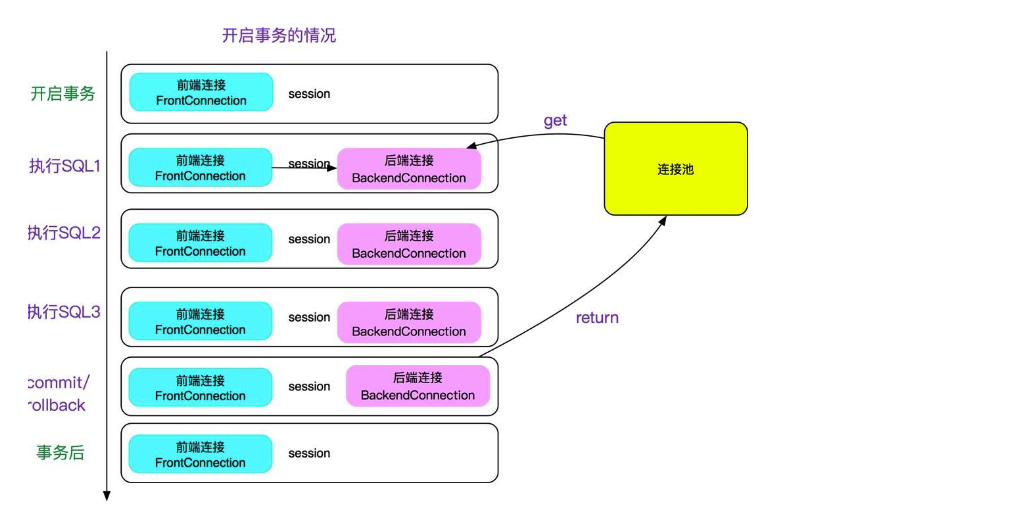
mycat 有一个特性,就是开事务之后,如果不运行 update/delete/select for update 等更新类语句
SQL 的话,不会将当前连接与当前 session 绑定。如下图所示:
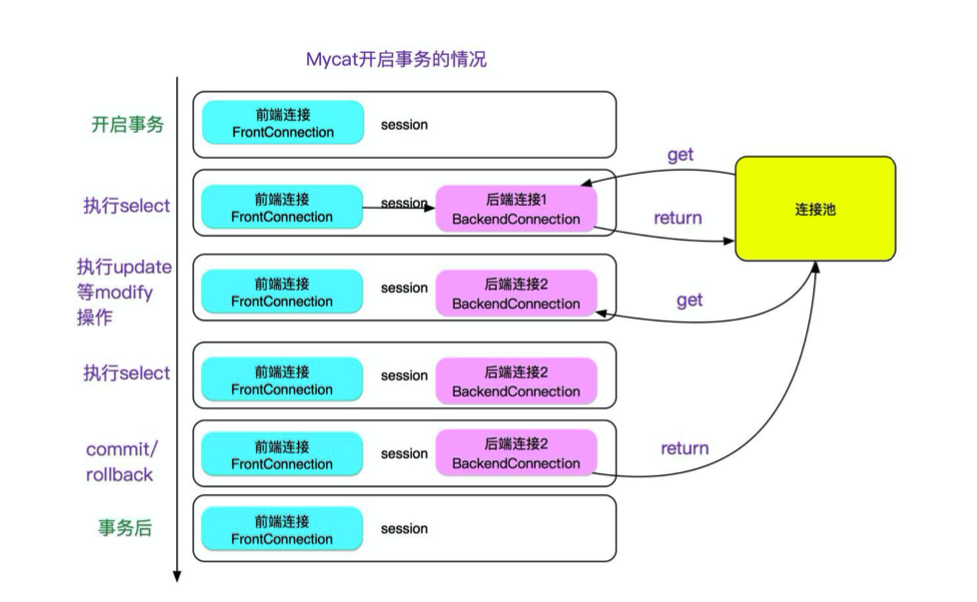
这样做的好处是可以保证连接可以最大限度的复用,提升性能。
但是,这就会导致两次 select 中如果有其它的在提交的话,会出现两次同样的 select 不一 致的现象,即不
能 Repeatable Read,这会让人直连 MySQL 的人很困惑,可能会在依赖 Repeatable Read 的场景出现
问题。所以做了一个开关,当 server.xml 的 system 配置了 strictTxIsolation=true 的时候,会关掉这个
特性,以保证 repeatable read,加了开关 后如下图所示: